 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSarcasmMiner: A Dual-Track Post-Training Framework for Robust Audio-Visual Sarcasm Reasoning
Mar 05, 2026Multimodal sarcasm detection requires resolving pragmatic incongruity across textual, acoustic, and visual cues through cross-modal reasoning. To enable robust sarcasm reasoning with foundation models, we propose SarcasmMiner, a reinforcement learning based post-training framework that resists hallucination in multimodal reasoning. We reformulate sarcasm detection as structured reasoning and adopt a dual-track distillation strategy: high-quality teacher trajectories initialize the student model, while the full set of trajectories trains a generative reward model (GenRM) to evaluate reasoning quality. The student is optimized with group relative policy optimization (GRPO) using decoupled rewards for accuracy and reasoning quality. On MUStARD++, SarcasmMiner increases F1 from 59.83% (zero-shot), 68.23% (supervised finetuning) to 70.22%. These findings suggest that reasoning-aware reward modeling enhances both performance and multimodal grounding.
Making Machines Sound Sarcastic: LLM-Enhanced and Retrieval-Guided Sarcastic Speech Synthesis
Oct 08, 2025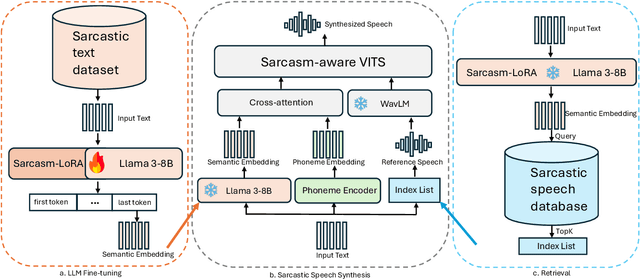
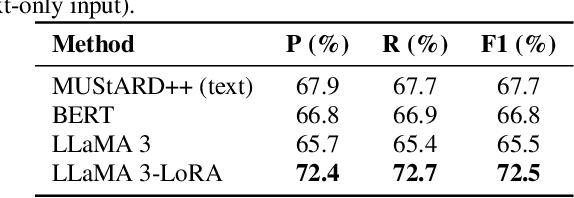
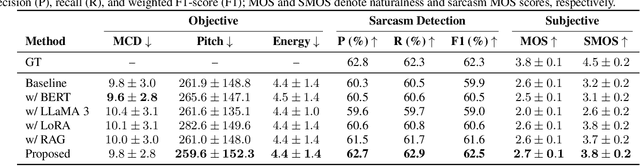
Sarcasm is a subtle form of non-literal language that poses significant challenges for speech synthesis due to its reliance on nuanced semantic, contextual, and prosodic cues. While existing speech synthesis research has focused primarily on broad emotional categories, sarcasm remains largely unexplored. In this paper, we propose a Large Language Model (LLM)-enhanced Retrieval-Augmented framework for sarcasm-aware speech synthesis. Our approach combines (1) semantic embeddings from a LoRA-fine-tuned LLaMA 3, which capture pragmatic incongruity and discourse-level cues of sarcasm, and (2) prosodic exemplars retrieved via a Retrieval Augmented Generation (RAG) module, which provide expressive reference patterns of sarcastic delivery. Integrated within a VITS backbone, this dual conditioning enables more natural and contextually appropriate sarcastic speech. Experiments demonstrate that our method outperforms baselines in both objective measures and subjective evaluations, yielding improvements in speech naturalness, sarcastic expressivity, and downstream sarcasm detection.
Spoken in Jest, Detected in Earnest: A Systematic Review of Sarcasm Recognition -- Multimodal Fusion, Challenges, and Future Prospects
Sep 04, 2025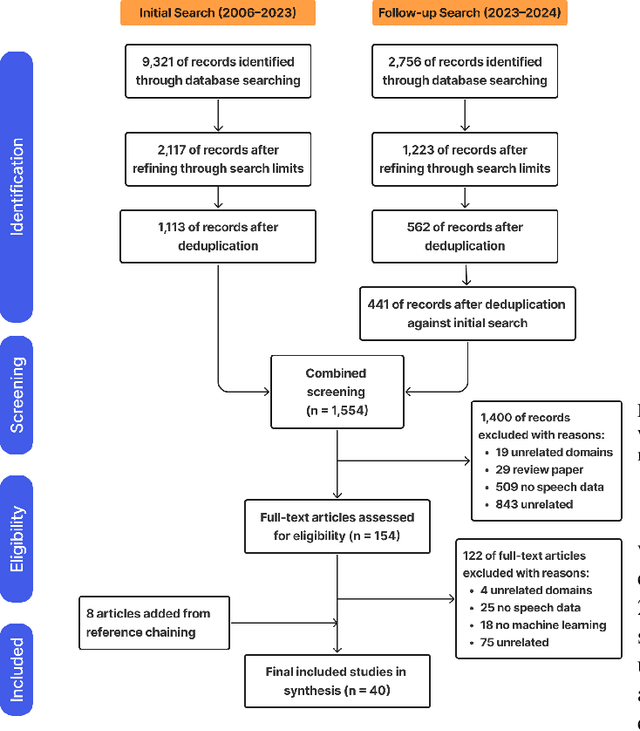



Sarcasm, a common feature of human communication, poses challenges in interpersonal interactions and human-machine interactions. Linguistic research has highlighted the importance of prosodic cues, such as variations in pitch, speaking rate, and intonation, in conveying sarcastic intent. Although previous work has focused on text-based sarcasm detection, the role of speech data in recognizing sarcasm has been underexplored. Recent advancements in speech technology emphasize the growing importance of leveraging speech data for automatic sarcasm recognition, which can enhance social interactions for individuals with neurodegenerative conditions and improve machine understanding of complex human language use, leading to more nuanced interactions. This systematic review is the first to focus on speech-based sarcasm recognition, charting the evolution from unimodal to multimodal approaches. It covers datasets, feature extraction, and classification methods, and aims to bridge gaps across diverse research domains. The findings include limitations in datasets for sarcasm recognition in speech, the evolution of feature extraction techniques from traditional acoustic features to deep learning-based representations, and the progression of classification methods from unimodal approaches to multimodal fusion techniques. In so doing, we identify the need for greater emphasis on cross-cultural and multilingual sarcasm recognition, as well as the importance of addressing sarcasm as a multimodal phenomenon, rather than a text-based challenge.
Asymmetric Reinforcing against Multi-modal Representation Bias
Jan 02, 2025



The strength of multimodal learning lies in its ability to integrate information from various sources, providing rich and comprehensive insights. However, in real-world scenarios, multi-modal systems often face the challenge of dynamic modality contributions, the dominance of different modalities may change with the environments, leading to suboptimal performance in multimodal learning. Current methods mainly enhance weak modalities to balance multimodal representation bias, which inevitably optimizes from a partialmodality perspective, easily leading to performance descending for dominant modalities. To address this problem, we propose an Asymmetric Reinforcing method against Multimodal representation bias (ARM). Our ARM dynamically reinforces the weak modalities while maintaining the ability to represent dominant modalities through conditional mutual information. Moreover, we provide an in-depth analysis that optimizing certain modalities could cause information loss and prevent leveraging the full advantages of multimodal data. By exploring the dominance and narrowing the contribution gaps between modalities, we have significantly improved the performance of multimodal learning, making notable progress in mitigating imbalanced multimodal learning.
AMuSeD: An Attentive Deep Neural Network for Multimodal Sarcasm Detection Incorporating Bi-modal Data Augmentation
Dec 13, 2024



Detecting sarcasm effectively requires a nuanced understanding of context, including vocal tones and facial expressions. The progression towards multimodal computational methods in sarcasm detection, however, faces challenges due to the scarcity of data. To address this, we present AMuSeD (Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation). This approach utilizes the Multimodal Sarcasm Detection Dataset (MUStARD) and introduces a two-phase bimodal data augmentation strategy. The first phase involves generating varied text samples through Back Translation from several secondary languages. The second phase involves the refinement of a FastSpeech 2-based speech synthesis system, tailored specifically for sarcasm to retain sarcastic intonations. Alongside a cloud-based Text-to-Speech (TTS) service, this Fine-tuned FastSpeech 2 system produces corresponding audio for the text augmentations. We also investigate various attention mechanisms for effectively merging text and audio data, finding self-attention to be the most efficient for bimodal integration. Our experiments reveal that this combined augmentation and attention approach achieves a significant F1-score of 81.0% in text-audio modalities, surpassing even models that use three modalities from the MUStARD dataset.
A Functional Trade-off between Prosodic and Semantic Cues in Conveying Sarcasm
Aug 27, 2024



This study investigates the acoustic features of sarcasm and disentangles the interplay between the propensity of an utterance being used sarcastically and the presence of prosodic cues signaling sarcasm. Using a dataset of sarcastic utterances compiled from television shows, we analyze the prosodic features within utterances and key phrases belonging to three distinct sarcasm categories (embedded, propositional, and illocutionary), which vary in the degree of semantic cues present, and compare them to neutral expressions. Results show that in phrases where the sarcastic meaning is salient from the semantics, the prosodic cues are less relevant than when the sarcastic meaning is not evident from the semantics, suggesting a trade-off between prosodic and semantic cues of sarcasm at the phrase level. These findings highlight a lessened reliance on prosodic modulation in semantically dense sarcastic expressions and a nuanced interaction that shapes the communication of sarcastic intent.
Contextual Learning in Fourier Complex Field for VHR Remote Sensing Images
Oct 28, 2022



Very high-resolution (VHR) remote sensing (RS) image classification is the fundamental task for RS image analysis and understanding. Recently, transformer-based models demonstrated outstanding potential for learning high-order contextual relationships from natural images with general resolution (224x224 pixels) and achieved remarkable results on general image classification tasks. However, the complexity of the naive transformer grows quadratically with the increase in image size, which prevents transformer-based models from VHR RS image (500x500 pixels) classification and other computationally expensive downstream tasks. To this end, we propose to decompose the expensive self-attention (SA) into real and imaginary parts via discrete Fourier transform (DFT) and therefore propose an efficient complex self-attention (CSA) mechanism. Benefiting from the conjugated symmetric property of DFT, CSA is capable to model the high-order contextual information with less than half computations of naive SA. To overcome the gradient explosion in Fourier complex field, we replace the Softmax function with the carefully designed Logmax function to normalize the attention map of CSA and stabilize the gradient propagation. By stacking various layers of CSA blocks, we propose the Fourier Complex Transformer (FCT) model to learn global contextual information from VHR aerial images following the hierarchical manners. Universal experiments conducted on commonly used RS classification data sets demonstrate the effectiveness and efficiency of FCT, especially on very high-resolution RS images.