 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing Discrete Search: A Reasonable Approach to Causal Structure Learning
Oct 06, 2025We present FLOP (Fast Learning of Order and Parents), a score-based causal discovery algorithm for linear models. It pairs fast parent selection with iterative Cholesky-based score updates, cutting run-times over prior algorithms. This makes it feasible to fully embrace discrete search, enabling iterated local search with principled order initialization to find graphs with scores at or close to the global optimum. The resulting structures are highly accurate across benchmarks, with near-perfect recovery in standard settings. This performance calls for revisiting discrete search over graphs as a reasonable approach to causal discovery.
What is causal about causal models and representations?
Jan 31, 2025Causal Bayesian networks are 'causal' models since they make predictions about interventional distributions. To connect such causal model predictions to real-world outcomes, we must determine which actions in the world correspond to which interventions in the model. For example, to interpret an action as an intervention on a treatment variable, the action will presumably have to a) change the distribution of treatment in a way that corresponds to the intervention, and b) not change other aspects, such as how the outcome depends on the treatment; while the marginal distributions of some variables may change as an effect. We introduce a formal framework to make such requirements for different interpretations of actions as interventions precise. We prove that the seemingly natural interpretation of actions as interventions is circular: Under this interpretation, every causal Bayesian network that correctly models the observational distribution is trivially also interventionally valid, and no action yields empirical data that could possibly falsify such a model. We prove an impossibility result: No interpretation exists that is non-circular and simultaneously satisfies a set of natural desiderata. Instead, we examine non-circular interpretations that may violate some desiderata and show how this may in turn enable the falsification of causal models. By rigorously examining how a causal Bayesian network could be a 'causal' model of the world instead of merely a mathematical object, our formal framework contributes to the conceptual foundations of causal representation learning, causal discovery, and causal abstraction, while also highlighting some limitations of existing approaches.
All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling
Oct 30, 2024


We analyze identifiability as a possible explanation for the ubiquity of linear properties across language models, such as the vector difference between the representations of "easy" and "easiest" being parallel to that between "lucky" and "luckiest". For this, we ask whether finding a linear property in one model implies that any model that induces the same distribution has that property, too. To answer that, we first prove an identifiability result to characterize distribution-equivalent next-token predictors, lifting a diversity requirement of previous results. Second, based on a refinement of relational linearity [Paccanaro and Hinton, 2001; Hernandez et al., 2024], we show how many notions of linearity are amenable to our analysis. Finally, we show that under suitable conditions, these linear properties either hold in all or none distribution-equivalent next-token predictors.
Adjustment Identification Distance: A gadjid for Causal Structure Learning
Feb 13, 2024



Evaluating graphs learned by causal discovery algorithms is difficult: The number of edges that differ between two graphs does not reflect how the graphs differ with respect to the identifying formulas they suggest for causal effects. We introduce a framework for developing causal distances between graphs which includes the structural intervention distance for directed acyclic graphs as a special case. We use this framework to develop improved adjustment-based distances as well as extensions to completed partially directed acyclic graphs and causal orders. We develop polynomial-time reachability algorithms to compute the distances efficiently. In our package gadjid (open source at https://github.com/CausalDisco/gadjid), we provide implementations of our distances; they are orders of magnitude faster than the structural intervention distance and thereby provide a success metric for causal discovery that scales to graph sizes that were previously prohibitive.
Unfair Utilities and First Steps Towards Improving Them
Jun 01, 2023Many fairness criteria constrain the policy or choice of predictors. In this work, we propose a different framework for thinking about fairness: Instead of constraining the policy or choice of predictors, we consider which utility a policy is optimizing for. We define value of information fairness and propose to not use utilities that do not satisfy this criterion. We describe how to modify a utility to satisfy this fairness criterion and discuss the consequences this might have on the corresponding optimal policies.
Simple Sorting Criteria Help Find the Causal Order in Additive Noise Models
Mar 31, 2023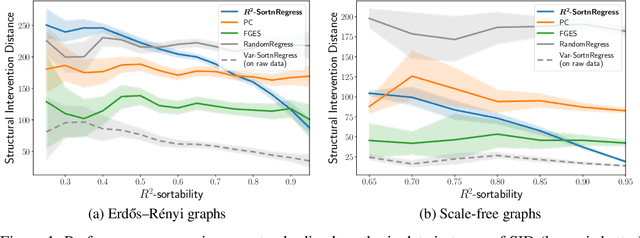
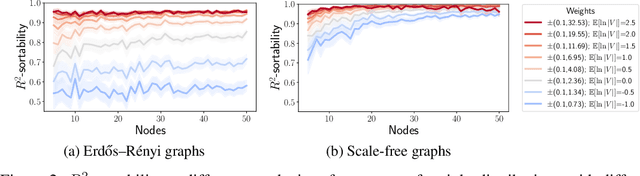
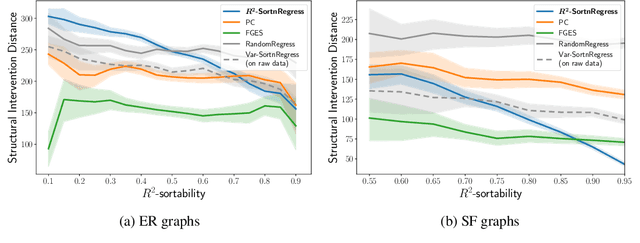
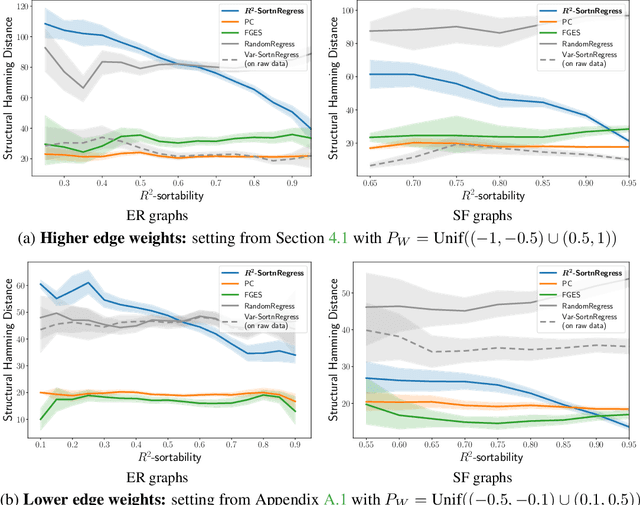
Additive Noise Models (ANM) encode a popular functional assumption that enables learning causal structure from observational data. Due to a lack of real-world data meeting the assumptions, synthetic ANM data are often used to evaluate causal discovery algorithms. Reisach et al. (2021) show that, for common simulation parameters, a variable ordering by increasing variance is closely aligned with a causal order and introduce var-sortability to quantify the alignment. Here, we show that not only variance, but also the fraction of a variable's variance explained by all others, as captured by the coefficient of determination $R^2$, tends to increase along the causal order. Simple baseline algorithms can use $R^2$-sortability to match the performance of established methods. Since $R^2$-sortability is invariant under data rescaling, these algorithms perform equally well on standardized or rescaled data, addressing a key limitation of algorithms exploiting var-sortability. We characterize and empirically assess $R^2$-sortability for different simulation parameters. We show that all simulation parameters can affect $R^2$-sortability and must be chosen deliberately to control the difficulty of the causal discovery task and the real-world plausibility of the simulated data. We provide an implementation of the sortability measures and sortability-based algorithms in our library CausalDisco (https://github.com/CausalDisco/CausalDisco).
Identifying Causal Effects using Instrumental Time Series: Nuisance IV and Correcting for the Past
Mar 11, 2022

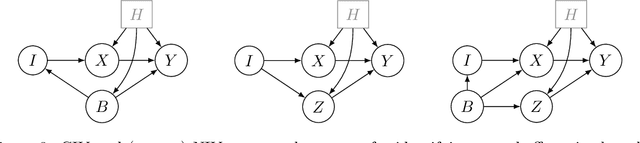
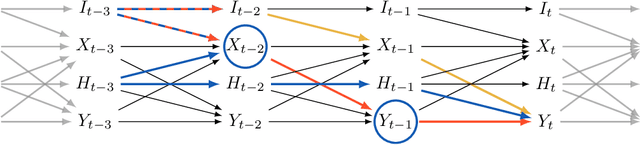
Instrumental variable (IV) regression relies on instruments to infer causal effects from observational data with unobserved confounding. We consider IV regression in time series models, such as vector auto-regressive (VAR) processes. Direct applications of i.i.d. techniques are generally inconsistent as they do not correctly adjust for dependencies in the past. In this paper, we propose methodology for constructing identifying equations that can be used for consistently estimating causal effects. To do so, we develop nuisance IV, which can be of interest even in the i.i.d. case, as it generalizes existing IV methods. We further propose a graph marginalization framework that allows us to apply nuisance and other IV methods in a principled way to time series. Our framework builds on the global Markov property, which we prove holds for VAR processes. For VAR(1) processes, we prove identifiability conditions that relate to Jordan forms and are different from the well-known rank conditions in the i.i.d. case (they do not require as many instruments as covariates, for example). We provide methods, prove their consistency, and show how the inferred causal effect can be used for distribution generalization. Simulation experiments corroborate our theoretical results. We provide ready-to-use Python code.
Learning by Doing: Controlling a Dynamical System using Causality, Control, and Reinforcement Learning
Feb 12, 2022


Questions in causality, control, and reinforcement learning go beyond the classical machine learning task of prediction under i.i.d. observations. Instead, these fields consider the problem of learning how to actively perturb a system to achieve a certain effect on a response variable. Arguably, they have complementary views on the problem: In control, one usually aims to first identify the system by excitation strategies to then apply model-based design techniques to control the system. In (non-model-based) reinforcement learning, one directly optimizes a reward. In causality, one focus is on identifiability of causal structure. We believe that combining the different views might create synergies and this competition is meant as a first step toward such synergies. The participants had access to observational and (offline) interventional data generated by dynamical systems. Track CHEM considers an open-loop problem in which a single impulse at the beginning of the dynamics can be set, while Track ROBO considers a closed-loop problem in which control variables can be set at each time step. The goal in both tracks is to infer controls that drive the system to a desired state. Code is open-sourced ( https://github.com/LearningByDoingCompetition/learningbydoing-comp ) to reproduce the winning solutions of the competition and to facilitate trying out new methods on the competition tasks.
Compositional Abstraction Error and a Category of Causal Models
Mar 29, 2021Interventional causal models describe joint distributions over some variables used to describe a system, one for each intervention setting. They provide a formal recipe for how to move between joint distributions and make predictions about the variables upon intervening on the system. Yet, it is difficult to formalise how we may change the underlying variables used to describe the system, say from fine-grained to coarse-grained variables. Here, we argue that compositionality is a desideratum for model transformations and the associated errors. We develop a framework for model transformations and abstractions with a notion of error that is compositional: when abstracting a reference model M modularly, first obtaining M' and then further simplifying that to obtain M'', then the composite transformation from M to M'' exists and its error can be bounded by the errors incurred by each individual transformation step. Category theory, the study of mathematical objects via the compositional transformations between them, offers a natural language for developing our framework. We introduce a category of finite interventional causal models and, leveraging theory of enriched categories, prove that our framework enjoys the desired compositionality properties.
Beware of the Simulated DAG! Varsortability in Additive Noise Models
Feb 26, 2021



Additive noise models are a class of causal models in which each variable is defined as a function of its causes plus independent noise. In such models, the ordering of variables by marginal variances may be indicative of the causal order. We introduce varsortability as a measure of agreement between the ordering by marginal variance and the causal order. We show how varsortability dominates the performance of continuous structure learning algorithms on synthetic data. On real-world data, varsortability is an implausible and untestable assumption and we find no indication of high varsortability. We aim to raise awareness that varsortability easily occurs in simulated additive noise models. We provide a baseline method that explicitly exploits varsortability and advocate reporting varsortability in benchmarking data.