 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcise and Logically Consistent Conformal Sets for Neuro-Symbolic Concept-Based Models
May 18, 2026Neuro-Symbolic Concept-based Models (NeSy-CBMs) are a family of architectures that integrate neural networks with symbolic reasoning for enhanced reliability in high-stakes applications. They work by first extracting high-level concepts from the input and then inferring a task label from these compatibly with given logical constraints. Yet, their label and concept predictions can be overconfident, making it difficult for stakeholders to gauge when the model's decisions can be trusted. We address this issue by integrating ideas from Conformal Prediction (CP), a framework providing rigorous, distribution-free coverage guarantees. We formalize three desiderata -- consistency, coverage, and conciseness -- that any conformal method for NeSy-CBMs should satisfy, and show that existing approaches fall short of at least one. We then introduce COCOCO, a post-hoc framework that conformalizes concepts and labels jointly and reconciles them via a single deduction-abduction revision step. COCOCO satisfies all three desiderata, retains distribution-free coverage, is robust to imperfect knowledge and supports user-specified size budgets. Our experiments on 8 data sets highlight how COCOCO compares favorably against competitors and natural baselines in terms of performance and set size.
Hybrid Decision Making via Conformal VLM-generated Guidance
Apr 16, 2026Building on recent advances in AI, hybrid decision making (HDM) holds the promise of improving human decision quality and reducing cognitive load. We work in the context of learning to guide (LtG), a recently proposed HDM framework in which the human is always responsible for the final decision: rather than suggesting decisions, in LtG the AI supplies (textual) guidance useful for facilitating decision making. One limiting factor of existing approaches is that their guidance compounds information about all possible outcomes, and as a result it can be difficult to digest. We address this issue by introducing ConfGuide, a novel LtG approach that generates more succinct and targeted guidance. To this end, it employs conformal risk control to select a set of outcomes, ensuring a cap on the false negative rate. We demonstrate our approach on a real-world multi-label medical diagnosis task. Our empirical evaluation highlights the promise of ConfGuide.
GNN Explanations that do not Explain and How to find Them
Jan 28, 2026Explanations provided by Self-explainable Graph Neural Networks (SE-GNNs) are fundamental for understanding the model's inner workings and for identifying potential misuse of sensitive attributes. Although recent works have highlighted that these explanations can be suboptimal and potentially misleading, a characterization of their failure cases is unavailable. In this work, we identify a critical failure of SE-GNN explanations: explanations can be unambiguously unrelated to how the SE-GNNs infer labels. We show that, on the one hand, many SE-GNNs can achieve optimal true risk while producing these degenerate explanations, and on the other, most faithfulness metrics can fail to identify these failure modes. Our empirical analysis reveals that degenerate explanations can be maliciously planted (allowing an attacker to hide the use of sensitive attributes) and can also emerge naturally, highlighting the need for reliable auditing. To address this, we introduce a novel faithfulness metric that reliably marks degenerate explanations as unfaithful, in both malicious and natural settings. Our code is available in the supplemental.
Symbol Grounding in Neuro-Symbolic AI: A Gentle Introduction to Reasoning Shortcuts
Oct 16, 2025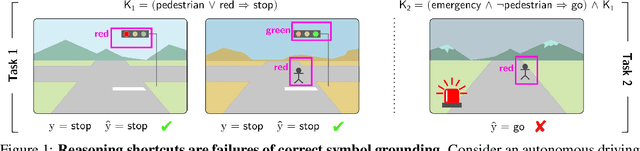

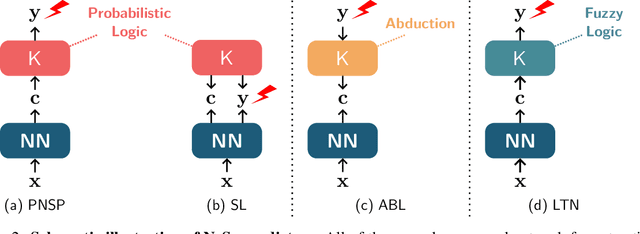
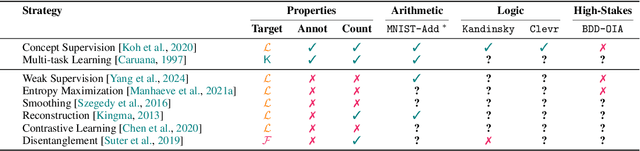
Neuro-symbolic (NeSy) AI aims to develop deep neural networks whose predictions comply with prior knowledge encoding, e.g. safety or structural constraints. As such, it represents one of the most promising avenues for reliable and trustworthy AI. The core idea behind NeSy AI is to combine neural and symbolic steps: neural networks are typically responsible for mapping low-level inputs into high-level symbolic concepts, while symbolic reasoning infers predictions compatible with the extracted concepts and the prior knowledge. Despite their promise, it was recently shown that - whenever the concepts are not supervised directly - NeSy models can be affected by Reasoning Shortcuts (RSs). That is, they can achieve high label accuracy by grounding the concepts incorrectly. RSs can compromise the interpretability of the model's explanations, performance in out-of-distribution scenarios, and therefore reliability. At the same time, RSs are difficult to detect and prevent unless concept supervision is available, which is typically not the case. However, the literature on RSs is scattered, making it difficult for researchers and practitioners to understand and tackle this challenging problem. This overview addresses this issue by providing a gentle introduction to RSs, discussing their causes and consequences in intuitive terms. It also reviews and elucidates existing theoretical characterizations of this phenomenon. Finally, it details methods for dealing with RSs, including mitigation and awareness strategies, and maps their benefits and limitations. By reformulating advanced material in a digestible form, this overview aims to provide a unifying perspective on RSs to lower the bar to entry for tackling them. Ultimately, we hope this overview contributes to the development of reliable NeSy and trustworthy AI models.
Personalized Interpretability -- Interactive Alignment of Prototypical Parts Networks
Jun 05, 2025Concept-based interpretable neural networks have gained significant attention due to their intuitive and easy-to-understand explanations based on case-based reasoning, such as "this bird looks like those sparrows". However, a major limitation is that these explanations may not always be comprehensible to users due to concept inconsistency, where multiple visual features are inappropriately mixed (e.g., a bird's head and wings treated as a single concept). This inconsistency breaks the alignment between model reasoning and human understanding. Furthermore, users have specific preferences for how concepts should look, yet current approaches provide no mechanism for incorporating their feedback. To address these issues, we introduce YoursProtoP, a novel interactive strategy that enables the personalization of prototypical parts - the visual concepts used by the model - according to user needs. By incorporating user supervision, YoursProtoP adapts and splits concepts used for both prediction and explanation to better match the user's preferences and understanding. Through experiments on both the synthetic FunnyBirds dataset and a real-world scenario using the CUB, CARS, and PETS datasets in a comprehensive user study, we demonstrate the effectiveness of YoursProtoP in achieving concept consistency without compromising the accuracy of the model.
If Concept Bottlenecks are the Question, are Foundation Models the Answer?
Apr 29, 2025Concept Bottleneck Models (CBMs) are neural networks designed to conjoin high performance with ante-hoc interpretability. CBMs work by first mapping inputs (e.g., images) to high-level concepts (e.g., visible objects and their properties) and then use these to solve a downstream task (e.g., tagging or scoring an image) in an interpretable manner. Their performance and interpretability, however, hinge on the quality of the concepts they learn. The go-to strategy for ensuring good quality concepts is to leverage expert annotations, which are expensive to collect and seldom available in applications. Researchers have recently addressed this issue by introducing "VLM-CBM" architectures that replace manual annotations with weak supervision from foundation models. It is however unclear what is the impact of doing so on the quality of the learned concepts. To answer this question, we put state-of-the-art VLM-CBMs to the test, analyzing their learned concepts empirically using a selection of significant metrics. Our results show that, depending on the task, VLM supervision can sensibly differ from expert annotations, and that concept accuracy and quality are not strongly correlated. Our code is available at https://github.com/debryu/CQA.
Beyond Topological Self-Explainable GNNs: A Formal Explainability Perspective
Feb 04, 2025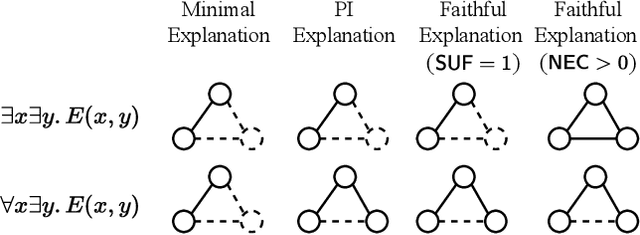
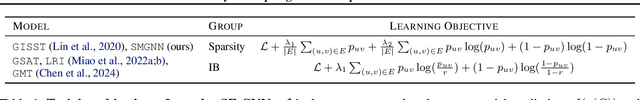


Self-Explainable Graph Neural Networks (SE-GNNs) are popular explainable-by-design GNNs, but the properties and the limitations of their explanations are not well understood. Our first contribution fills this gap by formalizing the explanations extracted by SE-GNNs, referred to as Trivial Explanations (TEs), and comparing them to established notions of explanations, namely Prime Implicant (PI) and faithful explanations. Our analysis reveals that TEs match PI explanations for a restricted but significant family of tasks. In general, however, they can be less informative than PI explanations and are surprisingly misaligned with widely accepted notions of faithfulness. Although faithful and PI explanations are informative, they are intractable to find and we show that they can be prohibitively large. Motivated by this, we propose Dual-Channel GNNs that integrate a white-box rule extractor and a standard SE-GNN, adaptively combining both channels when the task benefits. Our experiments show that even a simple instantiation of Dual-Channel GNNs can recover succinct rules and perform on par or better than widely used SE-GNNs. Our code can be found in the supplementary material.
Time Can Invalidate Algorithmic Recourse
Oct 10, 2024



Algorithmic Recourse (AR) aims to provide users with actionable steps to overturn unfavourable decisions made by machine learning predictors. However, these actions often take time to implement (e.g., getting a degree can take years), and their effects may vary as the world evolves. Thus, it is natural to ask for recourse that remains valid in a dynamic environment. In this paper, we study the robustness of algorithmic recourse over time by casting the problem through the lens of causality. We demonstrate theoretically and empirically that (even robust) causal AR methods can fail over time except in the - unlikely - case that the world is stationary. Even more critically, unless the world is fully deterministic, counterfactual AR cannot be solved optimally. To account for this, we propose a simple yet effective algorithm for temporal AR that explicitly accounts for time. Our simulations on synthetic and realistic datasets show how considering time produces more resilient solutions to potential trends in the data distribution.
Spurious Correlations in Concept Drift: Can Explanatory Interaction Help?
Jul 23, 2024Long-running machine learning models face the issue of concept drift (CD), whereby the data distribution changes over time, compromising prediction performance. Updating the model requires detecting drift by monitoring the data and/or the model for unexpected changes. We show that, however, spurious correlations (SCs) can spoil the statistics tracked by detection algorithms. Motivated by this, we introduce ebc-exstream, a novel detector that leverages model explanations to identify potential SCs and human feedback to correct for them. It leverages an entropy-based heuristic to reduce the amount of necessary feedback, cutting annotation costs. Our preliminary experiments on artificially confounded data highlight the promise of ebc-exstream for reducing the impact of SCs on detection.
Perks and Pitfalls of Faithfulness in Regular, Self-Explainable and Domain Invariant GNNs
Jun 21, 2024As Graph Neural Networks (GNNs) become more pervasive, it becomes paramount to build robust tools for computing explanations of their predictions. A key desideratum is that these explanations are faithful, i.e., that they portray an accurate picture of the GNN's reasoning process. A number of different faithfulness metrics exist, begging the question of what faithfulness is exactly, and what its properties are. We begin by showing that existing metrics are not interchangeable -- i.e., explanations attaining high faithfulness according to one metric may be unfaithful according to others -- and can be systematically insensitive to important properties of the explanation, and suggest how to address these issues. We proceed to show that, surprisingly, optimizing for faithfulness is not always a sensible design goal. Specifically, we show that for injective regular GNN architectures, perfectly faithful explanations are completely uninformative. The situation is different for modular GNNs, such as self-explainable and domain-invariant architectures, where optimizing faithfulness does not compromise informativeness, and is also unexpectedly tied to out-of-distribution generalization.