 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCFND: Multimodal Multilingual Caption-aware Fake News Detection for Low-resource Indic Languages
Oct 14, 2024
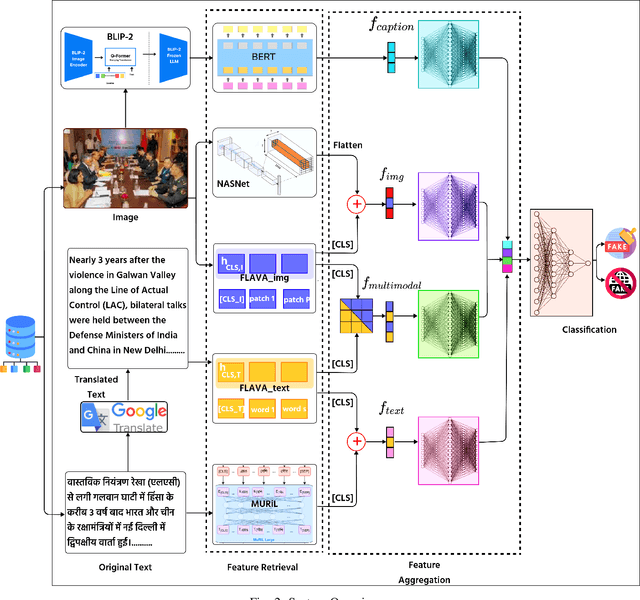
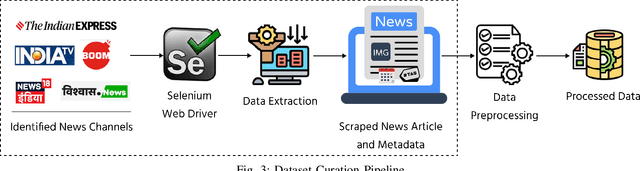
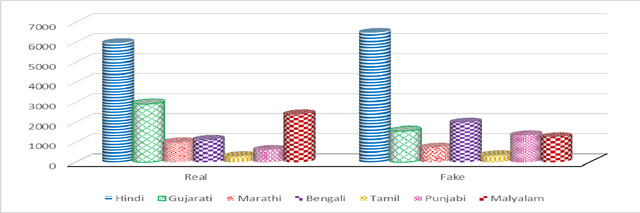
The widespread dissemination of false information through manipulative tactics that combine deceptive text and images threatens the integrity of reliable sources of information. While there has been research on detecting fake news in high resource languages using multimodal approaches, methods for low resource Indic languages primarily rely on textual analysis. This difference highlights the need for robust methods that specifically address multimodal fake news in Indic languages, where the lack of extensive datasets and tools presents a significant obstacle to progress. To this end, we introduce the Multimodal Multilingual dataset for Indic Fake News Detection (MMIFND). This meticulously curated dataset consists of 28,085 instances distributed across Hindi, Bengali, Marathi, Malayalam, Tamil, Gujarati and Punjabi. We further propose the Multimodal Multilingual Caption-aware framework for Fake News Detection (MMCFND). MMCFND utilizes pre-trained unimodal encoders and pairwise encoders from a foundational model that aligns vision and language, allowing for extracting deep representations from visual and textual components of news articles. The multimodal fusion encoder in the foundational model integrates text and image representations derived from its pairwise encoders to generate a comprehensive cross modal representation. Furthermore, we generate descriptive image captions that provide additional context to detect inconsistencies and manipulations. The retrieved features are then fused and fed into a classifier to determine the authenticity of news articles. The curated dataset can potentially accelerate research and development in low resource environments significantly. Thorough experimentation on MMIFND demonstrates that our proposed framework outperforms established methods for extracting relevant fake news detection features.