 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Compress: An LLM-Based Prompt Compression Framework Considering Task-Specific Styles
Paper and Code

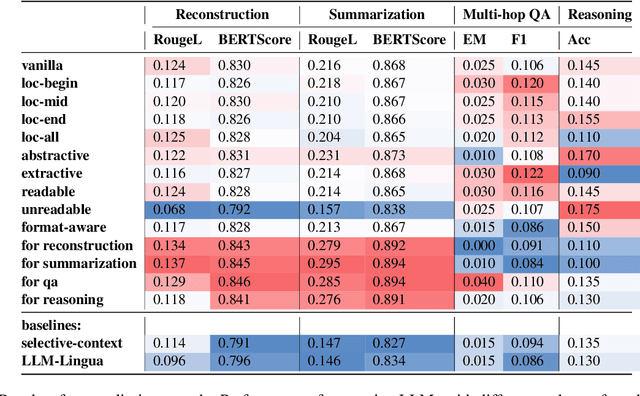

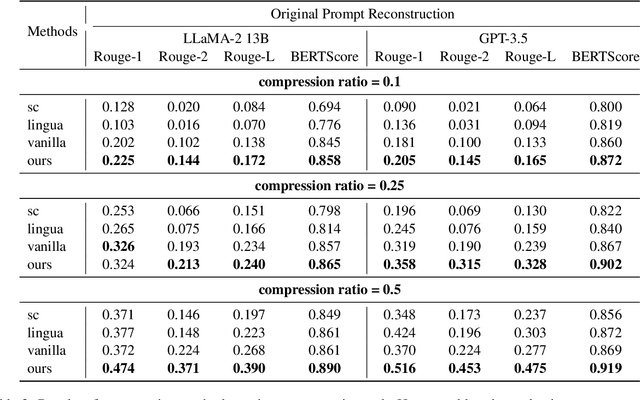
Prompt compression condenses contexts while maintaining their informativeness for different usage scenarios. It not only shortens the inference time and reduces computational costs during the usage of large language models, but also lowers expenses when using closed-source models. In a preliminary study, we discover that when instructing language models to compress prompts, different compression styles (e.g., extractive or abstractive) impact performance of compressed prompts on downstream tasks. Building on this insight, we propose Style-Compress, a lightweight framework that adapts a smaller language model to compress prompts for a larger model on a new task without additional training. Our approach iteratively generates and selects effective compressed prompts as task-specific demonstrations through style variation and in-context learning, enabling smaller models to act as efficient compressors with task-specific examples. Style-Compress outperforms two baseline compression models in four tasks: original prompt reconstruction, text summarization, multi-hop QA, and CoT reasoning. In addition, with only 10 samples and 100 queries for adaptation, prompts compressed by Style-Compress achieve performance on par with or better than original prompts at a compression ratio of 0.25 or 0.5.