 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Linear Properties in Language Models: An Empirical Investigation
May 21, 2026Linear properties are ubiquitous in the representations of language models; however, testing them experimentally remains a challenging task. This work focuses on relational linearity: the hypothesis that, for a fixed relation (e.g., "plays"), the unembedding of an object (e.g., "trumpet") can be predicted from the embedding of its subject (e.g.,"Miles Davis") by a linear map. We present an experimental method to test the formulation of relational linearity by Marconato et al. (2025). Specifically, we introduce a probing method, based on Kullback-Leibler divergence, to evaluate this property and examine its variation across layers and paraphrased relational queries. It is also more efficient than previous work; for example, it avoids the crude Jacobian approximations used in Linear Relational Embeddings by Hernandez et al. (2024). Our findings across four datasets show that relational linearity varies across models, exhibits layer-wise patterns consistent with prior observations about linguistic information in model representations, and is differently affected by changes in how the relation is phrased.
Concise and Logically Consistent Conformal Sets for Neuro-Symbolic Concept-Based Models
May 18, 2026Neuro-Symbolic Concept-based Models (NeSy-CBMs) are a family of architectures that integrate neural networks with symbolic reasoning for enhanced reliability in high-stakes applications. They work by first extracting high-level concepts from the input and then inferring a task label from these compatibly with given logical constraints. Yet, their label and concept predictions can be overconfident, making it difficult for stakeholders to gauge when the model's decisions can be trusted. We address this issue by integrating ideas from Conformal Prediction (CP), a framework providing rigorous, distribution-free coverage guarantees. We formalize three desiderata -- consistency, coverage, and conciseness -- that any conformal method for NeSy-CBMs should satisfy, and show that existing approaches fall short of at least one. We then introduce COCOCO, a post-hoc framework that conformalizes concepts and labels jointly and reconciles them via a single deduction-abduction revision step. COCOCO satisfies all three desiderata, retains distribution-free coverage, is robust to imperfect knowledge and supports user-specified size budgets. Our experiments on 8 data sets highlight how COCOCO compares favorably against competitors and natural baselines in terms of performance and set size.
Logit Distance Bounds Representational Similarity
Feb 17, 2026For a broad family of discriminative models that includes autoregressive language models, identifiability results imply that if two models induce the same conditional distributions, then their internal representations agree up to an invertible linear transformation. We ask whether an analogous conclusion holds approximately when the distributions are close instead of equal. Building on the observation of Nielsen et al. (2025) that closeness in KL divergence need not imply high linear representational similarity, we study a distributional distance based on logit differences and show that closeness in this distance does yield linear similarity guarantees. Specifically, we define a representational dissimilarity measure based on the models' identifiability class and prove that it is bounded by the logit distance. We further show that, when model probabilities are bounded away from zero, KL divergence upper-bounds logit distance; yet the resulting bound fails to provide nontrivial control in practice. As a consequence, KL-based distillation can match a teacher's predictions while failing to preserve linear representational properties, such as linear-probe recoverability of human-interpretable concepts. In distillation experiments on synthetic and image datasets, logit-distance distillation yields students with higher linear representational similarity and better preservation of the teacher's linearly recoverable concepts.
Symbol Grounding in Neuro-Symbolic AI: A Gentle Introduction to Reasoning Shortcuts
Oct 16, 2025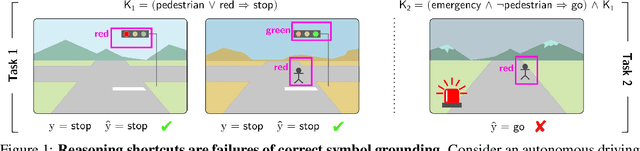

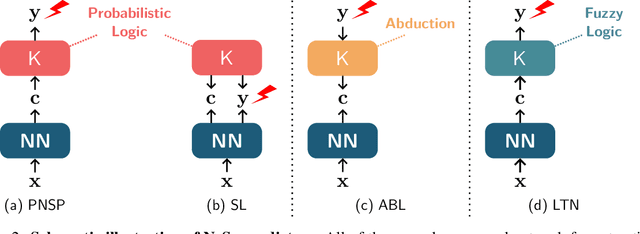
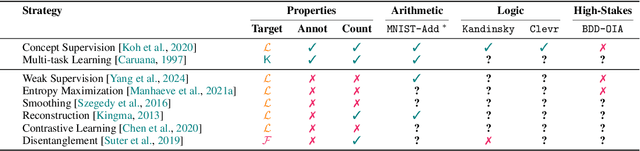
Neuro-symbolic (NeSy) AI aims to develop deep neural networks whose predictions comply with prior knowledge encoding, e.g. safety or structural constraints. As such, it represents one of the most promising avenues for reliable and trustworthy AI. The core idea behind NeSy AI is to combine neural and symbolic steps: neural networks are typically responsible for mapping low-level inputs into high-level symbolic concepts, while symbolic reasoning infers predictions compatible with the extracted concepts and the prior knowledge. Despite their promise, it was recently shown that - whenever the concepts are not supervised directly - NeSy models can be affected by Reasoning Shortcuts (RSs). That is, they can achieve high label accuracy by grounding the concepts incorrectly. RSs can compromise the interpretability of the model's explanations, performance in out-of-distribution scenarios, and therefore reliability. At the same time, RSs are difficult to detect and prevent unless concept supervision is available, which is typically not the case. However, the literature on RSs is scattered, making it difficult for researchers and practitioners to understand and tackle this challenging problem. This overview addresses this issue by providing a gentle introduction to RSs, discussing their causes and consequences in intuitive terms. It also reviews and elucidates existing theoretical characterizations of this phenomenon. Finally, it details methods for dealing with RSs, including mitigation and awareness strategies, and maps their benefits and limitations. By reformulating advanced material in a digestible form, this overview aims to provide a unifying perspective on RSs to lower the bar to entry for tackling them. Ultimately, we hope this overview contributes to the development of reliable NeSy and trustworthy AI models.
When Does Closeness in Distribution Imply Representational Similarity? An Identifiability Perspective
Jun 04, 2025When and why representations learned by different deep neural networks are similar is an active research topic. We choose to address these questions from the perspective of identifiability theory, which suggests that a measure of representational similarity should be invariant to transformations that leave the model distribution unchanged. Focusing on a model family which includes several popular pre-training approaches, e.g., autoregressive language models, we explore when models which generate distributions that are close have similar representations. We prove that a small Kullback-Leibler divergence between the model distributions does not guarantee that the corresponding representations are similar. This has the important corollary that models arbitrarily close to maximizing the likelihood can still learn dissimilar representations, a phenomenon mirrored in our empirical observations on models trained on CIFAR-10. We then define a distributional distance for which closeness implies representational similarity, and in synthetic experiments, we find that wider networks learn distributions which are closer with respect to our distance and have more similar representations. Our results establish a link between closeness in distribution and representational similarity.
If Concept Bottlenecks are the Question, are Foundation Models the Answer?
Apr 29, 2025Concept Bottleneck Models (CBMs) are neural networks designed to conjoin high performance with ante-hoc interpretability. CBMs work by first mapping inputs (e.g., images) to high-level concepts (e.g., visible objects and their properties) and then use these to solve a downstream task (e.g., tagging or scoring an image) in an interpretable manner. Their performance and interpretability, however, hinge on the quality of the concepts they learn. The go-to strategy for ensuring good quality concepts is to leverage expert annotations, which are expensive to collect and seldom available in applications. Researchers have recently addressed this issue by introducing "VLM-CBM" architectures that replace manual annotations with weak supervision from foundation models. It is however unclear what is the impact of doing so on the quality of the learned concepts. To answer this question, we put state-of-the-art VLM-CBMs to the test, analyzing their learned concepts empirically using a selection of significant metrics. Our results show that, depending on the task, VLM supervision can sensibly differ from expert annotations, and that concept accuracy and quality are not strongly correlated. Our code is available at https://github.com/debryu/CQA.
All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling
Oct 30, 2024


We analyze identifiability as a possible explanation for the ubiquity of linear properties across language models, such as the vector difference between the representations of "easy" and "easiest" being parallel to that between "lucky" and "luckiest". For this, we ask whether finding a linear property in one model implies that any model that induces the same distribution has that property, too. To answer that, we first prove an identifiability result to characterize distribution-equivalent next-token predictors, lifting a diversity requirement of previous results. Second, based on a refinement of relational linearity [Paccanaro and Hinton, 2001; Hernandez et al., 2024], we show how many notions of linearity are amenable to our analysis. Finally, we show that under suitable conditions, these linear properties either hold in all or none distribution-equivalent next-token predictors.
A Benchmark Suite for Systematically Evaluating Reasoning Shortcuts
Jun 14, 2024



The advent of powerful neural classifiers has increased interest in problems that require both learning and reasoning. These problems are critical for understanding important properties of models, such as trustworthiness, generalization, interpretability, and compliance to safety and structural constraints. However, recent research observed that tasks requiring both learning and reasoning on background knowledge often suffer from reasoning shortcuts (RSs): predictors can solve the downstream reasoning task without associating the correct concepts to the high-dimensional data. To address this issue, we introduce rsbench, a comprehensive benchmark suite designed to systematically evaluate the impact of RSs on models by providing easy access to highly customizable tasks affected by RSs. Furthermore, rsbench implements common metrics for evaluating concept quality and introduces novel formal verification procedures for assessing the presence of RSs in learning tasks. Using rsbench, we highlight that obtaining high quality concepts in both purely neural and neuro-symbolic models is a far-from-solved problem. rsbench is available at: https://unitn-sml.github.io/rsbench.
BEARS Make Neuro-Symbolic Models Aware of their Reasoning Shortcuts
Feb 19, 2024



Neuro-Symbolic (NeSy) predictors that conform to symbolic knowledge - encoding, e.g., safety constraints - can be affected by Reasoning Shortcuts (RSs): They learn concepts consistent with the symbolic knowledge by exploiting unintended semantics. RSs compromise reliability and generalization and, as we show in this paper, they are linked to NeSy models being overconfident about the predicted concepts. Unfortunately, the only trustworthy mitigation strategy requires collecting costly dense supervision over the concepts. Rather than attempting to avoid RSs altogether, we propose to ensure NeSy models are aware of the semantic ambiguity of the concepts they learn, thus enabling their users to identify and distrust low-quality concepts. Starting from three simple desiderata, we derive bears (BE Aware of Reasoning Shortcuts), an ensembling technique that calibrates the model's concept-level confidence without compromising prediction accuracy, thus encouraging NeSy architectures to be uncertain about concepts affected by RSs. We show empirically that bears improves RS-awareness of several state-of-the-art NeSy models, and also facilitates acquiring informative dense annotations for mitigation purposes.
Interpretability is in the Mind of the Beholder: A Causal Framework for Human-interpretable Representation Learning
Sep 14, 2023Focus in Explainable AI is shifting from explanations defined in terms of low-level elements, such as input features, to explanations encoded in terms of interpretable concepts learned from data. How to reliably acquire such concepts is, however, still fundamentally unclear. An agreed-upon notion of concept interpretability is missing, with the result that concepts used by both post-hoc explainers and concept-based neural networks are acquired through a variety of mutually incompatible strategies. Critically, most of these neglect the human side of the problem: a representation is understandable only insofar as it can be understood by the human at the receiving end. The key challenge in Human-interpretable Representation Learning (HRL) is how to model and operationalize this human element. In this work, we propose a mathematical framework for acquiring interpretable representations suitable for both post-hoc explainers and concept-based neural networks. Our formalization of HRL builds on recent advances in causal representation learning and explicitly models a human stakeholder as an external observer. This allows us to derive a principled notion of alignment between the machine representation and the vocabulary of concepts understood by the human. In doing so, we link alignment and interpretability through a simple and intuitive name transfer game, and clarify the relationship between alignment and a well-known property of representations, namely disentanglment. We also show that alignment is linked to the issue of undesirable correlations among concepts, also known as concept leakage, and to content-style separation, all through a general information-theoretic reformulation of these properties. Our conceptualization aims to bridge the gap between the human and algorithmic sides of interpretability and establish a stepping stone for new research on human-interpretable representations.