 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-aware Dual Cross-Attentive Neural Network with Label Fusion for Stance Detection in Misinformative Social Media Content
May 27, 2025The rapid evolution of social media has generated an overwhelming volume of user-generated content, conveying implicit opinions and contributing to the spread of misinformation. The method aims to enhance the detection of stance where misinformation can polarize user opinions. Stance detection has emerged as a crucial approach to effectively analyze underlying biases in shared information and combating misinformation. This paper proposes a novel method for \textbf{S}tance \textbf{P}rediction through a \textbf{L}abel-fused dual cross-\textbf{A}ttentive \textbf{E}motion-aware neural \textbf{Net}work (SPLAENet) in misinformative social media user-generated content. The proposed method employs a dual cross-attention mechanism and a hierarchical attention network to capture inter and intra-relationships by focusing on the relevant parts of source text in the context of reply text and vice versa. We incorporate emotions to effectively distinguish between different stance categories by leveraging the emotional alignment or divergence between the texts. We also employ label fusion that uses distance-metric learning to align extracted features with stance labels, improving the method's ability to accurately distinguish between stances. Extensive experiments demonstrate the significant improvements achieved by SPLAENet over existing state-of-the-art methods. SPLAENet demonstrates an average gain of 8.92\% in accuracy and 17.36\% in F1-score on the RumourEval dataset. On the SemEval dataset, it achieves average gains of 7.02\% in accuracy and 10.92\% in F1-score. On the P-stance dataset, it demonstrates average gains of 10.03\% in accuracy and 11.18\% in F1-score. These results validate the effectiveness of the proposed method for stance detection in the context of misinformative social media content.
Large Language Models Meet Stance Detection: A Survey of Tasks, Methods, Applications, Challenges and Future Directions
May 13, 2025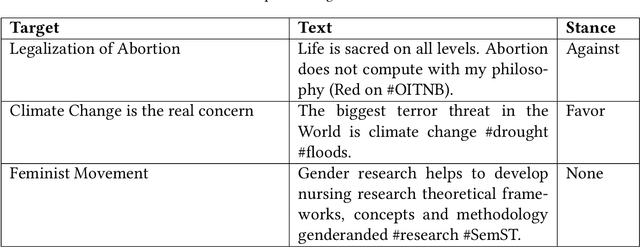
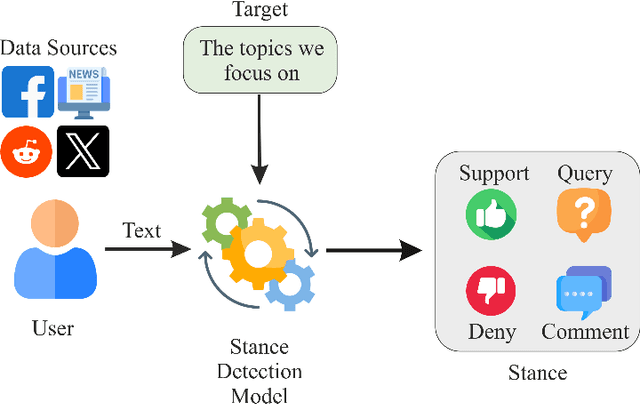

Stance detection is essential for understanding subjective content across various platforms such as social media, news articles, and online reviews. Recent advances in Large Language Models (LLMs) have revolutionized stance detection by introducing novel capabilities in contextual understanding, cross-domain generalization, and multimodal analysis. Despite these progressions, existing surveys often lack comprehensive coverage of approaches that specifically leverage LLMs for stance detection. To bridge this critical gap, our review article conducts a systematic analysis of stance detection, comprehensively examining recent advancements of LLMs transforming the field, including foundational concepts, methodologies, datasets, applications, and emerging challenges. We present a novel taxonomy for LLM-based stance detection approaches, structured along three key dimensions: 1) learning methods, including supervised, unsupervised, few-shot, and zero-shot; 2) data modalities, such as unimodal, multimodal, and hybrid; and 3) target relationships, encompassing in-target, cross-target, and multi-target scenarios. Furthermore, we discuss the evaluation techniques and analyze benchmark datasets and performance trends, highlighting the strengths and limitations of different architectures. Key applications in misinformation detection, political analysis, public health monitoring, and social media moderation are discussed. Finally, we identify critical challenges such as implicit stance expression, cultural biases, and computational constraints, while outlining promising future directions, including explainable stance reasoning, low-resource adaptation, and real-time deployment frameworks. Our survey highlights emerging trends, open challenges, and future directions to guide researchers and practitioners in developing next-generation stance detection systems powered by large language models.
A Comprehensive Review on Hashtag Recommendation: From Traditional to Deep Learning and Beyond
Mar 25, 2025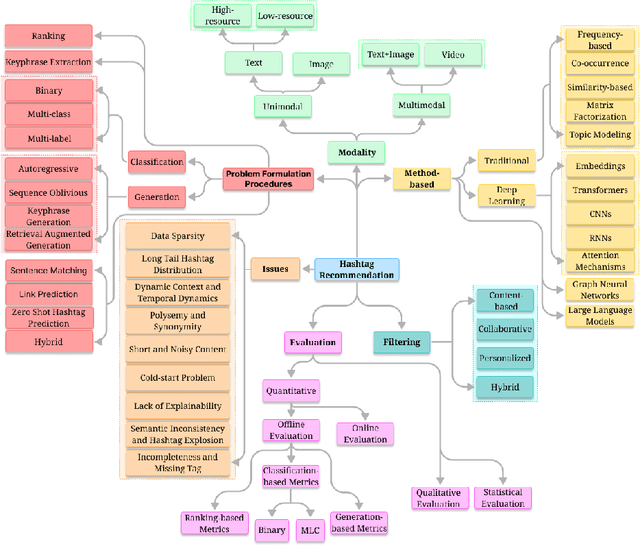
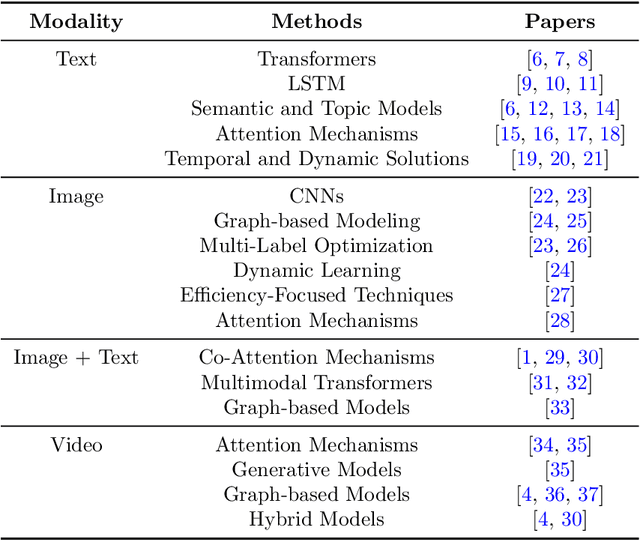
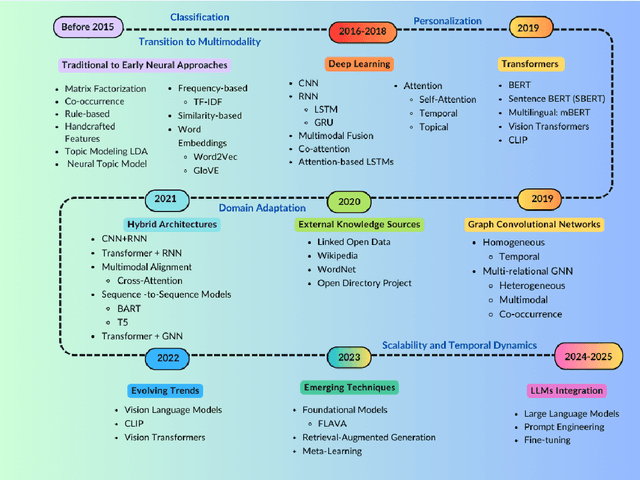

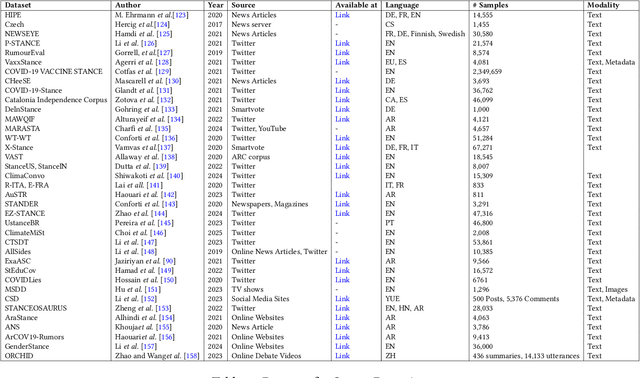
The exponential growth of user-generated content on social media platforms has precipitated significant challenges in information management, particularly in content organization, retrieval, and discovery. Hashtags, as a fundamental categorization mechanism, play a pivotal role in enhancing content visibility and user engagement. However, the development of accurate and robust hashtag recommendation systems remains a complex and evolving research challenge. Existing surveys in this domain are limited in scope and recency, focusing narrowly on specific platforms, methodologies, or timeframes. To address this gap, this review article conducts a systematic analysis of hashtag recommendation systems, comprehensively examining recent advancements across several dimensions. We investigate unimodal versus multimodal methodologies, diverse problem formulations, filtering strategies, methodological evolution from traditional frequency-based models to advanced deep learning architectures. Furthermore, we critically evaluate performance assessment paradigms, including quantitative metrics, qualitative analyses, and hybrid evaluation frameworks. Our analysis underscores a paradigm shift toward transformer-based deep learning models, which harness contextual and semantic features to achieve superior recommendation accuracy. Key challenges such as data sparsity, cold-start scenarios, polysemy, and model explainability are rigorously discussed, alongside practical applications in tweet classification, sentiment analysis, and content popularity prediction. By synthesizing insights from diverse methodological and platform-specific perspectives, this survey provides a structured taxonomy of current research, identifies unresolved gaps, and proposes future directions for developing adaptive, user-centric recommendation systems.
Sentiment and Hashtag-aware Attentive Deep Neural Network for Multimodal Post Popularity Prediction
Dec 14, 2024Social media users articulate their opinions on a broad spectrum of subjects and share their experiences through posts comprising multiple modes of expression, leading to a notable surge in such multimodal content on social media platforms. Nonetheless, accurately forecasting the popularity of these posts presents a considerable challenge. Prevailing methodologies primarily center on the content itself, thereby overlooking the wealth of information encapsulated within alternative modalities such as visual demographics, sentiments conveyed through hashtags and adequately modeling the intricate relationships among hashtags, texts, and accompanying images. This oversight limits the ability to capture emotional connection and audience relevance, significantly influencing post popularity. To address these limitations, we propose a seNtiment and hAshtag-aware attentive deep neuRal netwoRk for multimodAl posT pOpularity pRediction, herein referred to as NARRATOR that extracts visual demographics from faces appearing in images and discerns sentiment from hashtag usage, providing a more comprehensive understanding of the factors influencing post popularity Moreover, we introduce a hashtag-guided attention mechanism that leverages hashtags as navigational cues, guiding the models focus toward the most pertinent features of textual and visual modalities, thus aligning with target audience interests and broader social media context. Experimental results demonstrate that NARRATOR outperforms existing methods by a significant margin on two real-world datasets. Furthermore, ablation studies underscore the efficacy of integrating visual demographics, sentiment analysis of hashtags, and hashtag-guided attention mechanisms in enhancing the performance of post popularity prediction, thereby facilitating increased audience relevance, emotional engagement, and aesthetic appeal.
AMuSeD: An Attentive Deep Neural Network for Multimodal Sarcasm Detection Incorporating Bi-modal Data Augmentation
Dec 13, 2024



Detecting sarcasm effectively requires a nuanced understanding of context, including vocal tones and facial expressions. The progression towards multimodal computational methods in sarcasm detection, however, faces challenges due to the scarcity of data. To address this, we present AMuSeD (Attentive deep neural network for MUltimodal Sarcasm dEtection incorporating bi-modal Data augmentation). This approach utilizes the Multimodal Sarcasm Detection Dataset (MUStARD) and introduces a two-phase bimodal data augmentation strategy. The first phase involves generating varied text samples through Back Translation from several secondary languages. The second phase involves the refinement of a FastSpeech 2-based speech synthesis system, tailored specifically for sarcasm to retain sarcastic intonations. Alongside a cloud-based Text-to-Speech (TTS) service, this Fine-tuned FastSpeech 2 system produces corresponding audio for the text augmentations. We also investigate various attention mechanisms for effectively merging text and audio data, finding self-attention to be the most efficient for bimodal integration. Our experiments reveal that this combined augmentation and attention approach achieves a significant F1-score of 81.0% in text-audio modalities, surpassing even models that use three modalities from the MUStARD dataset.
MMCFND: Multimodal Multilingual Caption-aware Fake News Detection for Low-resource Indic Languages
Oct 14, 2024
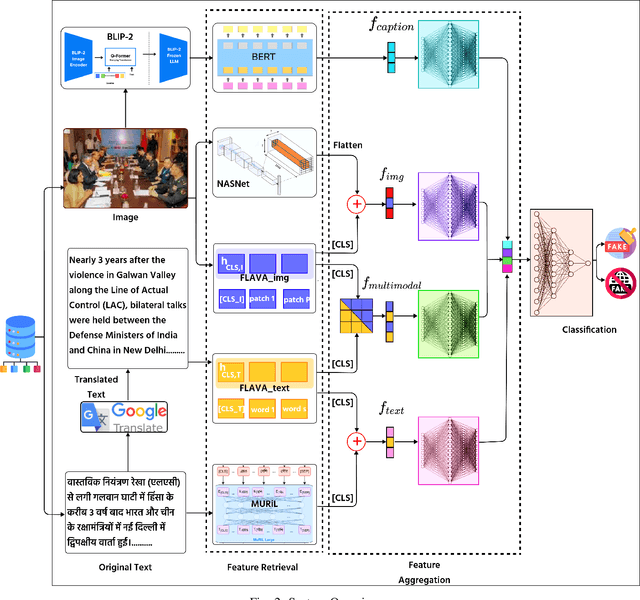
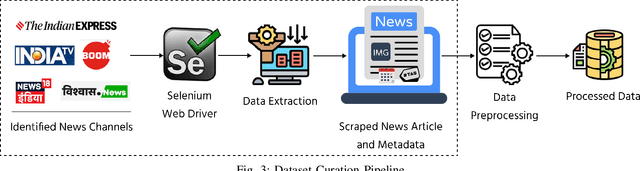
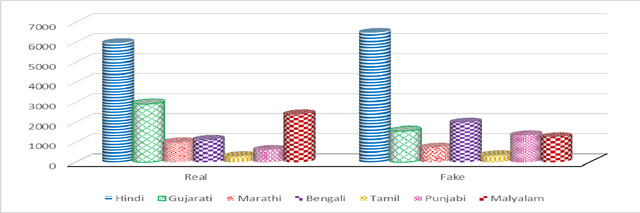
The widespread dissemination of false information through manipulative tactics that combine deceptive text and images threatens the integrity of reliable sources of information. While there has been research on detecting fake news in high resource languages using multimodal approaches, methods for low resource Indic languages primarily rely on textual analysis. This difference highlights the need for robust methods that specifically address multimodal fake news in Indic languages, where the lack of extensive datasets and tools presents a significant obstacle to progress. To this end, we introduce the Multimodal Multilingual dataset for Indic Fake News Detection (MMIFND). This meticulously curated dataset consists of 28,085 instances distributed across Hindi, Bengali, Marathi, Malayalam, Tamil, Gujarati and Punjabi. We further propose the Multimodal Multilingual Caption-aware framework for Fake News Detection (MMCFND). MMCFND utilizes pre-trained unimodal encoders and pairwise encoders from a foundational model that aligns vision and language, allowing for extracting deep representations from visual and textual components of news articles. The multimodal fusion encoder in the foundational model integrates text and image representations derived from its pairwise encoders to generate a comprehensive cross modal representation. Furthermore, we generate descriptive image captions that provide additional context to detect inconsistencies and manipulations. The retrieved features are then fused and fed into a classifier to determine the authenticity of news articles. The curated dataset can potentially accelerate research and development in low resource environments significantly. Thorough experimentation on MMIFND demonstrates that our proposed framework outperforms established methods for extracting relevant fake news detection features.
A Hybrid Filtering for Micro-video Hashtag Recommendation using Graph-based Deep Neural Network
Oct 14, 2024


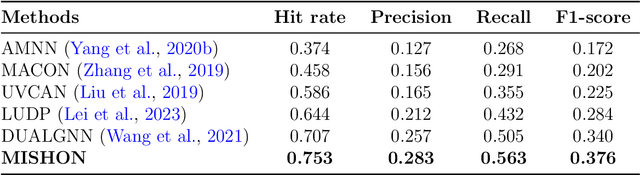
Due to the growing volume of user generated content, hashtags are employed as topic indicators to manage content efficiently on social media platforms. However, finding these vital topics is challenging in microvideos since they contain substantial information in a short duration. Existing methods that recommend hashtags for microvideos primarily focus on content and personalization while disregarding relatedness among users. Moreover, the cold start user issue prevails in hashtag recommendation systems. Considering the above, we propose a hybrid filtering based MIcro-video haSHtag recommendatiON MISHON technique to recommend hashtags for micro-videos. Besides content based filtering, we employ user-based collaborative filtering to enhance recommendations. Since hashtags reflect users topical interests, we find similar users based on historical tagging behavior to model user relatedness. We employ a graph-based deep neural network to model user to user, modality to modality, and user to modality interactions. We then use refined modality specific and user representations to recommend pertinent hashtags for microvideos. The empirical results on three real world datasets demonstrate that MISHON attains a comparative enhancement of 3.6, 2.8, and 6.5 reported in percentage concerning the F1 score, respectively. Since cold start users exist whose historical tagging information is unavailable, we also propose a content and social influence based technique to model the relatedness of cold start users with influential users. The proposed solution shows a relative improvement of 15.8 percent in the F1 score over its content only counterpart. These results show that the proposed framework mitigates the cold start user problem.
A Comprehensive Survey of Mamba Architectures for Medical Image Analysis: Classification, Segmentation, Restoration and Beyond
Oct 03, 2024Mamba, a special case of the State Space Model, is gaining popularity as an alternative to template-based deep learning approaches in medical image analysis. While transformers are powerful architectures, they have drawbacks, including quadratic computational complexity and an inability to address long-range dependencies efficiently. This limitation affects the analysis of large and complex datasets in medical imaging, where there are many spatial and temporal relationships. In contrast, Mamba offers benefits that make it well-suited for medical image analysis. It has linear time complexity, which is a significant improvement over transformers. Mamba processes longer sequences without attention mechanisms, enabling faster inference and requiring less memory. Mamba also demonstrates strong performance in merging multimodal data, improving diagnosis accuracy and patient outcomes. The organization of this paper allows readers to appreciate the capabilities of Mamba in medical imaging step by step. We begin by defining core concepts of SSMs and models, including S4, S5, and S6, followed by an exploration of Mamba architectures such as pure Mamba, U-Net variants, and hybrid models with convolutional neural networks, transformers, and Graph Neural Networks. We also cover Mamba optimizations, techniques and adaptations, scanning, datasets, applications, experimental results, and conclude with its challenges and future directions in medical imaging. This review aims to demonstrate the transformative potential of Mamba in overcoming existing barriers within medical imaging while paving the way for innovative advancements in the field. A comprehensive list of Mamba architectures applied in the medical field, reviewed in this work, is available at Github.
A multimedia recommendation model based on collaborative graph
May 30, 2022
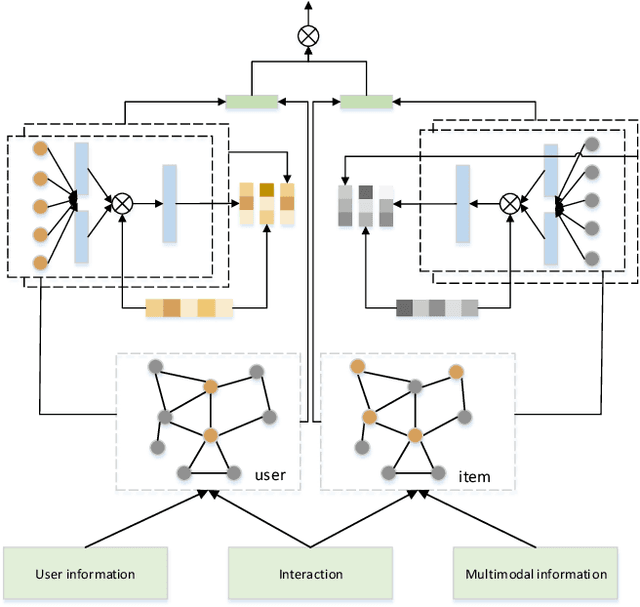
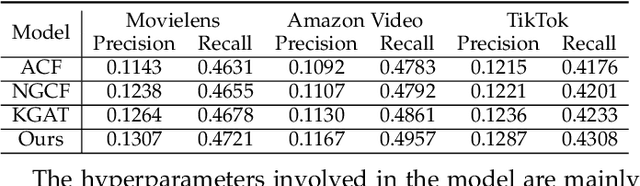
As one of the main solutions to the information overload problem, recommender systems are widely used in daily life. In the recent emerging micro-video recommendation scenario, micro-videos contain rich multimedia information, involving text, image, video and other multimodal data, and these rich multimodal information conceals users' deep interest in the items. Most of the current recommendation algorithms based on multimodal data use multimodal information to expand the information on the item side, but ignore the different preferences of users for different modal information, and lack the fine-grained mining of the internal connection of multimodal information. To investigate the problems in the micro-video recommendr system mentioned above, we design a hybrid recommendation model based on multimodal information, introduces multimodal information and user-side auxiliary information in the network structure, fully explores the deep interest of users, measures the importance of each dimension of user and item feature representation in the scoring prediction task, makes the application of graph neural network in the recommendation system is improved by using an attention mechanism to fuse the multi-layer state output information, allowing the shallow structural features provided by the intermediate layer to better participate in the prediction task. The recommendation accuracy is improved compared with the traditional recommendation algorithm on different data sets, and the feasibility and effectiveness of our model is verified.