 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Transformers for Modeling Tabular Data: A Casestudy using Industry Scale Dataset
Nov 24, 2023We perform a comparative analysis of transformer-based models designed for modeling tabular data, specifically on an industry-scale dataset. While earlier studies demonstrated promising outcomes on smaller public or synthetic datasets, the effectiveness did not extend to larger industry-scale datasets. The challenges identified include handling high-dimensional data, the necessity for efficient pre-processing of categorical and numerical features, and addressing substantial computational requirements. To overcome the identified challenges, the study conducts an extensive examination of various transformer-based models using both synthetic datasets and the default prediction Kaggle dataset (2022) from American Express. The paper presents crucial insights into optimal data pre-processing, compares pre-training and direct supervised learning methods, discusses strategies for managing categorical and numerical features, and highlights trade-offs between computational resources and performance. Focusing on temporal financial data modeling, the research aims to facilitate the systematic development and deployment of transformer-based models in real-world scenarios, emphasizing scalability.
ViT-Inception-GAN for Image Colourising
Jun 11, 2021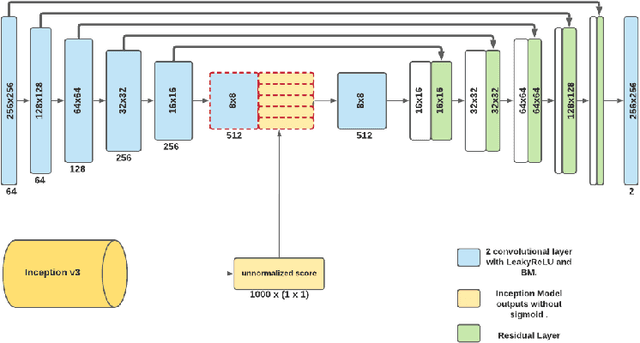

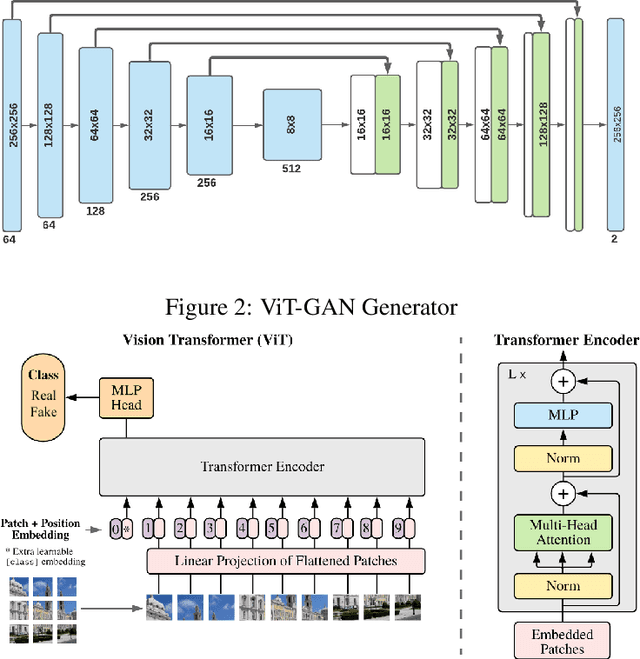

Studies involving colourising images has been garnering researchers' keen attention over time, assisted by significant advances in various Machine Learning techniques and compute power availability. Traditionally, colourising images have been an intricate task that gave a substantial degree of freedom during the assignment of chromatic information. In our proposed method, we attempt to colourise images using Vision Transformer - Inception - Generative Adversarial Network (ViT-I-GAN), which has an Inception-v3 fusion embedding in the generator. For a stable and robust network, we have used Vision Transformer (ViT) as the discriminator. We trained the model on the Unsplash and the COCO dataset for demonstrating the improvement made by the Inception-v3 embedding. We have compared the results between ViT-GANs with and without Inception-v3 embedding.