 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Aware Multilingual Abusive Content Detection in Social Media
Oct 26, 2024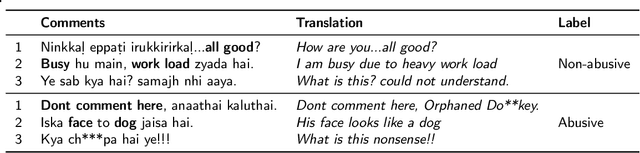
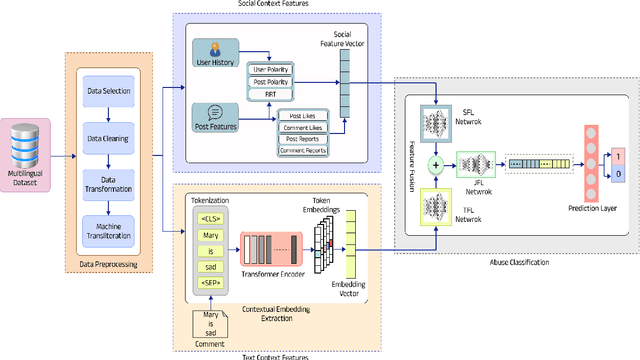
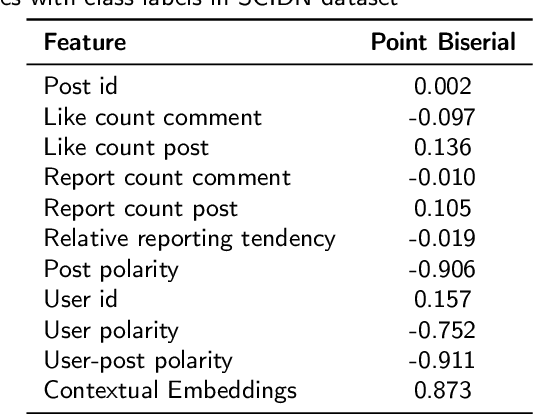
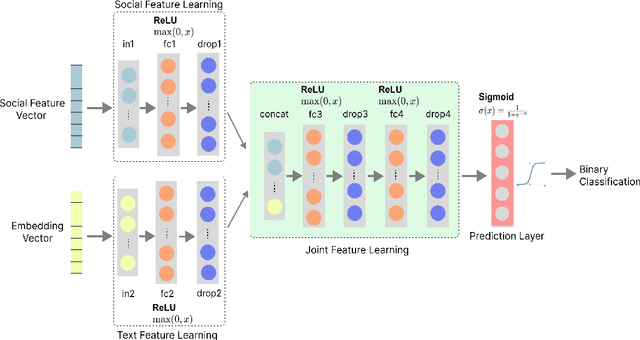
Despite growing efforts to halt distasteful content on social media, multilingualism has added a new dimension to this problem. The scarcity of resources makes the challenge even greater when it comes to low-resource languages. This work focuses on providing a novel method for abusive content detection in multiple low-resource Indic languages. Our observation indicates that a post's tendency to attract abusive comments, as well as features such as user history and social context, significantly aid in the detection of abusive content. The proposed method first learns social and text context features in two separate modules. The integrated representation from these modules is learned and used for the final prediction. To evaluate the performance of our method against different classical and state-of-the-art methods, we have performed extensive experiments on SCIDN and MACI datasets consisting of 1.5M and 665K multilingual comments, respectively. Our proposed method outperforms state-of-the-art baseline methods with an average increase of 4.08% and 9.52% in F1-scores on SCIDN and MACI datasets, respectively.