 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-SemiS: Hierarchical Fusion of Semi and Self-Supervised Learning for Knee Osteoarthritis Severity Grading
Apr 25, 2026Knee osteoarthritis (KOA) is a degenerative joint disease that can lead to chronic pain, reduced mobility, and long-term disability. Automated severity grading from knee radiographs can support early assessment, but current methods heavily depend on large labeled datasets and remain sensitive to class imbalance, noisy samples, and variability in clinical annotations. To alleviate these limitations, we propose a Hierarchical fusion of Semi-Supervised framework with Self-Supervision (H-SemiS) for KOA severity grading in knee X-ray samples using limited annotated data. Rather than treating severity grading as a flat multi-class problem, H-SemiS decomposes the task into a sequence of binary sub-tasks within a semi-supervised teacher-student architecture, directly mitigating the impact of class imbalance. To further enhance feature learning from unlabeled data, the framework integrates an adversarial self-supervised reconstruction module that encourages the network to capture robust anatomical structures. In parallel, a teacher-student design with quantum-inspired feature mixing improves discrimination boundaries between adjacent grades when pseudo-labels are noisy. We comprehensively evaluate H-SemiS on two challenging multi-class datasets and assess its generalizability on two binary-class datasets. Our experimental results demonstrate the superiority of the proposed H-SemiS framework across multiple evaluation metrics, consistently outperforming several competing baselines and state-of-the-art methods. The code is publicly available at https://github.com/chandravardhan-singh-raghaw/H-SemiS.
X-MuTeST: A Multilingual Benchmark for Explainable Hate Speech Detection and A Novel LLM-consulted Explanation Framework
Jan 06, 2026Hate speech detection on social media faces challenges in both accuracy and explainability, especially for underexplored Indic languages. We propose a novel explainability-guided training framework, X-MuTeST (eXplainable Multilingual haTe Speech deTection), for hate speech detection that combines high-level semantic reasoning from large language models (LLMs) with traditional attention-enhancing techniques. We extend this research to Hindi and Telugu alongside English by providing benchmark human-annotated rationales for each word to justify the assigned class label. The X-MuTeST explainability method computes the difference between the prediction probabilities of the original text and those of unigrams, bigrams, and trigrams. Final explanations are computed as the union between LLM explanations and X-MuTeST explanations. We show that leveraging human rationales during training enhances both classification performance and explainability. Moreover, combining human rationales with our explainability method to refine the model attention yields further improvements. We evaluate explainability using Plausibility metrics such as Token-F1 and IOU-F1 and Faithfulness metrics such as Comprehensiveness and Sufficiency. By focusing on under-resourced languages, our work advances hate speech detection across diverse linguistic contexts. Our dataset includes token-level rationale annotations for 6,004 Hindi, 4,492 Telugu, and 6,334 English samples. Data and code are available on https://github.com/ziarehman30/X-MuTeST
* Accepted in the proceedings of AAAI 2026
Uncertainty-aware Semi-supervised Ensemble Teacher Framework for Multilingual Depression Detection
Dec 31, 2025Detecting depression from social media text is still a challenging task. This is due to different language styles, informal expression, and the lack of annotated data in many languages. To tackle these issues, we propose, Semi-SMDNet, a strong Semi-Supervised Multilingual Depression detection Network. It combines teacher-student pseudo-labelling, ensemble learning, and augmentation of data. Our framework uses a group of teacher models. Their predictions come together through soft voting. An uncertainty-based threshold filters out low-confidence pseudo-labels to reduce noise and improve learning stability. We also use a confidence-weighted training method that focuses on reliable pseudo-labelled samples. This greatly boosts robustness across languages. Tests on Arabic, Bangla, English, and Spanish datasets show that our approach consistently beats strong baselines. It significantly reduces the performance gap between settings that have plenty of resources and those that do not. Detailed experiments and studies confirm that our framework is effective and can be used in various situations. This shows that it is suitable for scalable, cross-language mental health monitoring where labelled resources are limited.
Analytical and DNN-Aided Performance Evaluation of IRS-Assisted THz Communication Systems
Dec 10, 2025This paper investigates the performance of an intelligent reflecting surface (IRS)-assisted terahertz (THz) communication system, where the IRS facilitates connectivity between the source and destination nodes in the absence of a direct transmission path. The source-IRS and IRS-destination links are subject to various challenges, including atmospheric attenuation, asymmetric $α$-$μ$ distributed small-scale fading, and beam misalignment-induced pointing errors. The IRS link is characterized using the Laguerre series expansion (LSE) approximation, while both the source-IRS and IRS-destination channels are modeled as independent and identically distributed (i.i.d.) $α$-$μ$ fading channels. Furthermore, closed-form analytical expressions are derived for the outage probability (OP), average channel capacity (ACC), and average symbol error rate (ASER) for rectangular QAM (RQAM) and hexagonal QAM (HQAM) schemes over the end-to-end (e2e) link. The impact of random co-phasing and phase quantization errors are also examined. In addition to the theoretical analysis, deep neural network-based frameworks are developed to predict key performance metrics, facilitating fast and accurate system evaluation without computationally intensive analytical computations. Moreover, the asymptotic analysis in the high-signal-to-noise ratio (SNR) regime yields closed-form expressions for coding gain and diversity order, providing further insights into performance trends. Finally, Monte Carlo simulations validate the theoretical formulations and present a comprehensive assessment of system behavior under practical conditions.
3D-HQAM Constellation Design and Performance Evaluation under AWGN
Nov 14, 2025



This paper proposes a simple and effective method for constructing higher-order three-dimensional (3D) signal constellations, aiming to enhance the reliability of digital communication systems. The approach systematically extends the conventional two-dimensional hexagonal quadrature amplitude modulation (2D-HQAM) constellation into a 3D-HQAM signal space, forming structured lattice configurations. To address the increased decision complexity resulting from a larger number of constellation points, a dimension reduction (DR) technique is introduced, allowing the derivation of closed-form symbol error probability (SEP) expressions under additive white Gaussian noise (AWGN) conditions. Theoretical SEPs closely match simulation results, validating the accuracy of the proposed method. The minimum Euclidean distance (MED) of the 3D constellations shows a minimum increase of 12.14% over 2D constellation for 8-HQAM, reaching up to 160.81% for 1024-HQAM constellations. This significant improvement in MED leads to enhanced error performance. Therefore, the proposed 3D constellations are promising candidates for high-quality and reliable next-generation digital communication systems.
A multi-temporal multi-spectral attention-augmented deep convolution neural network with contrastive learning for crop yield prediction
Sep 19, 2025



Precise yield prediction is essential for agricultural sustainability and food security. However, climate change complicates accurate yield prediction by affecting major factors such as weather conditions, soil fertility, and farm management systems. Advances in technology have played an essential role in overcoming these challenges by leveraging satellite monitoring and data analysis for precise yield estimation. Current methods rely on spatio-temporal data for predicting crop yield, but they often struggle with multi-spectral data, which is crucial for evaluating crop health and growth patterns. To resolve this challenge, we propose a novel Multi-Temporal Multi-Spectral Yield Prediction Network, MTMS-YieldNet, that integrates spectral data with spatio-temporal information to effectively capture the correlations and dependencies between them. While existing methods that rely on pre-trained models trained on general visual data, MTMS-YieldNet utilizes contrastive learning for feature discrimination during pre-training, focusing on capturing spatial-spectral patterns and spatio-temporal dependencies from remote sensing data. Both quantitative and qualitative assessments highlight the excellence of the proposed MTMS-YieldNet over seven existing state-of-the-art methods. MTMS-YieldNet achieves MAPE scores of 0.336 on Sentinel-1, 0.353 on Landsat-8, and an outstanding 0.331 on Sentinel-2, demonstrating effective yield prediction performance across diverse climatic and seasonal conditions. The outstanding performance of MTMS-YieldNet improves yield predictions and provides valuable insights that can assist farmers in making better decisions, potentially improving crop yields.
Two Stage Context Learning with Large Language Models for Multimodal Stance Detection on Climate Change
Sep 09, 2025With the rapid proliferation of information across digital platforms, stance detection has emerged as a pivotal challenge in social media analysis. While most of the existing approaches focus solely on textual data, real-world social media content increasingly combines text with visual elements creating a need for advanced multimodal methods. To address this gap, we propose a multimodal stance detection framework that integrates textual and visual information through a hierarchical fusion approach. Our method first employs a Large Language Model to retrieve stance-relevant summaries from source text, while a domain-aware image caption generator interprets visual content in the context of the target topic. These modalities are then jointly modeled along with the reply text, through a specialized transformer module that captures interactions between the texts and images. The proposed modality fusion framework integrates diverse modalities to facilitate robust stance classification. We evaluate our approach on the MultiClimate dataset, a benchmark for climate change-related stance detection containing aligned video frames and transcripts. We achieve accuracy of 76.2%, precision of 76.3%, recall of 76.2% and F1-score of 76.2%, respectively, outperforming existing state-of-the-art approaches.
Emotion-aware Dual Cross-Attentive Neural Network with Label Fusion for Stance Detection in Misinformative Social Media Content
May 27, 2025The rapid evolution of social media has generated an overwhelming volume of user-generated content, conveying implicit opinions and contributing to the spread of misinformation. The method aims to enhance the detection of stance where misinformation can polarize user opinions. Stance detection has emerged as a crucial approach to effectively analyze underlying biases in shared information and combating misinformation. This paper proposes a novel method for \textbf{S}tance \textbf{P}rediction through a \textbf{L}abel-fused dual cross-\textbf{A}ttentive \textbf{E}motion-aware neural \textbf{Net}work (SPLAENet) in misinformative social media user-generated content. The proposed method employs a dual cross-attention mechanism and a hierarchical attention network to capture inter and intra-relationships by focusing on the relevant parts of source text in the context of reply text and vice versa. We incorporate emotions to effectively distinguish between different stance categories by leveraging the emotional alignment or divergence between the texts. We also employ label fusion that uses distance-metric learning to align extracted features with stance labels, improving the method's ability to accurately distinguish between stances. Extensive experiments demonstrate the significant improvements achieved by SPLAENet over existing state-of-the-art methods. SPLAENet demonstrates an average gain of 8.92\% in accuracy and 17.36\% in F1-score on the RumourEval dataset. On the SemEval dataset, it achieves average gains of 7.02\% in accuracy and 10.92\% in F1-score. On the P-stance dataset, it demonstrates average gains of 10.03\% in accuracy and 11.18\% in F1-score. These results validate the effectiveness of the proposed method for stance detection in the context of misinformative social media content.
Large Language Models Meet Stance Detection: A Survey of Tasks, Methods, Applications, Challenges and Future Directions
May 13, 2025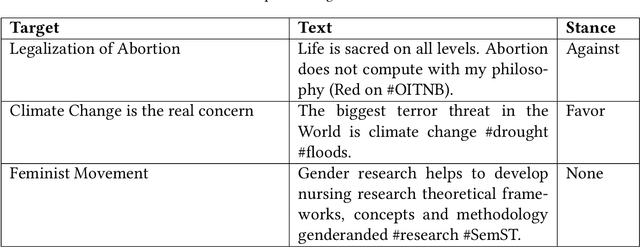

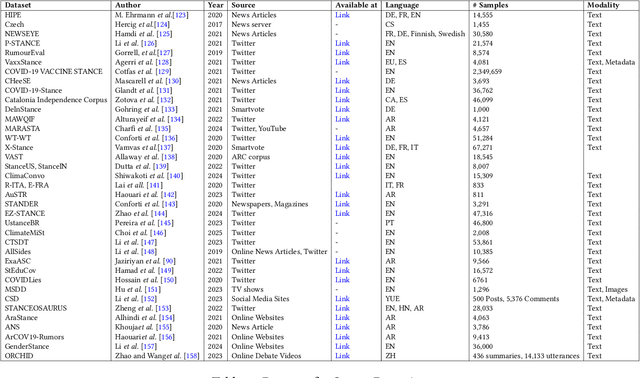
Stance detection is essential for understanding subjective content across various platforms such as social media, news articles, and online reviews. Recent advances in Large Language Models (LLMs) have revolutionized stance detection by introducing novel capabilities in contextual understanding, cross-domain generalization, and multimodal analysis. Despite these progressions, existing surveys often lack comprehensive coverage of approaches that specifically leverage LLMs for stance detection. To bridge this critical gap, our review article conducts a systematic analysis of stance detection, comprehensively examining recent advancements of LLMs transforming the field, including foundational concepts, methodologies, datasets, applications, and emerging challenges. We present a novel taxonomy for LLM-based stance detection approaches, structured along three key dimensions: 1) learning methods, including supervised, unsupervised, few-shot, and zero-shot; 2) data modalities, such as unimodal, multimodal, and hybrid; and 3) target relationships, encompassing in-target, cross-target, and multi-target scenarios. Furthermore, we discuss the evaluation techniques and analyze benchmark datasets and performance trends, highlighting the strengths and limitations of different architectures. Key applications in misinformation detection, political analysis, public health monitoring, and social media moderation are discussed. Finally, we identify critical challenges such as implicit stance expression, cultural biases, and computational constraints, while outlining promising future directions, including explainable stance reasoning, low-resource adaptation, and real-time deployment frameworks. Our survey highlights emerging trends, open challenges, and future directions to guide researchers and practitioners in developing next-generation stance detection systems powered by large language models.
A Comprehensive Review on Hashtag Recommendation: From Traditional to Deep Learning and Beyond
Mar 25, 2025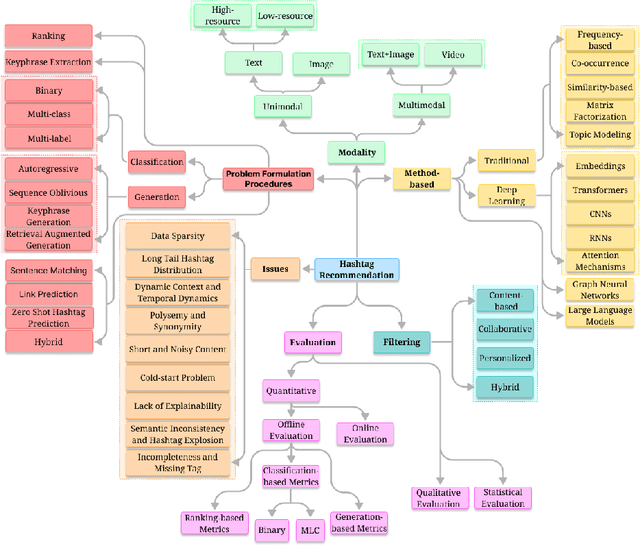
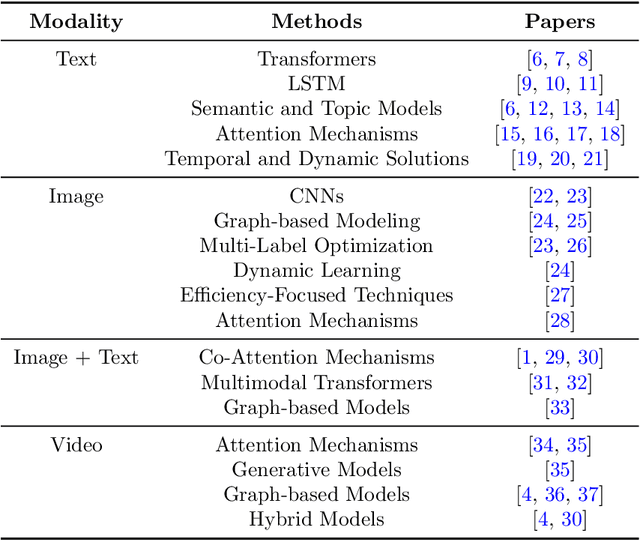
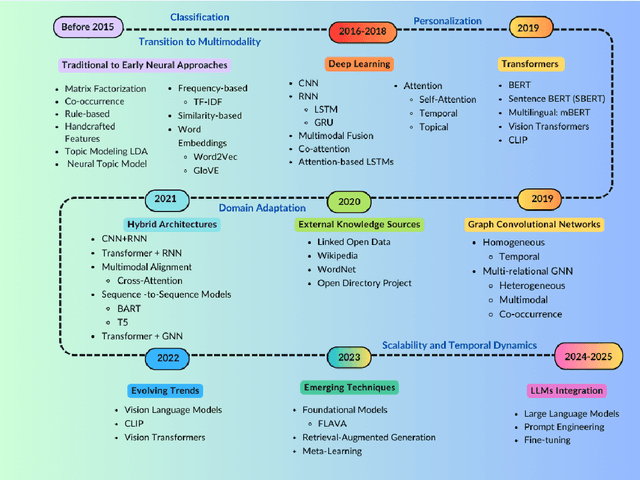

The exponential growth of user-generated content on social media platforms has precipitated significant challenges in information management, particularly in content organization, retrieval, and discovery. Hashtags, as a fundamental categorization mechanism, play a pivotal role in enhancing content visibility and user engagement. However, the development of accurate and robust hashtag recommendation systems remains a complex and evolving research challenge. Existing surveys in this domain are limited in scope and recency, focusing narrowly on specific platforms, methodologies, or timeframes. To address this gap, this review article conducts a systematic analysis of hashtag recommendation systems, comprehensively examining recent advancements across several dimensions. We investigate unimodal versus multimodal methodologies, diverse problem formulations, filtering strategies, methodological evolution from traditional frequency-based models to advanced deep learning architectures. Furthermore, we critically evaluate performance assessment paradigms, including quantitative metrics, qualitative analyses, and hybrid evaluation frameworks. Our analysis underscores a paradigm shift toward transformer-based deep learning models, which harness contextual and semantic features to achieve superior recommendation accuracy. Key challenges such as data sparsity, cold-start scenarios, polysemy, and model explainability are rigorously discussed, alongside practical applications in tweet classification, sentiment analysis, and content popularity prediction. By synthesizing insights from diverse methodological and platform-specific perspectives, this survey provides a structured taxonomy of current research, identifies unresolved gaps, and proposes future directions for developing adaptive, user-centric recommendation systems.