 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKNNs of Semantic Encodings for Rating Prediction
Feb 01, 2023



This paper explores a novel application of textual semantic similarity to user-preference representation for rating prediction. The approach represents a user's preferences as a graph of textual snippets from review text, where the edges are defined by semantic similarity. This textual, memory-based approach to rating prediction enables review-based explanations for recommendations. The method is evaluated quantitatively, highlighting that leveraging text in this way outperforms both strong memory-based and model-based collaborative filtering baselines.
Syntax-guided Controlled Generation of Paraphrases
May 18, 2020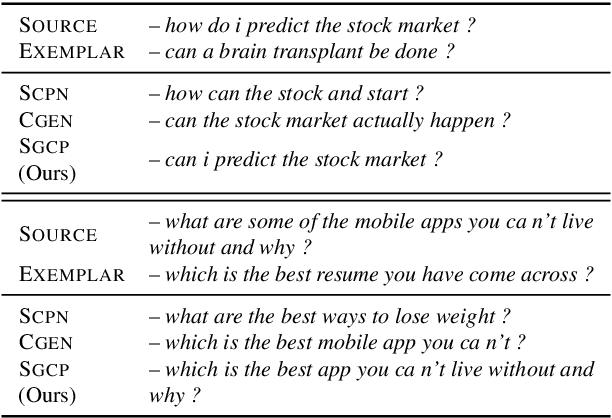


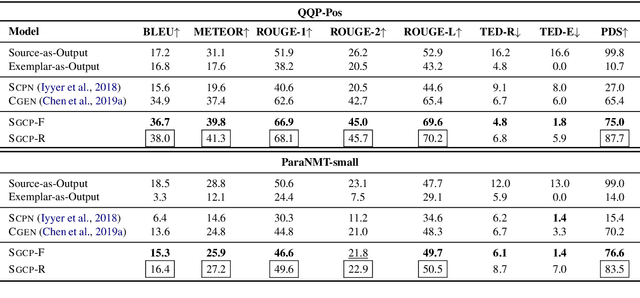
Given a sentence (e.g., "I like mangoes") and a constraint (e.g., sentiment flip), the goal of controlled text generation is to produce a sentence that adapts the input sentence to meet the requirements of the constraint (e.g., "I hate mangoes"). Going beyond such simple constraints, recent works have started exploring the incorporation of complex syntactic-guidance as constraints in the task of controlled paraphrase generation. In these methods, syntactic-guidance is sourced from a separate exemplar sentence. However, these prior works have only utilized limited syntactic information available in the parse tree of the exemplar sentence. We address this limitation in the paper and propose Syntax Guided Controlled Paraphraser (SGCP), an end-to-end framework for syntactic paraphrase generation. We find that SGCP can generate syntax conforming sentences while not compromising on relevance. We perform extensive automated and human evaluations over multiple real-world English language datasets to demonstrate the efficacy of SGCP over state-of-the-art baselines. To drive future research, we have made SGCP's source code available