 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Primer on Domain Adaptation
Paper and Code
Feb 11, 2020
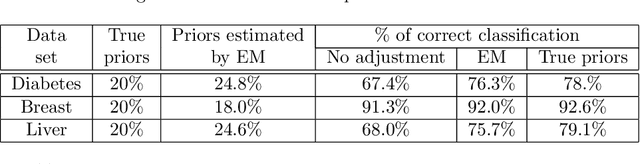

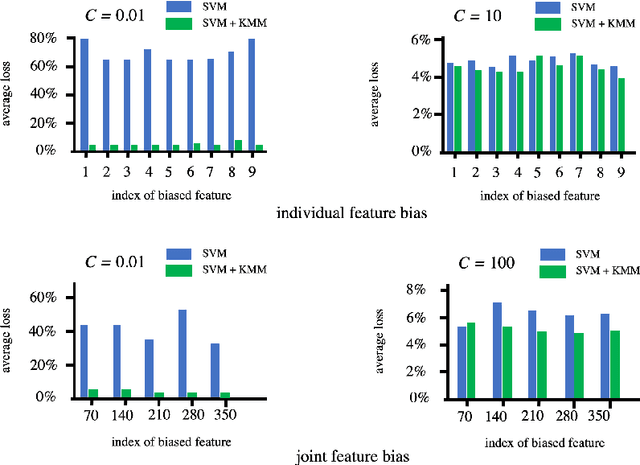
Standard supervised machine learning assumes that the distribution of the source samples used to train an algorithm is the same as the one of the target samples on which it is supposed to make predictions. However, as any data scientist will confirm, this is hardly ever the case in practice. The set of statistical and numerical methods that deal with such situations is known as domain adaptation, a field with a long and rich history. The myriad of methods available and the unfortunate lack of a clear and universally accepted terminology can however make the topic rather daunting for the newcomer. Therefore, rather than aiming at completeness, which leads to exhibiting a tedious catalog of methods, this pedagogical review aims at a coherent presentation of four important special cases: (1) prior shift, a situation in which training samples were selected according to their labels without any knowledge of their actual distribution in the target, (2) covariate shift which deals with a situation where training examples were picked according to their features but with some selection bias, (3) concept shift where the dependence of the labels on the features defers between the source and the target, and last but not least (4) subspace mapping which deals with a situation where features in the target have been subjected to an unknown distortion with respect to the source features. In each case we first build an intuition, next we provide the appropriate mathematical framework and eventually we describe a practical application.