 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring Strictly Proper Scoring Rules for Downstream Tasks: An Application to Causal Inference
Jun 02, 2026Probabilistic models are typically trained using task-agnostic objectives like log-loss, which can lead to significant errors in downstream estimation. This disconnect is especially critical in Inverse Probability Weighting (IPW) for causal inference, where propensity score errors near $0$ and $1$ often lead to high bias and variance. We propose a principled framework for deriving task-specific strictly proper scoring rules by matching the local curvature of the downstream error metric. We apply this to the Average Treatment Effect (ATE) estimation, deriving a closed-form loss and its corresponding canonical probability mapping that can be readily integrated with any model like a neural network or a gradient boosting algorithm. Extensive evaluations on causal inference benchmarks demonstrate that our tailored objective consistently outperforms standard likelihood-based and covariate-balancing approaches.
Nonlinear Concept Erasure: a Density Matching Approach
Jul 16, 2025Ensuring that neural models used in real-world applications cannot infer sensitive information, such as demographic attributes like gender or race, from text representations is a critical challenge when fairness is a concern. We address this issue through concept erasure, a process that removes information related to a specific concept from distributed representations while preserving as much of the remaining semantic information as possible. Our approach involves learning an orthogonal projection in the embedding space, designed to make the class-conditional feature distributions of the discrete concept to erase indistinguishable after projection. By adjusting the rank of the projector, we control the extent of information removal, while its orthogonality ensures strict preservation of the local structure of the embeddings. Our method, termed $\overline{\mathrm{L}}$EOPARD, achieves state-of-the-art performance in nonlinear erasure of a discrete attribute on classic natural language processing benchmarks. Furthermore, we demonstrate that $\overline{\mathrm{L}}$EOPARD effectively mitigates bias in deep nonlinear classifiers, thereby promoting fairness.
Revisiting Hierarchical Text Classification: Inference and Metrics
Oct 02, 2024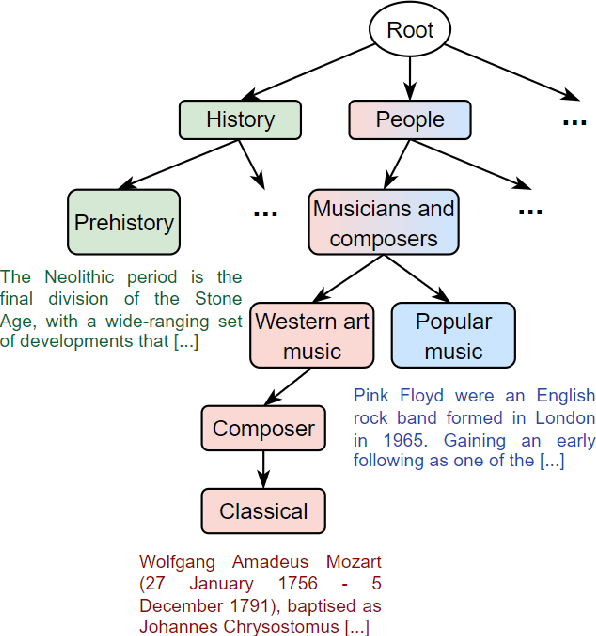
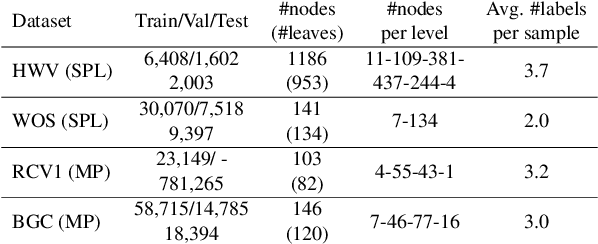
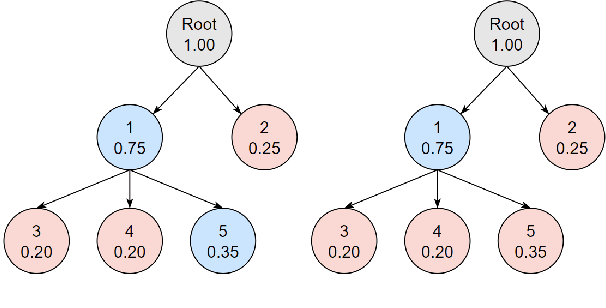
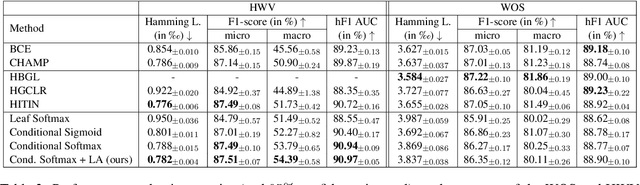
Hierarchical text classification (HTC) is the task of assigning labels to a text within a structured space organized as a hierarchy. Recent works treat HTC as a conventional multilabel classification problem, therefore evaluating it as such. We instead propose to evaluate models based on specifically designed hierarchical metrics and we demonstrate the intricacy of metric choice and prediction inference method. We introduce a new challenging dataset and we evaluate fairly, recent sophisticated models, comparing them with a range of simple but strong baselines, including a new theoretically motivated loss. Finally, we show that those baselines are very often competitive with the latest models. This highlights the importance of carefully considering the evaluation methodology when proposing new methods for HTC. Code implementation and dataset are available at \url{https://github.com/RomanPlaud/revisitingHTC}.
Explaining Text Classifiers with Counterfactual Representations
Feb 01, 2024



One well motivated explanation method for classifiers leverages counterfactuals which are hypothetical events identical to real observations in all aspects except for one categorical feature. Constructing such counterfactual poses specific challenges for texts, however, as some attribute values may not necessarily align with plausible real-world events. In this paper we propose a simple method for generating counterfactuals by intervening in the space of text representations which bypasses this limitation. We argue that our interventions are minimally disruptive and that they are theoretically sound as they align with counterfactuals as defined in Pearl's causal inference framework. To validate our method, we first conduct experiments on a synthetic dataset of counterfactuals, allowing for a direct comparison between classifier predictions based on ground truth counterfactuals (obtained through explicit text interventions) and our counterfactuals, derived through interventions in the representation space. Second, we study a real world scenario where our counterfactuals can be leveraged both for explaining a classifier and for bias mitigation.
Fair Evaluation of Graph Markov Neural Networks
Apr 03, 2023



Graph Markov Neural Networks (GMNN) have recently been proposed to improve regular graph neural networks (GNN) by including label dependencies into the semi-supervised node classification task. GMNNs do this in a theoretically principled way and use three kinds of information to predict labels. Just like ordinary GNNs, they use the node features and the graph structure but they moreover leverage information from the labels of neighboring nodes to improve the accuracy of their predictions. In this paper, we introduce a new dataset named WikiVitals which contains a graph of 48k mutually referred Wikipedia articles classified into 32 categories and connected by 2.3M edges. Our aim is to rigorously evaluate the contributions of three distinct sources of information to the prediction accuracy of GMNN for this dataset: the content of the articles, their connections with each other and the correlations among their labels. For this purpose we adapt a method which was recently proposed for performing fair comparisons of GNN performance using an appropriate randomization over partitions and a clear separation of model selection and model assessment.
Role of Simplicity in Creative Behaviour: The Case of the Poietic Generator
Dec 22, 2016
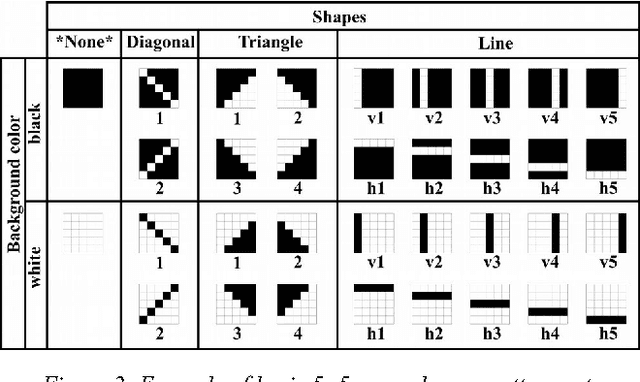
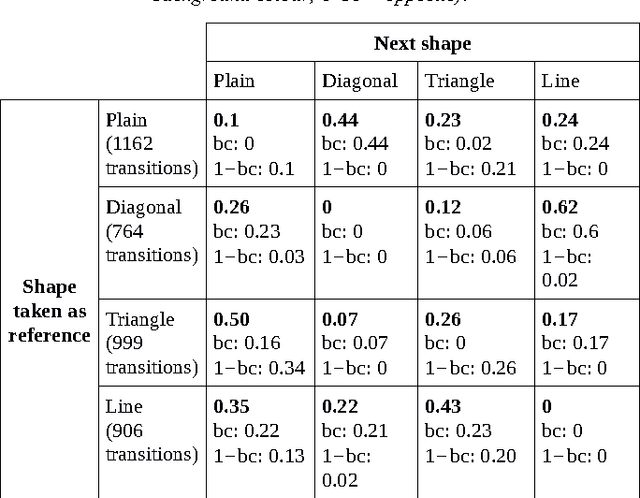
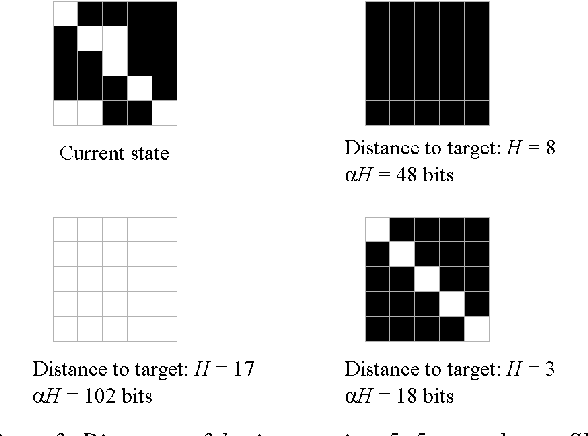
We propose to apply Simplicity Theory (ST) to model interest in creative situations. ST has been designed to describe and predict interest in communication. Here we use ST to derive a decision rule that we apply to a simplified version of a creative game, the Poietic Generator. The decision rule produces what can be regarded as an elementary form of creativity. This study is meant as a proof of principle. It suggests that some creative actions may be motivated by the search for unexpected simplicity.
* This study was supported by grants from the programme Futur&Ruptures and from the 'Chaire Modelisation des Imaginaires, Innovation et Creation', http://www.computationalcreativity.net/iccc2016/posters-and-demos/