 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Evolving Agents: Open-Ended Self-Improvement via Experience Sharing
Feb 04, 2026Open-ended self-improving agents can autonomously modify their own structural designs to advance their capabilities and overcome the limits of pre-defined architectures, thus reducing reliance on human intervention. We introduce Group-Evolving Agents (GEA), a new paradigm for open-ended self-improvements, which treats a group of agents as the fundamental evolutionary unit, enabling explicit experience sharing and reuse within the group throughout evolution. Unlike existing open-ended self-evolving paradigms that adopt tree-structured evolution, GEA overcomes the limitation of inefficient utilization of exploratory diversity caused by isolated evolutionary branches. We evaluate GEA on challenging coding benchmarks, where it significantly outperforms state-of-the-art self-evolving methods (71.0% vs. 56.7% on SWE-bench Verified, 88.3% vs. 68.3% on Polyglot) and matches or exceeds top human-designed agent frameworks (71.8% and 52.0% on two benchmarks, respectively). Analysis reveals that GEA more effectively converts early-stage exploratory diversity into sustained, long-term progress, achieving stronger performance under the same number of evolved agents. Furthermore, GEA exhibits consistent transferability across different coding models and greater robustness, fixing framework-level bugs in 1.4 iterations on average, versus 5 for self-evolving methods.
LLMs vs. Chinese Anime Enthusiasts: A Comparative Study on Emotionally Supportive Role-Playing
Aug 08, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in role-playing conversations and providing emotional support as separate research directions. However, there remains a significant research gap in combining these capabilities to enable emotionally supportive interactions with virtual characters. To address this research gap, we focus on anime characters as a case study because of their well-defined personalities and large fan bases. This choice enables us to effectively evaluate how well LLMs can provide emotional support while maintaining specific character traits. We introduce ChatAnime, the first Emotionally Supportive Role-Playing (ESRP) dataset. We first thoughtfully select 20 top-tier characters from popular anime communities and design 60 emotion-centric real-world scenario questions. Then, we execute a nationwide selection process to identify 40 Chinese anime enthusiasts with profound knowledge of specific characters and extensive experience in role-playing. Next, we systematically collect two rounds of dialogue data from 10 LLMs and these 40 Chinese anime enthusiasts. To evaluate the ESRP performance of LLMs, we design a user experience-oriented evaluation system featuring 9 fine-grained metrics across three dimensions: basic dialogue, role-playing and emotional support, along with an overall metric for response diversity. In total, the dataset comprises 2,400 human-written and 24,000 LLM-generated answers, supported by over 132,000 human annotations. Experimental results show that top-performing LLMs surpass human fans in role-playing and emotional support, while humans still lead in response diversity. We hope this work can provide valuable resources and insights for future research on optimizing LLMs in ESRP. Our datasets are available at https://github.com/LanlanQiu/ChatAnime.
THOUGHTTERMINATOR: Benchmarking, Calibrating, and Mitigating Overthinking in Reasoning Models
Apr 17, 2025



Reasoning models have demonstrated impressive performance on difficult tasks that traditional language models struggle at. However, many are plagued with the problem of overthinking--generating large amounts of unnecessary tokens which don't improve accuracy on a question. We introduce approximate measures of problem-level difficulty and demonstrate that a clear relationship between problem difficulty and optimal token spend exists, and evaluate how well calibrated a variety of reasoning models are in terms of efficiently allocating the optimal token count. We find that in general, reasoning models are poorly calibrated, particularly on easy problems. To evaluate calibration on easy questions we introduce DUMB500, a dataset of extremely easy math, reasoning, code, and task problems, and jointly evaluate reasoning model on these simple examples and extremely difficult examples from existing frontier benchmarks on the same task domain. Finally, we introduce THOUGHTTERMINATOR, a training-free black box decoding technique that significantly improves reasoning model calibration.
$B^4$: A Black-Box Scrubbing Attack on LLM Watermarks
Nov 02, 2024Watermarking has emerged as a prominent technique for LLM-generated content detection by embedding imperceptible patterns. Despite supreme performance, its robustness against adversarial attacks remains underexplored. Previous work typically considers a grey-box attack setting, where the specific type of watermark is already known. Some even necessitates knowledge about hyperparameters of the watermarking method. Such prerequisites are unattainable in real-world scenarios. Targeting at a more realistic black-box threat model with fewer assumptions, we here propose $\mathcal{B}^4$, a black-box scrubbing attack on watermarks. Specifically, we formulate the watermark scrubbing attack as a constrained optimization problem by capturing its objectives with two distributions, a Watermark Distribution and a Fidelity Distribution. This optimization problem can be approximately solved using two proxy distributions. Experimental results across 12 different settings demonstrate the superior performance of $\mathcal{B}^4$ compared with other baselines.
Style-Compress: An LLM-Based Prompt Compression Framework Considering Task-Specific Styles
Oct 17, 2024
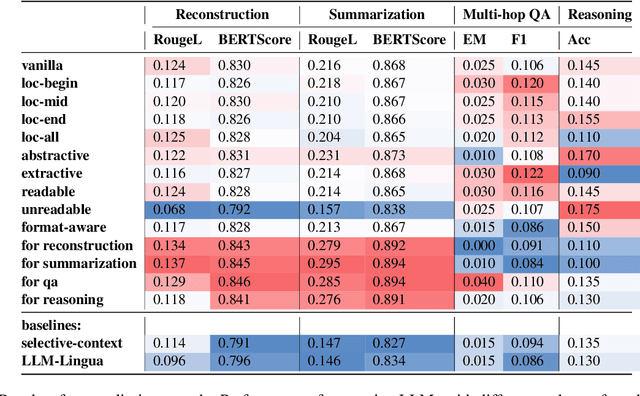

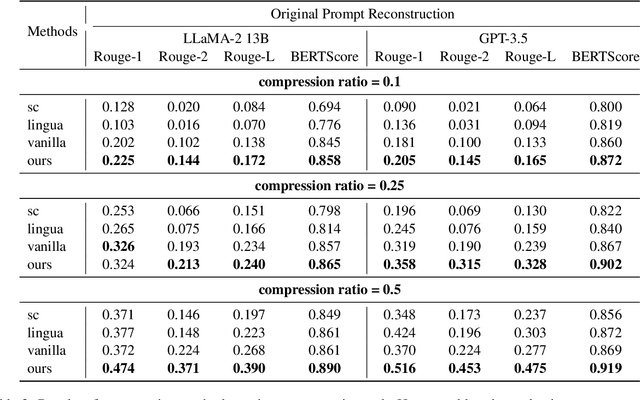
Prompt compression condenses contexts while maintaining their informativeness for different usage scenarios. It not only shortens the inference time and reduces computational costs during the usage of large language models, but also lowers expenses when using closed-source models. In a preliminary study, we discover that when instructing language models to compress prompts, different compression styles (e.g., extractive or abstractive) impact performance of compressed prompts on downstream tasks. Building on this insight, we propose Style-Compress, a lightweight framework that adapts a smaller language model to compress prompts for a larger model on a new task without additional training. Our approach iteratively generates and selects effective compressed prompts as task-specific demonstrations through style variation and in-context learning, enabling smaller models to act as efficient compressors with task-specific examples. Style-Compress outperforms two baseline compression models in four tasks: original prompt reconstruction, text summarization, multi-hop QA, and CoT reasoning. In addition, with only 10 samples and 100 queries for adaptation, prompts compressed by Style-Compress achieve performance on par with or better than original prompts at a compression ratio of 0.25 or 0.5.
Better than Random: Reliable NLG Human Evaluation with Constrained Active Sampling
Jun 12, 2024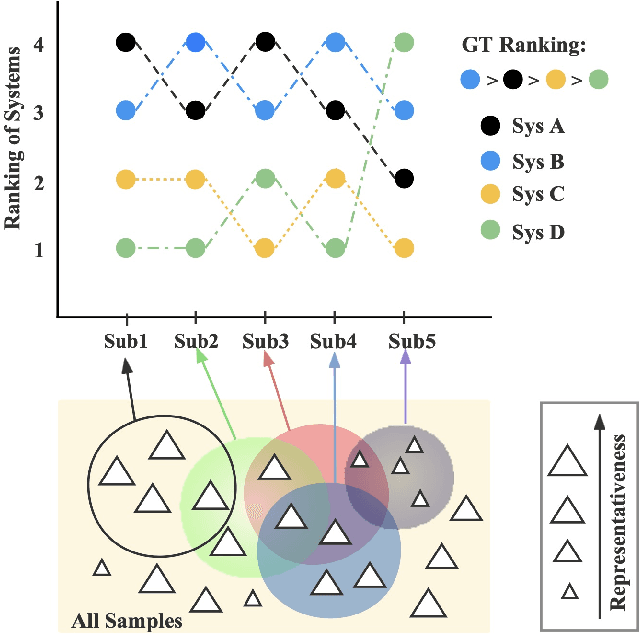
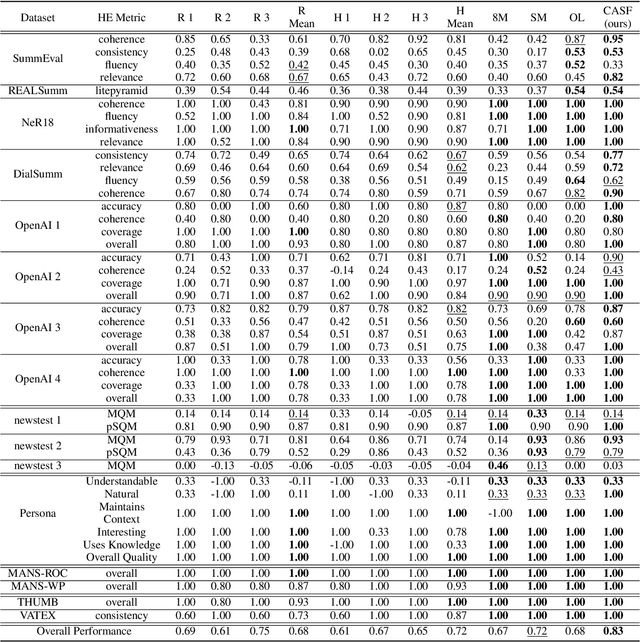
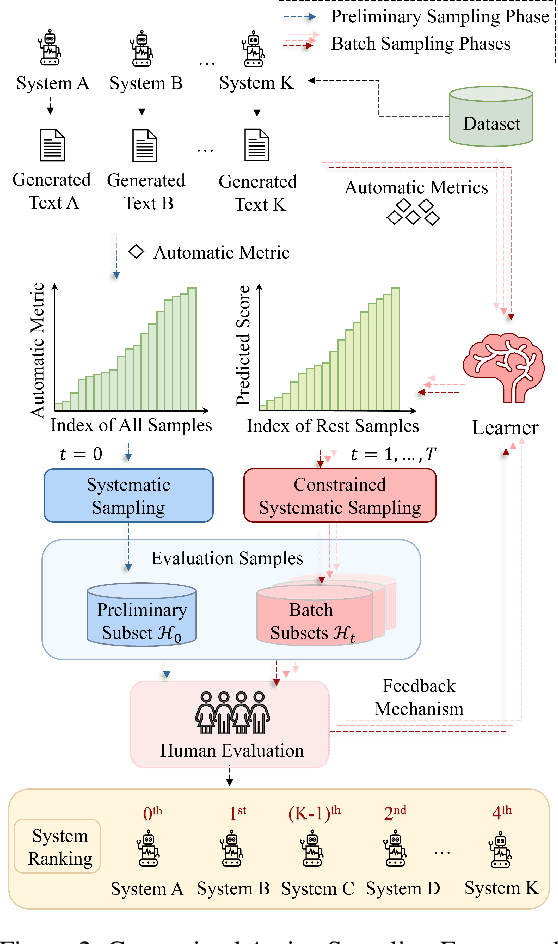
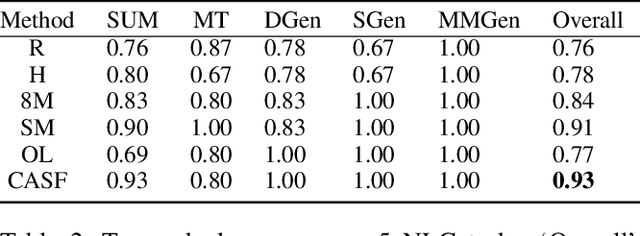
Human evaluation is viewed as a reliable evaluation method for NLG which is expensive and time-consuming. To save labor and costs, researchers usually perform human evaluation on a small subset of data sampled from the whole dataset in practice. However, different selection subsets will lead to different rankings of the systems. To give a more correct inter-system ranking and make the gold standard human evaluation more reliable, we propose a Constrained Active Sampling Framework (CASF) for reliable human judgment. CASF operates through a Learner, a Systematic Sampler and a Constrained Controller to select representative samples for getting a more correct inter-system ranking.Experiment results on 137 real NLG evaluation setups with 44 human evaluation metrics across 16 datasets and 5 NLG tasks demonstrate CASF receives 93.18% top-ranked system recognition accuracy and ranks first or ranks second on 90.91% of the human metrics with 0.83 overall inter-system ranking Kendall correlation.Code and data are publicly available online.
Stumbling Blocks: Stress Testing the Robustness of Machine-Generated Text Detectors Under Attacks
Feb 18, 2024The widespread use of large language models (LLMs) is increasing the demand for methods that detect machine-generated text to prevent misuse. The goal of our study is to stress test the detectors' robustness to malicious attacks under realistic scenarios. We comprehensively study the robustness of popular machine-generated text detectors under attacks from diverse categories: editing, paraphrasing, prompting, and co-generating. Our attacks assume limited access to the generator LLMs, and we compare the performance of detectors on different attacks under different budget levels. Our experiments reveal that almost none of the existing detectors remain robust under all the attacks, and all detectors exhibit different loopholes. Averaging all detectors, the performance drops by 35% across all attacks. Further, we investigate the reasons behind these defects and propose initial out-of-the-box patches to improve robustness.
LLM-based NLG Evaluation: Current Status and Challenges
Feb 02, 2024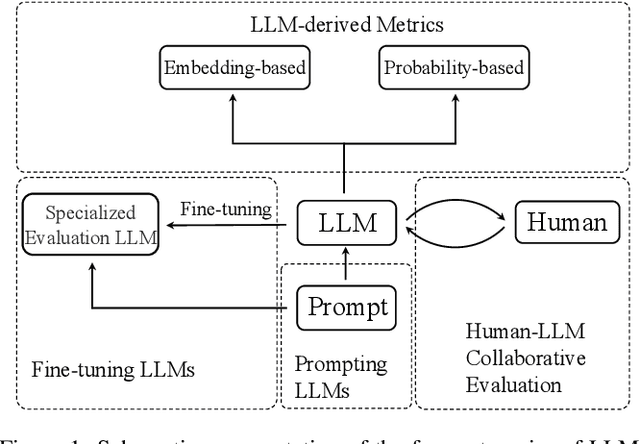
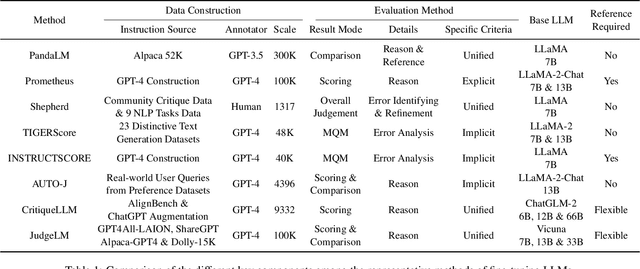

Evaluating natural language generation (NLG) is a vital but challenging problem in artificial intelligence. Traditional evaluation metrics mainly capturing content (e.g. n-gram) overlap between system outputs and references are far from satisfactory, and large language models (LLMs) such as ChatGPT have demonstrated great potential in NLG evaluation in recent years. Various automatic evaluation methods based on LLMs have been proposed, including metrics derived from LLMs, prompting LLMs, and fine-tuning LLMs with labeled evaluation data. In this survey, we first give a taxonomy of LLM-based NLG evaluation methods, and discuss their pros and cons, respectively. We also discuss human-LLM collaboration for NLG evaluation. Lastly, we discuss several open problems in this area and point out future research directions.
On the Zero-Shot Generalization of Machine-Generated Text Detectors
Oct 08, 2023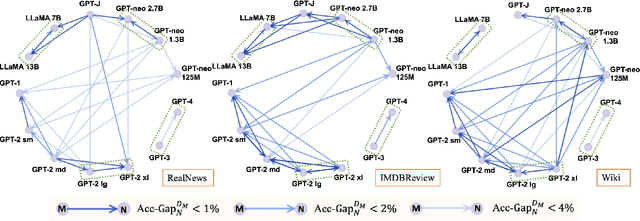
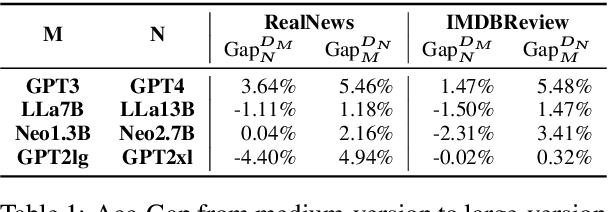
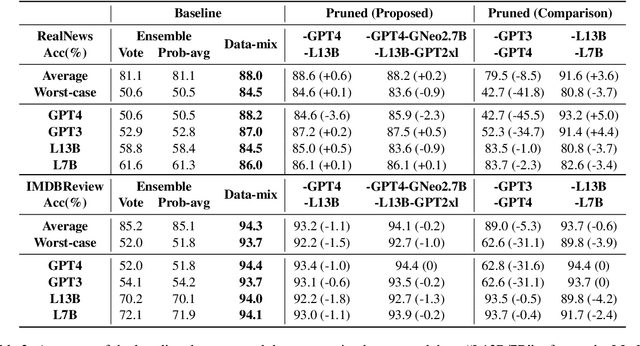
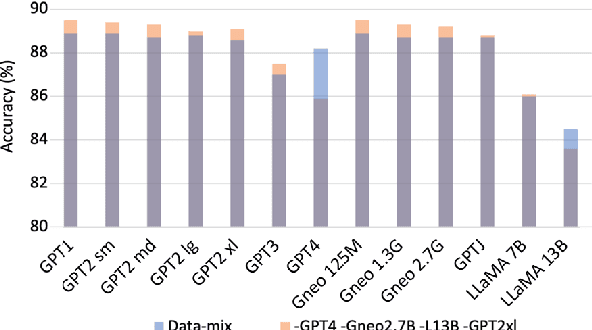
The rampant proliferation of large language models, fluent enough to generate text indistinguishable from human-written language, gives unprecedented importance to the detection of machine-generated text. This work is motivated by an important research question: How will the detectors of machine-generated text perform on outputs of a new generator, that the detectors were not trained on? We begin by collecting generation data from a wide range of LLMs, and train neural detectors on data from each generator and test its performance on held-out generators. While none of the detectors can generalize to all generators, we observe a consistent and interesting pattern that the detectors trained on data from a medium-size LLM can zero-shot generalize to the larger version. As a concrete application, we demonstrate that robust detectors can be built on an ensemble of training data from medium-sized models.
Summarization is (Almost) Dead
Sep 18, 2023



How well can large language models (LLMs) generate summaries? We develop new datasets and conduct human evaluation experiments to evaluate the zero-shot generation capability of LLMs across five distinct summarization tasks. Our findings indicate a clear preference among human evaluators for LLM-generated summaries over human-written summaries and summaries generated by fine-tuned models. Specifically, LLM-generated summaries exhibit better factual consistency and fewer instances of extrinsic hallucinations. Due to the satisfactory performance of LLMs in summarization tasks (even surpassing the benchmark of reference summaries), we believe that most conventional works in the field of text summarization are no longer necessary in the era of LLMs. However, we recognize that there are still some directions worth exploring, such as the creation of novel datasets with higher quality and more reliable evaluation methods.