 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-temporal multi-spectral attention-augmented deep convolution neural network with contrastive learning for crop yield prediction
Sep 19, 2025



Precise yield prediction is essential for agricultural sustainability and food security. However, climate change complicates accurate yield prediction by affecting major factors such as weather conditions, soil fertility, and farm management systems. Advances in technology have played an essential role in overcoming these challenges by leveraging satellite monitoring and data analysis for precise yield estimation. Current methods rely on spatio-temporal data for predicting crop yield, but they often struggle with multi-spectral data, which is crucial for evaluating crop health and growth patterns. To resolve this challenge, we propose a novel Multi-Temporal Multi-Spectral Yield Prediction Network, MTMS-YieldNet, that integrates spectral data with spatio-temporal information to effectively capture the correlations and dependencies between them. While existing methods that rely on pre-trained models trained on general visual data, MTMS-YieldNet utilizes contrastive learning for feature discrimination during pre-training, focusing on capturing spatial-spectral patterns and spatio-temporal dependencies from remote sensing data. Both quantitative and qualitative assessments highlight the excellence of the proposed MTMS-YieldNet over seven existing state-of-the-art methods. MTMS-YieldNet achieves MAPE scores of 0.336 on Sentinel-1, 0.353 on Landsat-8, and an outstanding 0.331 on Sentinel-2, demonstrating effective yield prediction performance across diverse climatic and seasonal conditions. The outstanding performance of MTMS-YieldNet improves yield predictions and provides valuable insights that can assist farmers in making better decisions, potentially improving crop yields.
Two Stage Context Learning with Large Language Models for Multimodal Stance Detection on Climate Change
Sep 09, 2025With the rapid proliferation of information across digital platforms, stance detection has emerged as a pivotal challenge in social media analysis. While most of the existing approaches focus solely on textual data, real-world social media content increasingly combines text with visual elements creating a need for advanced multimodal methods. To address this gap, we propose a multimodal stance detection framework that integrates textual and visual information through a hierarchical fusion approach. Our method first employs a Large Language Model to retrieve stance-relevant summaries from source text, while a domain-aware image caption generator interprets visual content in the context of the target topic. These modalities are then jointly modeled along with the reply text, through a specialized transformer module that captures interactions between the texts and images. The proposed modality fusion framework integrates diverse modalities to facilitate robust stance classification. We evaluate our approach on the MultiClimate dataset, a benchmark for climate change-related stance detection containing aligned video frames and transcripts. We achieve accuracy of 76.2%, precision of 76.3%, recall of 76.2% and F1-score of 76.2%, respectively, outperforming existing state-of-the-art approaches.
Large Language Models Meet Stance Detection: A Survey of Tasks, Methods, Applications, Challenges and Future Directions
May 13, 2025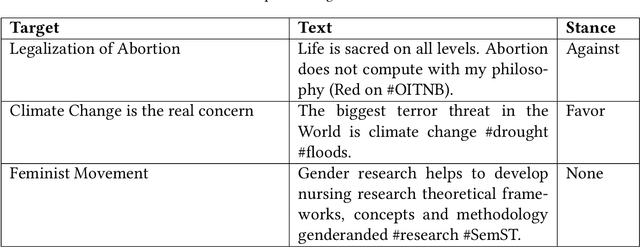
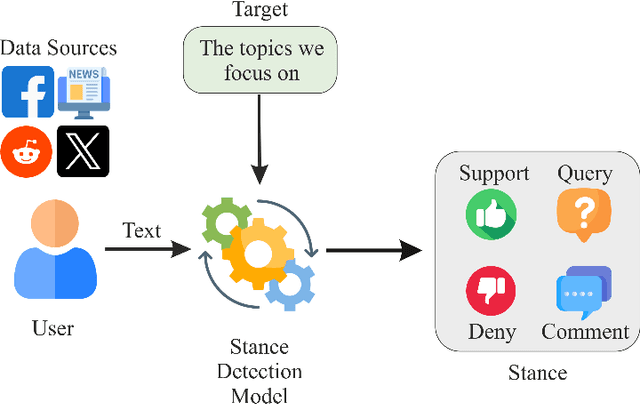

Stance detection is essential for understanding subjective content across various platforms such as social media, news articles, and online reviews. Recent advances in Large Language Models (LLMs) have revolutionized stance detection by introducing novel capabilities in contextual understanding, cross-domain generalization, and multimodal analysis. Despite these progressions, existing surveys often lack comprehensive coverage of approaches that specifically leverage LLMs for stance detection. To bridge this critical gap, our review article conducts a systematic analysis of stance detection, comprehensively examining recent advancements of LLMs transforming the field, including foundational concepts, methodologies, datasets, applications, and emerging challenges. We present a novel taxonomy for LLM-based stance detection approaches, structured along three key dimensions: 1) learning methods, including supervised, unsupervised, few-shot, and zero-shot; 2) data modalities, such as unimodal, multimodal, and hybrid; and 3) target relationships, encompassing in-target, cross-target, and multi-target scenarios. Furthermore, we discuss the evaluation techniques and analyze benchmark datasets and performance trends, highlighting the strengths and limitations of different architectures. Key applications in misinformation detection, political analysis, public health monitoring, and social media moderation are discussed. Finally, we identify critical challenges such as implicit stance expression, cultural biases, and computational constraints, while outlining promising future directions, including explainable stance reasoning, low-resource adaptation, and real-time deployment frameworks. Our survey highlights emerging trends, open challenges, and future directions to guide researchers and practitioners in developing next-generation stance detection systems powered by large language models.
MMCFND: Multimodal Multilingual Caption-aware Fake News Detection for Low-resource Indic Languages
Oct 14, 2024
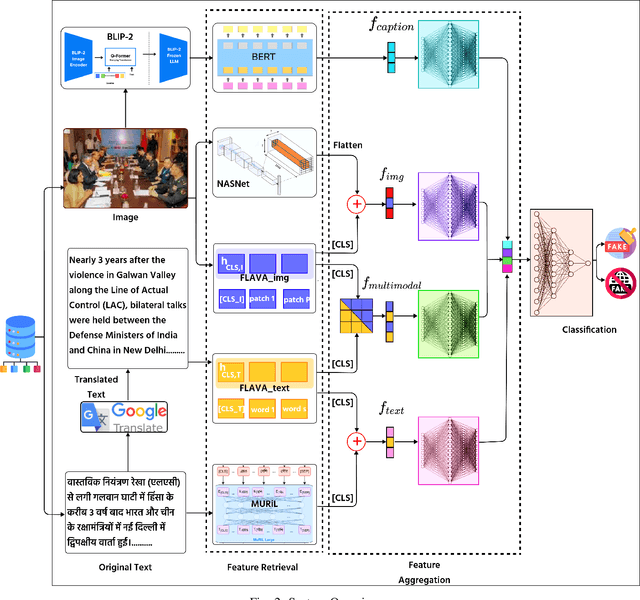
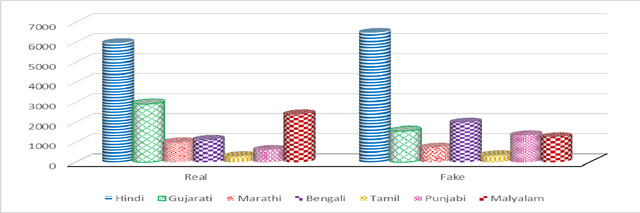
The widespread dissemination of false information through manipulative tactics that combine deceptive text and images threatens the integrity of reliable sources of information. While there has been research on detecting fake news in high resource languages using multimodal approaches, methods for low resource Indic languages primarily rely on textual analysis. This difference highlights the need for robust methods that specifically address multimodal fake news in Indic languages, where the lack of extensive datasets and tools presents a significant obstacle to progress. To this end, we introduce the Multimodal Multilingual dataset for Indic Fake News Detection (MMIFND). This meticulously curated dataset consists of 28,085 instances distributed across Hindi, Bengali, Marathi, Malayalam, Tamil, Gujarati and Punjabi. We further propose the Multimodal Multilingual Caption-aware framework for Fake News Detection (MMCFND). MMCFND utilizes pre-trained unimodal encoders and pairwise encoders from a foundational model that aligns vision and language, allowing for extracting deep representations from visual and textual components of news articles. The multimodal fusion encoder in the foundational model integrates text and image representations derived from its pairwise encoders to generate a comprehensive cross modal representation. Furthermore, we generate descriptive image captions that provide additional context to detect inconsistencies and manipulations. The retrieved features are then fused and fed into a classifier to determine the authenticity of news articles. The curated dataset can potentially accelerate research and development in low resource environments significantly. Thorough experimentation on MMIFND demonstrates that our proposed framework outperforms established methods for extracting relevant fake news detection features.
A Social Context-aware Graph-based Multimodal Attentive Learning Framework for Disaster Content Classification during Emergencies
Oct 11, 2024



In times of crisis, the prompt and precise classification of disaster-related information shared on social media platforms is crucial for effective disaster response and public safety. During such critical events, individuals use social media to communicate, sharing multimodal textual and visual content. However, due to the significant influx of unfiltered and diverse data, humanitarian organizations face challenges in leveraging this information efficiently. Existing methods for classifying disaster-related content often fail to model users' credibility, emotional context, and social interaction information, which are essential for accurate classification. To address this gap, we propose CrisisSpot, a method that utilizes a Graph-based Neural Network to capture complex relationships between textual and visual modalities, as well as Social Context Features to incorporate user-centric and content-centric information. We also introduce Inverted Dual Embedded Attention (IDEA), which captures both harmonious and contrasting patterns within the data to enhance multimodal interactions and provide richer insights. Additionally, we present TSEqD (Turkey-Syria Earthquake Dataset), a large annotated dataset for a single disaster event, containing 10,352 samples. Through extensive experiments, CrisisSpot demonstrated significant improvements, achieving an average F1-score gain of 9.45% and 5.01% compared to state-of-the-art methods on the publicly available CrisisMMD dataset and the TSEqD dataset, respectively.