 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Concept Erasure: a Density Matching Approach
Jul 16, 2025Ensuring that neural models used in real-world applications cannot infer sensitive information, such as demographic attributes like gender or race, from text representations is a critical challenge when fairness is a concern. We address this issue through concept erasure, a process that removes information related to a specific concept from distributed representations while preserving as much of the remaining semantic information as possible. Our approach involves learning an orthogonal projection in the embedding space, designed to make the class-conditional feature distributions of the discrete concept to erase indistinguishable after projection. By adjusting the rank of the projector, we control the extent of information removal, while its orthogonality ensures strict preservation of the local structure of the embeddings. Our method, termed $\overline{\mathrm{L}}$EOPARD, achieves state-of-the-art performance in nonlinear erasure of a discrete attribute on classic natural language processing benchmarks. Furthermore, we demonstrate that $\overline{\mathrm{L}}$EOPARD effectively mitigates bias in deep nonlinear classifiers, thereby promoting fairness.
Explaining Text Classifiers with Counterfactual Representations
Feb 01, 2024



One well motivated explanation method for classifiers leverages counterfactuals which are hypothetical events identical to real observations in all aspects except for one categorical feature. Constructing such counterfactual poses specific challenges for texts, however, as some attribute values may not necessarily align with plausible real-world events. In this paper we propose a simple method for generating counterfactuals by intervening in the space of text representations which bypasses this limitation. We argue that our interventions are minimally disruptive and that they are theoretically sound as they align with counterfactuals as defined in Pearl's causal inference framework. To validate our method, we first conduct experiments on a synthetic dataset of counterfactuals, allowing for a direct comparison between classifier predictions based on ground truth counterfactuals (obtained through explicit text interventions) and our counterfactuals, derived through interventions in the representation space. Second, we study a real world scenario where our counterfactuals can be leveraged both for explaining a classifier and for bias mitigation.
Towards Scalable Adaptive Learning with Graph Neural Networks and Reinforcement Learning
May 10, 2023Adaptive learning is an area of educational technology that consists in delivering personalized learning experiences to address the unique needs of each learner. An important subfield of adaptive learning is learning path personalization: it aims at designing systems that recommend sequences of educational activities to maximize students' learning outcomes. Many machine learning approaches have already demonstrated significant results in a variety of contexts related to learning path personalization. However, most of them were designed for very specific settings and are not very reusable. This is accentuated by the fact that they often rely on non-scalable models, which are unable to integrate new elements after being trained on a specific set of educational resources. In this paper, we introduce a flexible and scalable approach towards the problem of learning path personalization, which we formalize as a reinforcement learning problem. Our model is a sequential recommender system based on a graph neural network, which we evaluate on a population of simulated learners. Our results demonstrate that it can learn to make good recommendations in the small-data regime.
Fair Evaluation of Graph Markov Neural Networks
Apr 03, 2023



Graph Markov Neural Networks (GMNN) have recently been proposed to improve regular graph neural networks (GNN) by including label dependencies into the semi-supervised node classification task. GMNNs do this in a theoretically principled way and use three kinds of information to predict labels. Just like ordinary GNNs, they use the node features and the graph structure but they moreover leverage information from the labels of neighboring nodes to improve the accuracy of their predictions. In this paper, we introduce a new dataset named WikiVitals which contains a graph of 48k mutually referred Wikipedia articles classified into 32 categories and connected by 2.3M edges. Our aim is to rigorously evaluate the contributions of three distinct sources of information to the prediction accuracy of GMNN for this dataset: the content of the articles, their connections with each other and the correlations among their labels. For this purpose we adapt a method which was recently proposed for performing fair comparisons of GNN performance using an appropriate randomization over partitions and a clear separation of model selection and model assessment.
Reconciling Causality and Statistics
Jul 08, 2020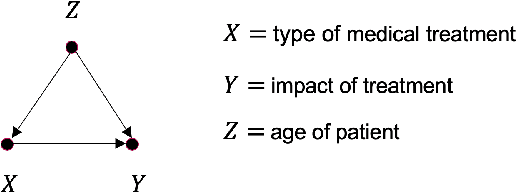



Statisticians have warned us since the early days of their discipline that experimental correlation between two observations by no means implies the existence of a causal relation. The question about what clues exist in observational data that could informs us about the existence of such causal relations is nevertheless more that legitimate. It lies actually at the root of any scientific endeavor. For decades however the only accepted method among statisticians to elucidate causal relationships was the so called Randomized Controlled Trial. Besides this notorious exception causality questions remained largely taboo for many. One reason for this state of affairs was the lack of an appropriate mathematical framework to formulate such questions in an unambiguous way. Fortunately thinks have changed these last years with the advent of the so called Causality Revolution initiated by Judea Pearl and coworkers. The aim of this pedagogical paper is to present their ideas and methods in a compact and self-contained fashion with concrete business examples as illustrations.
Deep Learning Models for Automatic Summarization
May 25, 2020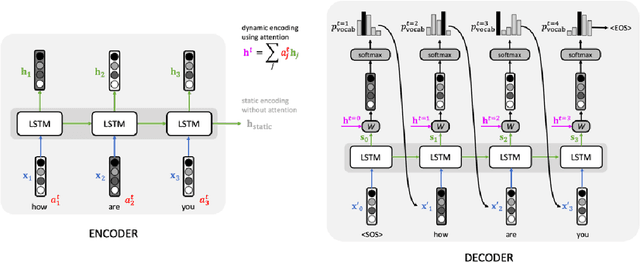


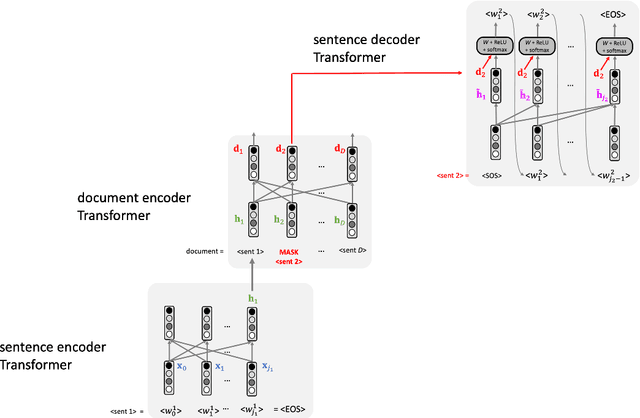
Text summarization is an NLP task which aims to convert a textual document into a shorter one while keeping as much meaning as possible. This pedagogical article reviews a number of recent Deep Learning architectures that have helped to advance research in this field. We will discuss in particular applications of pointer networks, hierarchical Transformers and Reinforcement Learning. We assume basic knowledge of Seq2Seq architecture and Transformer networks within NLP.
A Primer on Domain Adaptation
Feb 11, 2020
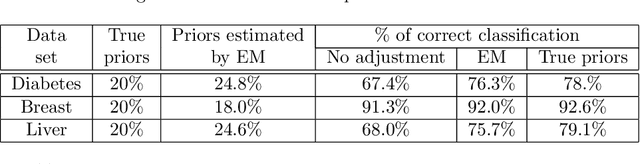

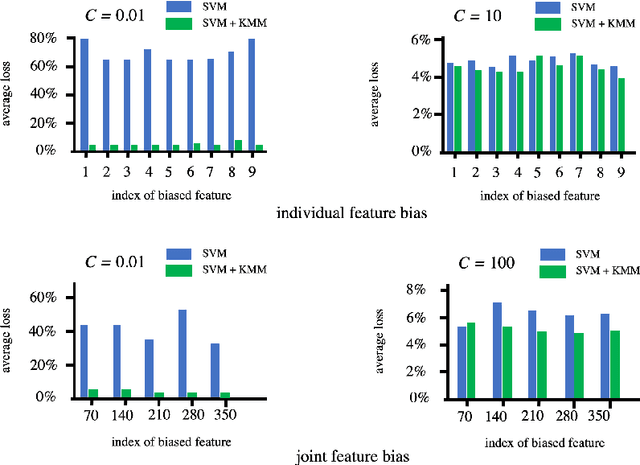
Standard supervised machine learning assumes that the distribution of the source samples used to train an algorithm is the same as the one of the target samples on which it is supposed to make predictions. However, as any data scientist will confirm, this is hardly ever the case in practice. The set of statistical and numerical methods that deal with such situations is known as domain adaptation, a field with a long and rich history. The myriad of methods available and the unfortunate lack of a clear and universally accepted terminology can however make the topic rather daunting for the newcomer. Therefore, rather than aiming at completeness, which leads to exhibiting a tedious catalog of methods, this pedagogical review aims at a coherent presentation of four important special cases: (1) prior shift, a situation in which training samples were selected according to their labels without any knowledge of their actual distribution in the target, (2) covariate shift which deals with a situation where training examples were picked according to their features but with some selection bias, (3) concept shift where the dependence of the labels on the features defers between the source and the target, and last but not least (4) subspace mapping which deals with a situation where features in the target have been subjected to an unknown distortion with respect to the source features. In each case we first build an intuition, next we provide the appropriate mathematical framework and eventually we describe a practical application.
On Generalization and Regularization in Deep Learning
Apr 06, 2017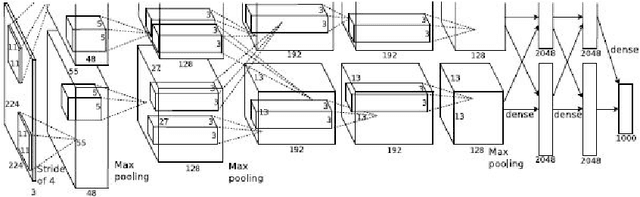

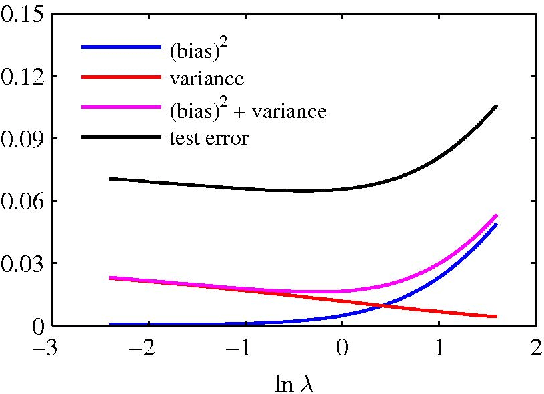
Why do large neural network generalize so well on complex tasks such as image classification or speech recognition? What exactly is the role regularization for them? These are arguably among the most important open questions in machine learning today. In a recent and thought provoking paper [C. Zhang et al.] several authors performed a number of numerical experiments that hint at the need for novel theoretical concepts to account for this phenomenon. The paper stirred quit a lot of excitement among the machine learning community but at the same time it created some confusion as discussions on OpenReview.net testifies. The aim of this pedagogical paper is to make this debate accessible to a wider audience of data scientists without advanced theoretical knowledge in statistical learning. The focus here is on explicit mathematical definitions and on a discussion of relevant concepts, not on proofs for which we provide references.