 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Validating Synthetic Data for Formula Generation
Jul 15, 2024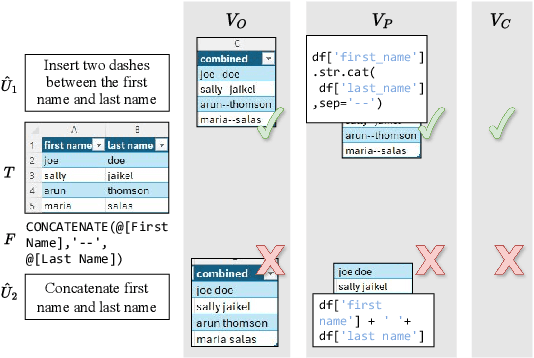
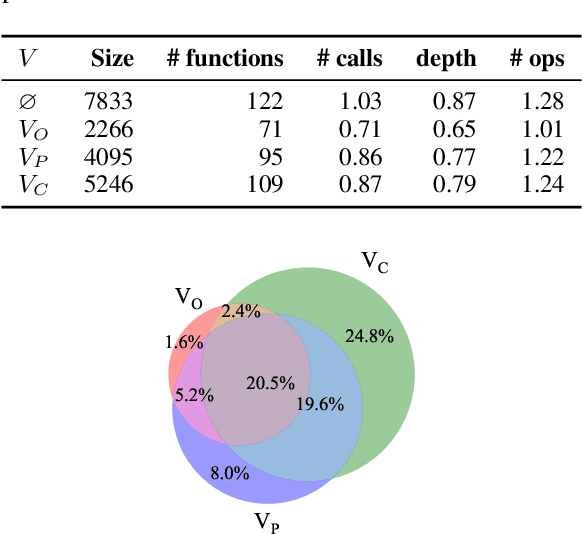
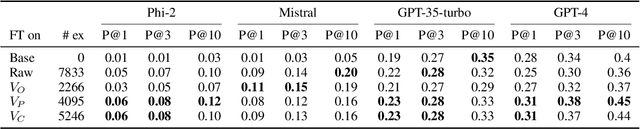
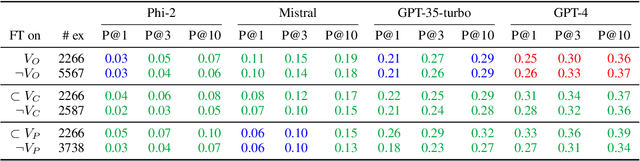
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
Comparative Analysis of Transformers for Modeling Tabular Data: A Casestudy using Industry Scale Dataset
Nov 24, 2023We perform a comparative analysis of transformer-based models designed for modeling tabular data, specifically on an industry-scale dataset. While earlier studies demonstrated promising outcomes on smaller public or synthetic datasets, the effectiveness did not extend to larger industry-scale datasets. The challenges identified include handling high-dimensional data, the necessity for efficient pre-processing of categorical and numerical features, and addressing substantial computational requirements. To overcome the identified challenges, the study conducts an extensive examination of various transformer-based models using both synthetic datasets and the default prediction Kaggle dataset (2022) from American Express. The paper presents crucial insights into optimal data pre-processing, compares pre-training and direct supervised learning methods, discusses strategies for managing categorical and numerical features, and highlights trade-offs between computational resources and performance. Focusing on temporal financial data modeling, the research aims to facilitate the systematic development and deployment of transformer-based models in real-world scenarios, emphasizing scalability.