 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal hidden monotonic trend estimation with contrastive learning
Oct 18, 2022


In this paper, we describe a universal method for extracting the underlying monotonic trend factor from time series data. We propose an approach related to the Mann-Kendall test, a standard monotonic trend detection method and call it contrastive trend estimation (CTE). We show that the CTE method identifies any hidden trend underlying temporal data while avoiding the standard assumptions used for monotonic trend identification. In particular, CTE can take any type of temporal data (vector, images, graphs, time series, etc.) as input. We finally illustrate the interest of our CTE method through several experiments on different types of data and problems.
Time Series Source Separation with Slow Flows
Jul 20, 2020

In this paper, we show that slow feature analysis (SFA), a common time series decomposition method, naturally fits into the flow-based models (FBM) framework, a type of invertible neural latent variable models. Building upon recent advances on blind source separation, we show that such a fit makes the time series decomposition identifiable.
Using Laplacian Spectrum as Graph Feature Representation
Dec 02, 2019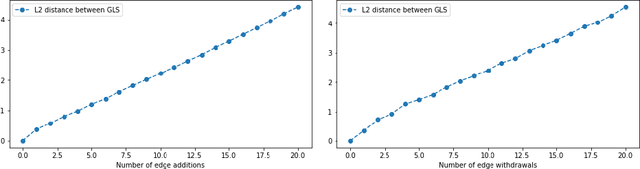
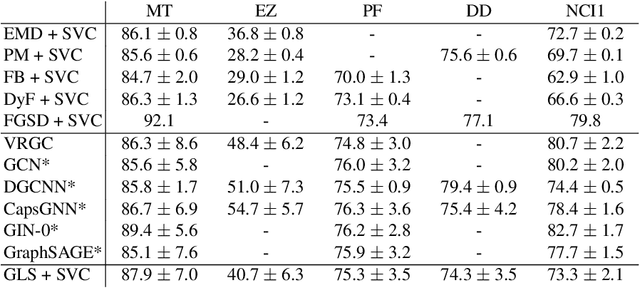
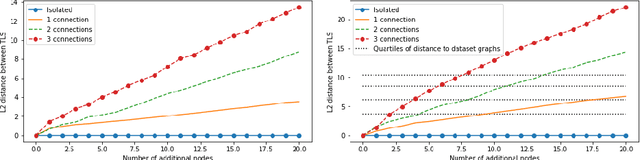

Graphs possess exotic features like variable size and absence of natural ordering of the nodes that make them difficult to analyze and compare. To circumvent this problem and learn on graphs, graph feature representation is required. A good graph representation must satisfy the preservation of structural information, with two particular key attributes: consistency under deformation and invariance under isomorphism. While state-of-the-art methods seek such properties with powerful graph neural-networks, we propose to leverage a simple graph feature: the graph Laplacian spectrum (GLS). We first remind and show that GLS satisfies the aforementioned key attributes, using a graph perturbation approach. In particular, we derive bounds for the distance between two GLS that are related to the \textit{divergence to isomorphism}, a standard computationally expensive graph divergence. We finally experiment GLS as graph representation through consistency tests and classification tasks, and show that it is a strong graph feature representation baseline.
Graph Classification with Recurrent Variational Neural Networks
Feb 14, 2019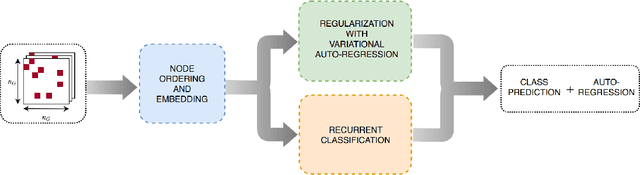
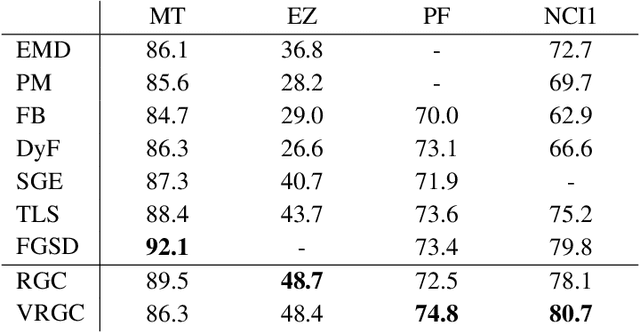
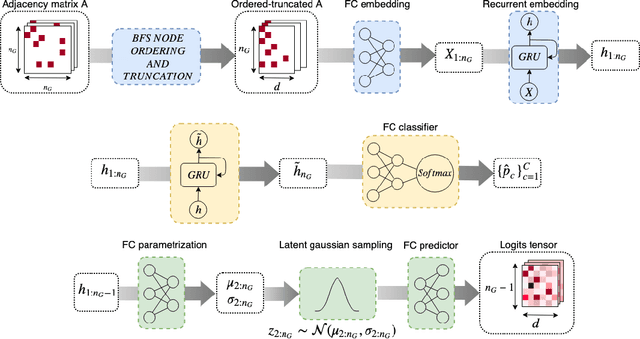
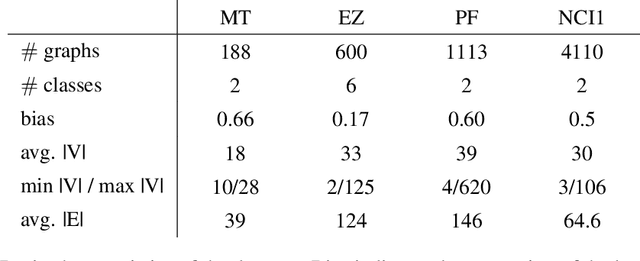
We address the problem of graph classification based only on structural information. Most standard methods require either the pairwise comparisons of all graphs in the dataset or the extraction of ad-hoc features to perform classification. Those methods respectively raise scalability issues when the number of samples in the dataset is large, and flexibility issues when discriminative information is characterized by exotic features. Recent advances in neural network architectures offer new possibilities for graph analysis in terms of scalability and feature learning. In this paper, we propose a new sequential approach using recurrent neural networks (RNN). Our model sequentially embeds information allowing to model final class membership probabilities. We also propose a regularization based on variational node prediction ending up with better learning and generalization. We experimentally show that our model reaches state-of-the-art classification results on several common molecular datasets. Finally, we perform a qualitative analysis and give some insights about how the joint node prediction helps the model to better classify graphs.
A Simple Baseline Algorithm for Graph Classification
Oct 22, 2018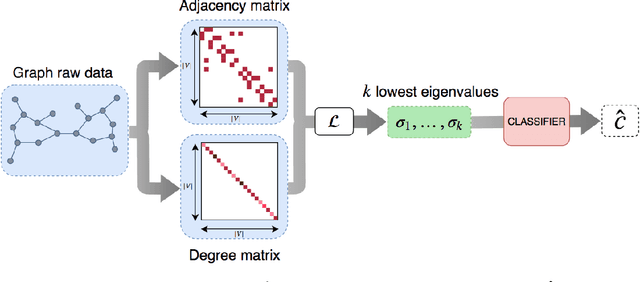
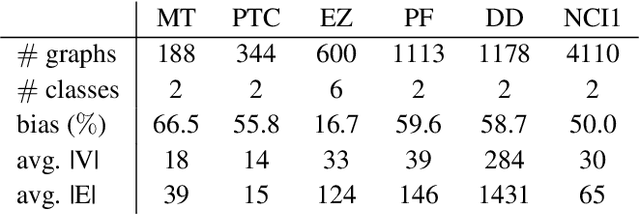
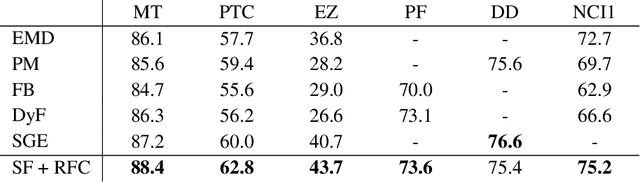
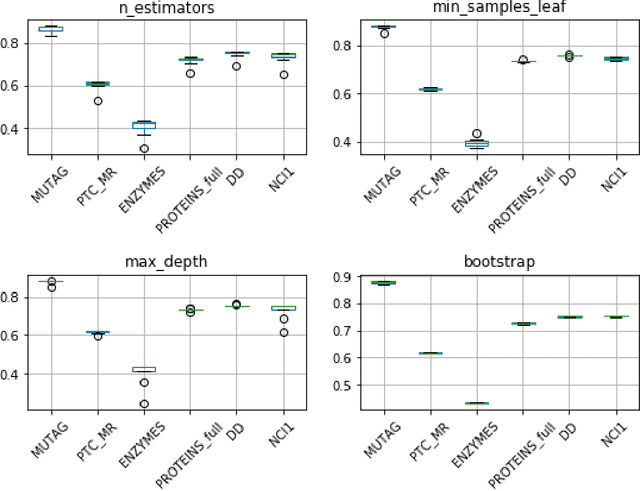
Graph classification has recently received a lot of attention from various fields of machine learning e.g. kernel methods, sequential modeling or graph embedding. All these approaches offer promising results with different respective strengths and weaknesses. However, most of them rely on complex mathematics and require heavy computational power to achieve their best performance. We propose a simple and fast algorithm based on the spectral decomposition of graph Laplacian to perform graph classification and get a first reference score for a dataset. We show that this method obtains competitive results compared to state-of-the-art algorithms.
InfoCatVAE: Representation Learning with Categorical Variational Autoencoders
Jun 25, 2018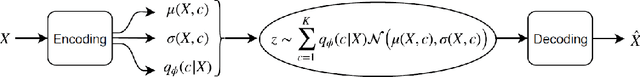
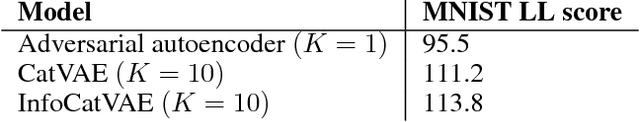


This paper describes InfoCatVAE, an extension of the variational autoencoder that enables unsupervised disentangled representation learning. InfoCatVAE uses multimodal distributions for the prior and the inference network and then maximizes the evidence lower bound objective (ELBO). We connect the new ELBO derived for our model with a natural soft clustering objective which explains the robustness of our approach. We then adapt the InfoGANs method to our setting in order to maximize the mutual information between the categorical code and the generated inputs and obtain an improved model.