 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbol Grounding in Neuro-Symbolic AI: A Gentle Introduction to Reasoning Shortcuts
Oct 16, 2025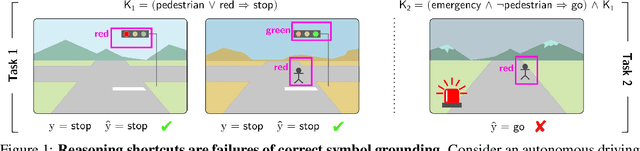

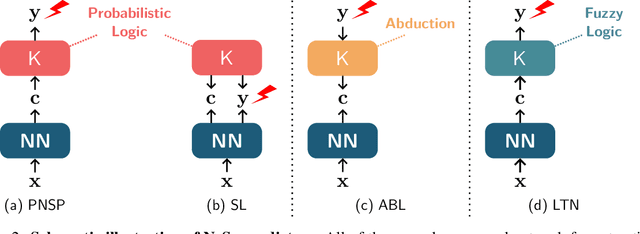
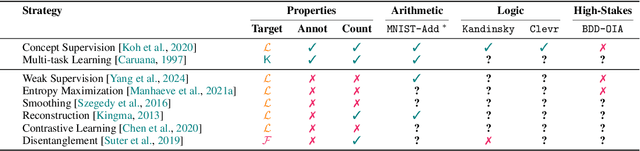
Neuro-symbolic (NeSy) AI aims to develop deep neural networks whose predictions comply with prior knowledge encoding, e.g. safety or structural constraints. As such, it represents one of the most promising avenues for reliable and trustworthy AI. The core idea behind NeSy AI is to combine neural and symbolic steps: neural networks are typically responsible for mapping low-level inputs into high-level symbolic concepts, while symbolic reasoning infers predictions compatible with the extracted concepts and the prior knowledge. Despite their promise, it was recently shown that - whenever the concepts are not supervised directly - NeSy models can be affected by Reasoning Shortcuts (RSs). That is, they can achieve high label accuracy by grounding the concepts incorrectly. RSs can compromise the interpretability of the model's explanations, performance in out-of-distribution scenarios, and therefore reliability. At the same time, RSs are difficult to detect and prevent unless concept supervision is available, which is typically not the case. However, the literature on RSs is scattered, making it difficult for researchers and practitioners to understand and tackle this challenging problem. This overview addresses this issue by providing a gentle introduction to RSs, discussing their causes and consequences in intuitive terms. It also reviews and elucidates existing theoretical characterizations of this phenomenon. Finally, it details methods for dealing with RSs, including mitigation and awareness strategies, and maps their benefits and limitations. By reformulating advanced material in a digestible form, this overview aims to provide a unifying perspective on RSs to lower the bar to entry for tackling them. Ultimately, we hope this overview contributes to the development of reliable NeSy and trustworthy AI models.
A Benchmark Suite for Systematically Evaluating Reasoning Shortcuts
Jun 14, 2024



The advent of powerful neural classifiers has increased interest in problems that require both learning and reasoning. These problems are critical for understanding important properties of models, such as trustworthiness, generalization, interpretability, and compliance to safety and structural constraints. However, recent research observed that tasks requiring both learning and reasoning on background knowledge often suffer from reasoning shortcuts (RSs): predictors can solve the downstream reasoning task without associating the correct concepts to the high-dimensional data. To address this issue, we introduce rsbench, a comprehensive benchmark suite designed to systematically evaluate the impact of RSs on models by providing easy access to highly customizable tasks affected by RSs. Furthermore, rsbench implements common metrics for evaluating concept quality and introduces novel formal verification procedures for assessing the presence of RSs in learning tasks. Using rsbench, we highlight that obtaining high quality concepts in both purely neural and neuro-symbolic models is a far-from-solved problem. rsbench is available at: https://unitn-sml.github.io/rsbench.
BEARS Make Neuro-Symbolic Models Aware of their Reasoning Shortcuts
Feb 19, 2024



Neuro-Symbolic (NeSy) predictors that conform to symbolic knowledge - encoding, e.g., safety constraints - can be affected by Reasoning Shortcuts (RSs): They learn concepts consistent with the symbolic knowledge by exploiting unintended semantics. RSs compromise reliability and generalization and, as we show in this paper, they are linked to NeSy models being overconfident about the predicted concepts. Unfortunately, the only trustworthy mitigation strategy requires collecting costly dense supervision over the concepts. Rather than attempting to avoid RSs altogether, we propose to ensure NeSy models are aware of the semantic ambiguity of the concepts they learn, thus enabling their users to identify and distrust low-quality concepts. Starting from three simple desiderata, we derive bears (BE Aware of Reasoning Shortcuts), an ensembling technique that calibrates the model's concept-level confidence without compromising prediction accuracy, thus encouraging NeSy architectures to be uncertain about concepts affected by RSs. We show empirically that bears improves RS-awareness of several state-of-the-art NeSy models, and also facilitates acquiring informative dense annotations for mitigation purposes.