 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-Inception-GAN for Image Colourising
Jun 11, 2021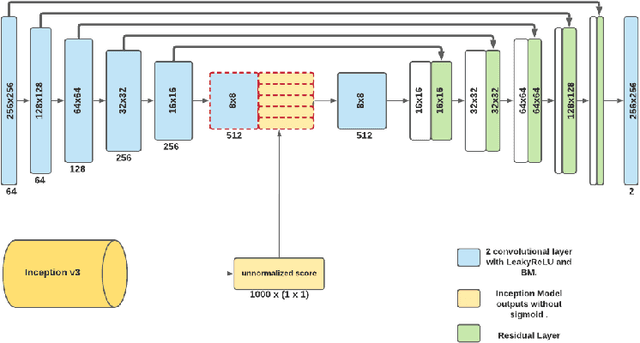

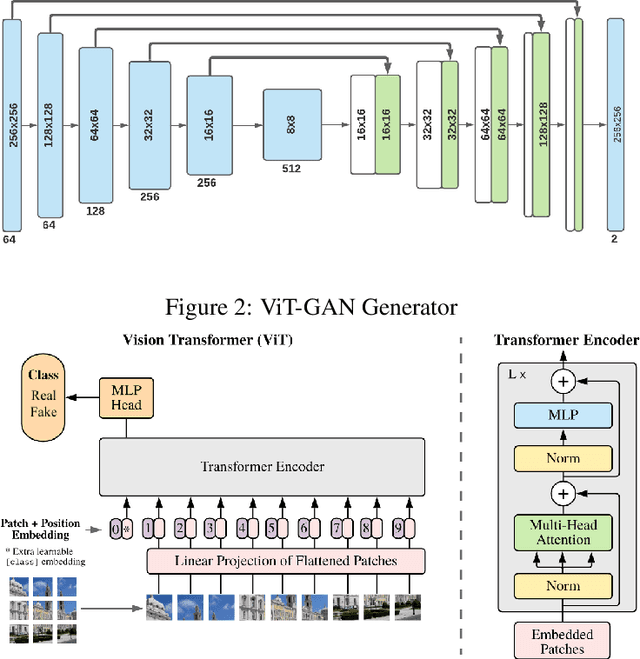

Studies involving colourising images has been garnering researchers' keen attention over time, assisted by significant advances in various Machine Learning techniques and compute power availability. Traditionally, colourising images have been an intricate task that gave a substantial degree of freedom during the assignment of chromatic information. In our proposed method, we attempt to colourise images using Vision Transformer - Inception - Generative Adversarial Network (ViT-I-GAN), which has an Inception-v3 fusion embedding in the generator. For a stable and robust network, we have used Vision Transformer (ViT) as the discriminator. We trained the model on the Unsplash and the COCO dataset for demonstrating the improvement made by the Inception-v3 embedding. We have compared the results between ViT-GANs with and without Inception-v3 embedding.