 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Learning in Fourier Complex Field for VHR Remote Sensing Images
Oct 28, 2022



Very high-resolution (VHR) remote sensing (RS) image classification is the fundamental task for RS image analysis and understanding. Recently, transformer-based models demonstrated outstanding potential for learning high-order contextual relationships from natural images with general resolution (224x224 pixels) and achieved remarkable results on general image classification tasks. However, the complexity of the naive transformer grows quadratically with the increase in image size, which prevents transformer-based models from VHR RS image (500x500 pixels) classification and other computationally expensive downstream tasks. To this end, we propose to decompose the expensive self-attention (SA) into real and imaginary parts via discrete Fourier transform (DFT) and therefore propose an efficient complex self-attention (CSA) mechanism. Benefiting from the conjugated symmetric property of DFT, CSA is capable to model the high-order contextual information with less than half computations of naive SA. To overcome the gradient explosion in Fourier complex field, we replace the Softmax function with the carefully designed Logmax function to normalize the attention map of CSA and stabilize the gradient propagation. By stacking various layers of CSA blocks, we propose the Fourier Complex Transformer (FCT) model to learn global contextual information from VHR aerial images following the hierarchical manners. Universal experiments conducted on commonly used RS classification data sets demonstrate the effectiveness and efficiency of FCT, especially on very high-resolution RS images.
Domain Private and Agnostic Feature for Modality Adaptive Face Recognition
Aug 10, 2020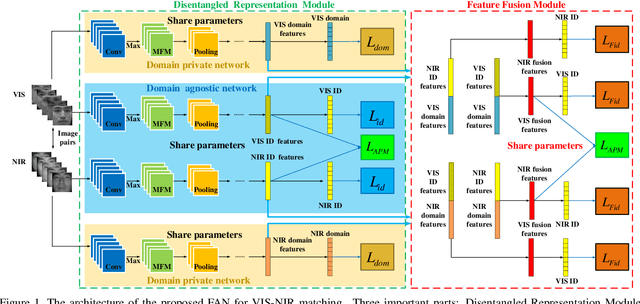
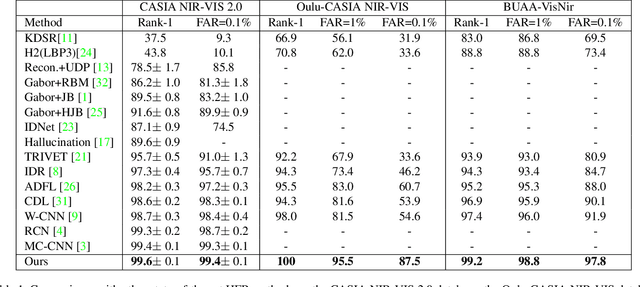
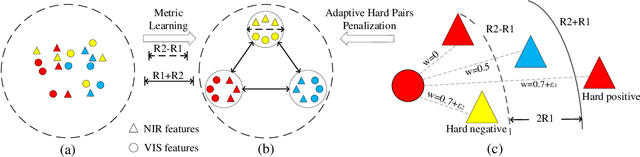
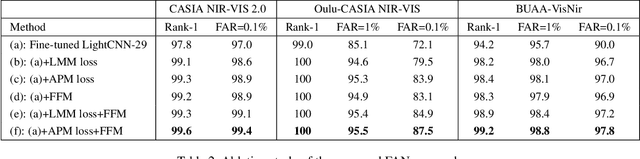
Heterogeneous face recognition is a challenging task due to the large modality discrepancy and insufficient cross-modal samples. Most existing works focus on discriminative feature transformation, metric learning and cross-modal face synthesis. However, the fact that cross-modal faces are always coupled by domain (modality) and identity information has received little attention. Therefore, how to learn and utilize the domain-private feature and domain-agnostic feature for modality adaptive face recognition is the focus of this work. Specifically, this paper proposes a Feature Aggregation Network (FAN), which includes disentangled representation module (DRM), feature fusion module (FFM) and adaptive penalty metric (APM) learning session. First, in DRM, two subnetworks, i.e. domain-private network and domain-agnostic network are specially designed for learning modality features and identity features, respectively. Second, in FFM, the identity features are fused with domain features to achieve cross-modal bi-directional identity feature transformation, which, to a large extent, further disentangles the modality information and identity information. Third, considering that the distribution imbalance between easy and hard pairs exists in cross-modal datasets, which increases the risk of model bias, the identity preserving guided metric learning with adaptive hard pairs penalization is proposed in our FAN. The proposed APM also guarantees the cross-modality intra-class compactness and inter-class separation. Extensive experiments on benchmark cross-modal face datasets show that our FAN outperforms SOTA methods.
BoostGAN for Occlusive Profile Face Frontalization and Recognition
Feb 26, 2019



There are many facts affecting human face recognition, such as pose, occlusion, illumination, age, etc. First and foremost are large pose and occlusion problems, which can even result in more than 10% performance degradation. Pose-invariant feature representation and face frontalization with generative adversarial networks (GAN) have been widely used to solve the pose problem. However, the synthesis and recognition of occlusive but profile faces is still an uninvestigated problem. To address this issue, in this paper, we aim to contribute an effective solution on how to recognize occlusive but profile faces, even with facial keypoint region (e.g. eyes, nose, etc.) corrupted. Specifically, we propose a boosting Generative Adversarial Network (BoostGAN) for de-occlusion, frontalization, and recognition of faces. Upon the assumption that facial occlusion is partial and incomplete, multiple patch occluded images are fed as inputs for knowledge boosting, such as identity and texture information. A new aggregation structure composed of a deep GAN for coarse face synthesis and a shallow boosting net for fine face generation is further designed. Exhaustive experiments demonstrate that the proposed approach not only presents clear perceptual photo-realistic results but also shows state-of-the-art recognition performance for occlusive but profile faces.