 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment and Hashtag-aware Attentive Deep Neural Network for Multimodal Post Popularity Prediction
Dec 14, 2024Social media users articulate their opinions on a broad spectrum of subjects and share their experiences through posts comprising multiple modes of expression, leading to a notable surge in such multimodal content on social media platforms. Nonetheless, accurately forecasting the popularity of these posts presents a considerable challenge. Prevailing methodologies primarily center on the content itself, thereby overlooking the wealth of information encapsulated within alternative modalities such as visual demographics, sentiments conveyed through hashtags and adequately modeling the intricate relationships among hashtags, texts, and accompanying images. This oversight limits the ability to capture emotional connection and audience relevance, significantly influencing post popularity. To address these limitations, we propose a seNtiment and hAshtag-aware attentive deep neuRal netwoRk for multimodAl posT pOpularity pRediction, herein referred to as NARRATOR that extracts visual demographics from faces appearing in images and discerns sentiment from hashtag usage, providing a more comprehensive understanding of the factors influencing post popularity Moreover, we introduce a hashtag-guided attention mechanism that leverages hashtags as navigational cues, guiding the models focus toward the most pertinent features of textual and visual modalities, thus aligning with target audience interests and broader social media context. Experimental results demonstrate that NARRATOR outperforms existing methods by a significant margin on two real-world datasets. Furthermore, ablation studies underscore the efficacy of integrating visual demographics, sentiment analysis of hashtags, and hashtag-guided attention mechanisms in enhancing the performance of post popularity prediction, thereby facilitating increased audience relevance, emotional engagement, and aesthetic appeal.
$(ε, δ)$-Differentially Private Partial Least Squares Regression
Dec 12, 2024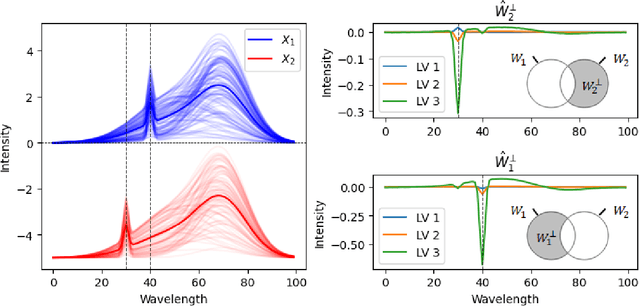
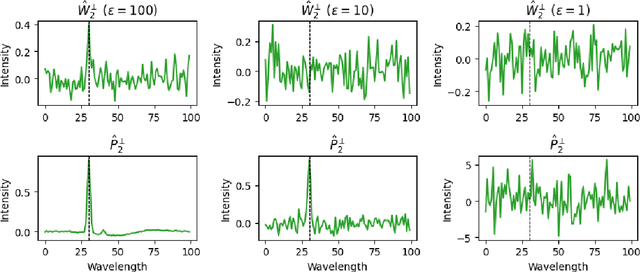
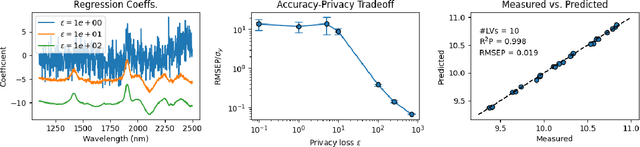
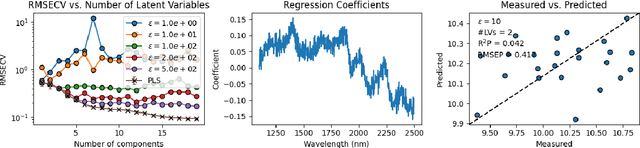
As data-privacy requirements are becoming increasingly stringent and statistical models based on sensitive data are being deployed and used more routinely, protecting data-privacy becomes pivotal. Partial Least Squares (PLS) regression is the premier tool for building such models in analytical chemistry, yet it does not inherently provide privacy guarantees, leaving sensitive (training) data vulnerable to privacy attacks. To address this gap, we propose an $(\epsilon, \delta)$-differentially private PLS (edPLS) algorithm, which integrates well-studied and theoretically motivated Gaussian noise-adding mechanisms into the PLS algorithm to ensure the privacy of the data underlying the model. Our approach involves adding carefully calibrated Gaussian noise to the outputs of four key functions in the PLS algorithm: the weights, scores, $X$-loadings, and $Y$-loadings. The noise variance is determined based on the global sensitivity of each function, ensuring that the privacy loss is controlled according to the $(\epsilon, \delta)$-differential privacy framework. Specifically, we derive the sensitivity bounds for each function and use these bounds to calibrate the noise added to the model components. Experimental results demonstrate that edPLS effectively renders privacy attacks, aimed at recovering unique sources of variability in the training data, ineffective. Application of edPLS to the NIR corn benchmark dataset shows that the root mean squared error of prediction (RMSEP) remains competitive even at strong privacy levels (i.e., $\epsilon=1$), given proper pre-processing of the corresponding spectra. These findings highlight the practical utility of edPLS in creating privacy-preserving multivariate calibrations and for the analysis of their privacy-utility trade-offs.
Geometrically Inspired Kernel Machines for Collaborative Learning Beyond Gradient Descent
Jul 05, 2024This paper develops a novel mathematical framework for collaborative learning by means of geometrically inspired kernel machines which includes statements on the bounds of generalisation and approximation errors, and sample complexity. For classification problems, this approach allows us to learn bounded geometric structures around given data points and hence solve the global model learning problem in an efficient way by exploiting convexity properties of the related optimisation problem in a Reproducing Kernel Hilbert Space (RKHS). In this way, we can reduce classification problems to determining the closest bounded geometric structure from a given data point. Further advantages that come with our solution is that our approach does not require clients to perform multiple epochs of local optimisation using stochastic gradient descent, nor require rounds of communication between client/server for optimising the global model. We highlight that numerous experiments have shown that the proposed method is a competitive alternative to the state-of-the-art.
Comparative Analysis of Transformers for Modeling Tabular Data: A Casestudy using Industry Scale Dataset
Nov 24, 2023We perform a comparative analysis of transformer-based models designed for modeling tabular data, specifically on an industry-scale dataset. While earlier studies demonstrated promising outcomes on smaller public or synthetic datasets, the effectiveness did not extend to larger industry-scale datasets. The challenges identified include handling high-dimensional data, the necessity for efficient pre-processing of categorical and numerical features, and addressing substantial computational requirements. To overcome the identified challenges, the study conducts an extensive examination of various transformer-based models using both synthetic datasets and the default prediction Kaggle dataset (2022) from American Express. The paper presents crucial insights into optimal data pre-processing, compares pre-training and direct supervised learning methods, discusses strategies for managing categorical and numerical features, and highlights trade-offs between computational resources and performance. Focusing on temporal financial data modeling, the research aims to facilitate the systematic development and deployment of transformer-based models in real-world scenarios, emphasizing scalability.
RoboSense At Edge: Detecting Slip, Crumple and Shape of the Object in Robotic Hand for Teleoprations
Nov 14, 2023Slip and crumple detection is essential for performing robust manipulation tasks with a robotic hand (RH) like remote surgery. It has been one of the challenging problems in the robotics manipulation community. In this work, we propose a technique based on machine learning (ML) based techniques to detect the slip, and crumple as well as the shape of an object that is currently held in the robotic hand. We proposed ML model will detect the slip, crumple, and shape using the force/torque exerted and the angular positions of the actuators present in the RH. The proposed model would be integrated into the loop of a robotic hand(RH) and haptic glove(HG). This would help us to reduce the latency in case of teleoperation
Kernel Affine Hull Machines for Differentially Private Learning
Apr 03, 2023

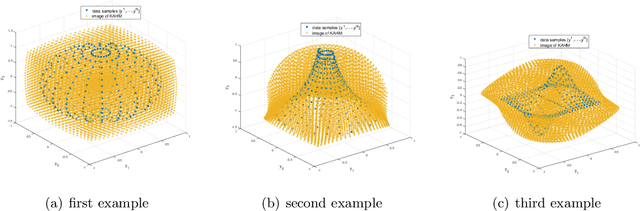

This paper explores the use of affine hulls of points as a means of representing data via learning in Reproducing Kernel Hilbert Spaces (RKHS), with the goal of partitioning the data space into geometric bodies that conceal privacy-sensitive information about individual data points, while preserving the structure of the original learning problem. To this end, we introduce the Kernel Affine Hull Machine (KAHM), which provides an effective way of computing a distance measure from the resulting bounded geometric body. KAHM is a critical building block in wide and deep autoencoders, which enable data representation learning for classification applications. To ensure privacy-preserving learning, we propose a novel method for generating fabricated data, which involves smoothing differentially private data samples through a transformation process. The resulting fabricated data guarantees not only differential privacy but also ensures that the KAHM modeling error is not larger than that of the original training data samples. We also address the accuracy-loss issue that arises with differentially private classifiers by using fabricated data. This approach results in a significant reduction in the risk of membership inference attacks while incurring only a marginal loss of accuracy. As an application, a KAHM based differentially private federated learning scheme is introduced featuring that the evaluation of global classifier requires only locally computed distance measures. Overall, our findings demonstrate the potential of KAHM as effective tool for privacy-preserving learning and classification.
Non-Linear Signal Processing methods for UAV detections from a Multi-function X-band Radar
Mar 13, 2023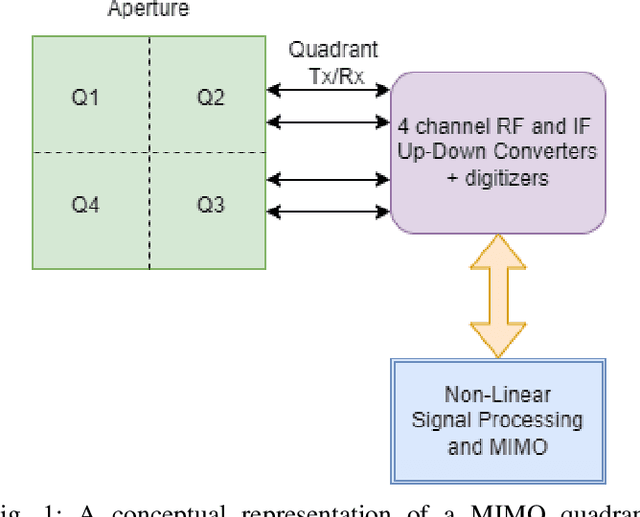
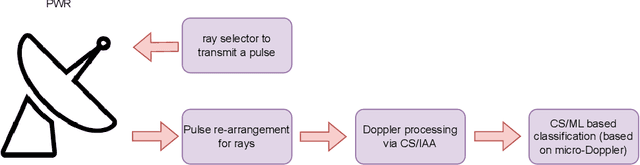
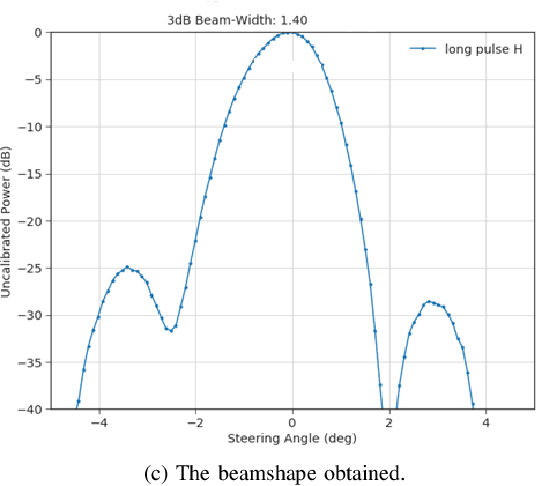
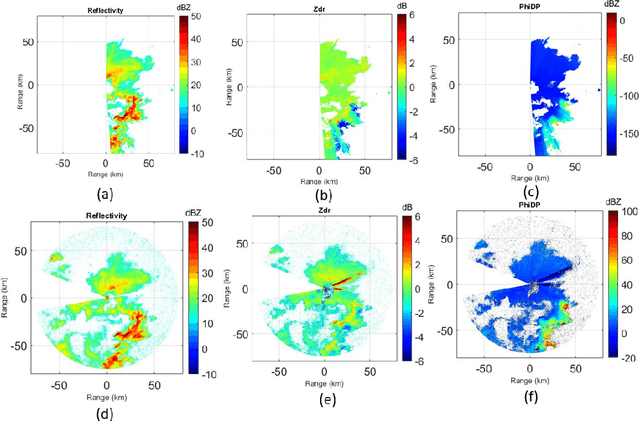
This article develops the applicability of non-linear processing techniques such as Compressed Sensing (CS), Principal Component Analysis (PCA), Iterative Adaptive Approach (IAA) and Multiple-input-multiple-output (MIMO) for the purpose of enhanced UAV detections using portable radar systems. The combined scheme has many advantages and the potential for better detection and classification accuracy. Some of the benefits are discussed here with a phased array platform in mind, the novel portable phased array Radar (PWR) by Agile RF Systems (ARS), which offers quadrant outputs. CS and IAA both show promising results when applied to micro-Doppler processing of radar returns owing to the sparse nature of the target Doppler frequencies. This shows promise in reducing the dwell time and increase the rate at which a volume can be interrogated. Real-time processing of target information with iterative and non-linear solutions is possible now with the advent of GPU-based graphics processing hardware. Simulations show promising results.
Membership-Mappings for Practical Secure Distributed Deep Learning
Apr 12, 2022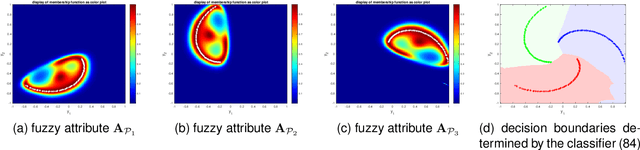
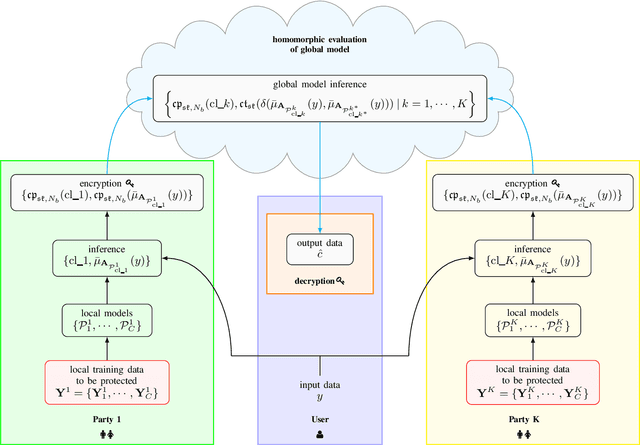
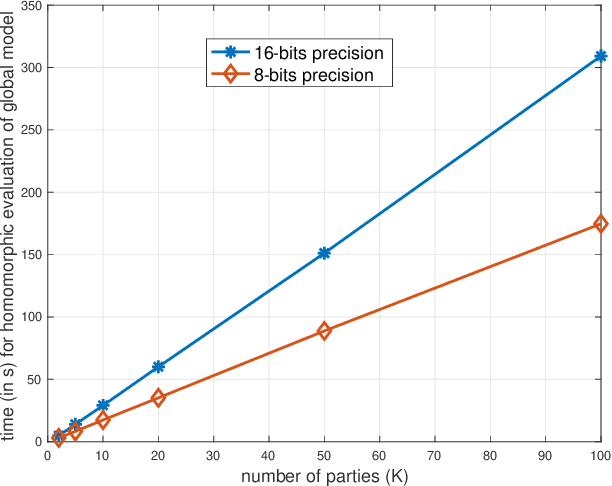
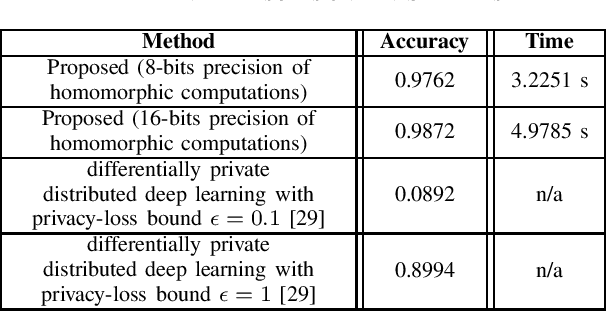
This study leverages the data representation capability of fuzzy based membership-mappings for practical secure distributed deep learning using fully homomorphic encryption. The impracticality issue of secure machine (deep) learning with fully homomorphic encrypted data, arising from large computational overhead, is addressed via applying fuzzy attributes. Fuzzy attributes are induced by globally convergent and robust variational membership-mappings based local deep models. Fuzzy attributes combine the local deep models in a robust and flexible manner such that the global model can be evaluated homomorphically in an efficient manner using a boolean circuit composed of bootstrapped binary gates. The proposed method, while preserving privacy in a distributed learning scenario, remains accurate, practical, and scalable. The method is evaluated through numerous experiments including demonstrations through MNIST dataset and Freiburg Groceries Dataset. Further, a biomedical application related to mental stress detection on individuals is considered.
Learning MAX-SAT from Contextual Examples for Combinatorial Optimisation
Feb 08, 2022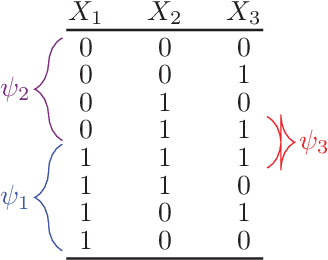
Combinatorial optimisation problems are ubiquitous in artificial intelligence. Designing the underlying models, however, requires substantial expertise, which is a limiting factor in practice. The models typically consist of hard and soft constraints, or combine hard constraints with an objective function. We introduce a novel setting for learning combinatorial optimisation problems from contextual examples. These positive and negative examples show - in a particular context - whether the solutions are good enough or not. We develop our framework using the MAX-SAT formalism as it is simple yet powerful setting having these features. We study the learnability of MAX-SAT models. Our theoretical results show that high-quality MAX-SAT models can be learned from contextual examples in the realisable and agnostic settings, as long as the data satisfies an intuitive "representativeness" condition. We also contribute two implementations based on our theoretical results: one leverages ideas from syntax-guided synthesis while the other makes use of stochastic local search techniques. The two implementations are evaluated by recovering synthetic and benchmark models from contextual examples. The experimental results support our theoretical analysis, showing that MAX-SAT models can be learned from contextual examples. Among the two implementations, the stochastic local search learner scales much better than the syntax-guided implementation while providing comparable or better models.
Few-shot calibration of low-cost air pollution sensors using meta-learning
Aug 02, 2021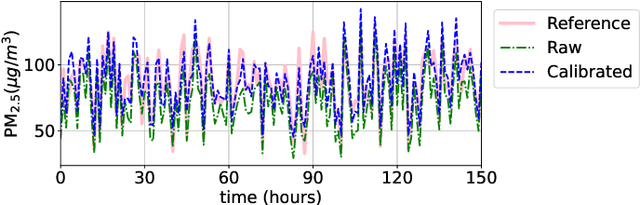

Low-cost particulate matter sensors are transforming air quality monitoring because they have lower costs and greater mobility as compared to reference monitors. Calibration of these low-cost sensors requires training data from co-deployed reference monitors. Machine Learning based calibration gives better performance than conventional techniques, but requires a large amount of training data from the sensor, to be calibrated, co-deployed with a reference monitor. In this work, we propose novel transfer learning methods for quick calibration of sensors with minimal co-deployment with reference monitors. Transfer learning utilizes a large amount of data from other sensors along with a limited amount of data from the target sensor. Our extensive experimentation finds the proposed Model-Agnostic- Meta-Learning (MAML) based transfer learning method to be the most effective over other competitive baselines.