 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiable Multimodal Causal Representation Learning under Partial Latent Sharing
May 18, 2026Causal representation learning (CRL) seeks to uncover meaningful latent variables and their corresponding causal structure from high-dimensional observational data. Although its significance, CRL identifiability remains a crucial property, as it ensures the recovery of the mechanisms behind the data generation process, and hence the interpretability and robustness of the representation. Proving identifiability in CRL is intrinsically difficult, and we address in this work an even more challenging setting: multimodality. We consider multimodal observed data with a latent partially shared structure. Each modality is generated, through non linear mixing functions, from a specific subset of causal latent variables. Under flexible assumptions and without imposing any parametric distribution on the latent variables, we establish component-wise identifiability guarantees for the causal latent representation. Our identifiability results, furthermore, apply to the undercomplete scenario where we have, for each modality, more observed than latent variables. To instantiate our theoretical analysis, we introduce a Wasserstein-based module to recover the partially shared latent structure. Due to its differentiability, the latter can be easily integrated into all types of architecture, only requiring minimal changes. Extensive experiments on synthetic and realistic datasets validate the superiority of our approach over SOTA methods.
Causal Contrastive Learning for Counterfactual Regression Over Time
Jun 01, 2024Estimating treatment effects over time holds significance in various domains, including precision medicine, epidemiology, economy, and marketing. This paper introduces a unique approach to counterfactual regression over time, emphasizing long-term predictions. Distinguishing itself from existing models like Causal Transformer, our approach highlights the efficacy of employing RNNs for long-term forecasting, complemented by Contrastive Predictive Coding (CPC) and Information Maximization (InfoMax). Emphasizing efficiency, we avoid the need for computationally expensive transformers. Leveraging CPC, our method captures long-term dependencies in the presence of time-varying confounders. Notably, recent models have disregarded the importance of invertible representation, compromising identification assumptions. To remedy this, we employ the InfoMax principle, maximizing a lower bound of mutual information between sequence data and its representation. Our method achieves state-of-the-art counterfactual estimation results using both synthetic and real-world data, marking the pioneering incorporation of Contrastive Predictive Encoding in causal inference.
Transductive Learning for Textual Few-Shot Classification in API-based Embedding Models
Oct 21, 2023



Proprietary and closed APIs are becoming increasingly common to process natural language, and are impacting the practical applications of natural language processing, including few-shot classification. Few-shot classification involves training a model to perform a new classification task with a handful of labeled data. This paper presents three contributions. First, we introduce a scenario where the embedding of a pre-trained model is served through a gated API with compute-cost and data-privacy constraints. Second, we propose a transductive inference, a learning paradigm that has been overlooked by the NLP community. Transductive inference, unlike traditional inductive learning, leverages the statistics of unlabeled data. We also introduce a new parameter-free transductive regularizer based on the Fisher-Rao loss, which can be used on top of the gated API embeddings. This method fully utilizes unlabeled data, does not share any label with the third-party API provider and could serve as a baseline for future research. Third, we propose an improved experimental setting and compile a benchmark of eight datasets involving multiclass classification in four different languages, with up to 151 classes. We evaluate our methods using eight backbone models, along with an episodic evaluation over 1,000 episodes, which demonstrate the superiority of transductive inference over the standard inductive setting.
Causal Dynamic Variational Autoencoder for Counterfactual Regression in Longitudinal Data
Oct 16, 2023Estimating treatment effects over time is relevant in many real-world applications, such as precision medicine, epidemiology, economy, and marketing. Many state-of-the-art methods either assume the observations of all confounders or seek to infer the unobserved ones. We take a different perspective by assuming unobserved risk factors, i.e., adjustment variables that affect only the sequence of outcomes. Under unconfoundedness, we target the Individual Treatment Effect (ITE) estimation with unobserved heterogeneity in the treatment response due to missing risk factors. We address the challenges posed by time-varying effects and unobserved adjustment variables. Led by theoretical results over the validity of the learned adjustment variables and generalization bounds over the treatment effect, we devise Causal DVAE (CDVAE). This model combines a Dynamic Variational Autoencoder (DVAE) framework with a weighting strategy using propensity scores to estimate counterfactual responses. The CDVAE model allows for accurate estimation of ITE and captures the underlying heterogeneity in longitudinal data. Evaluations of our model show superior performance over state-of-the-art models.
Simple Sorting Criteria Help Find the Causal Order in Additive Noise Models
Mar 31, 2023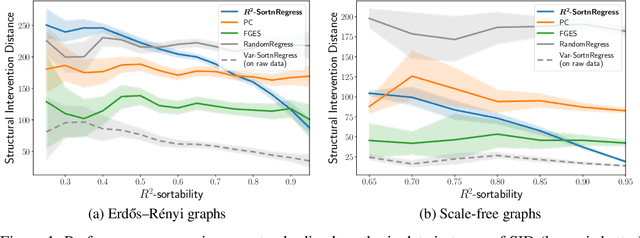
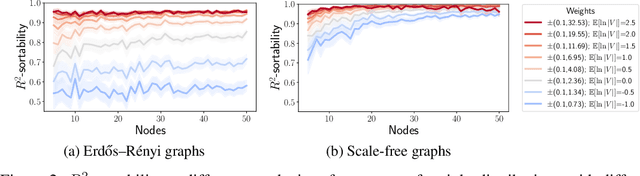
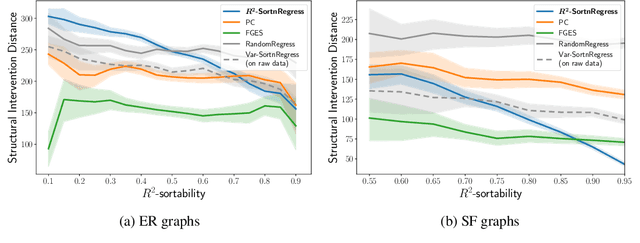
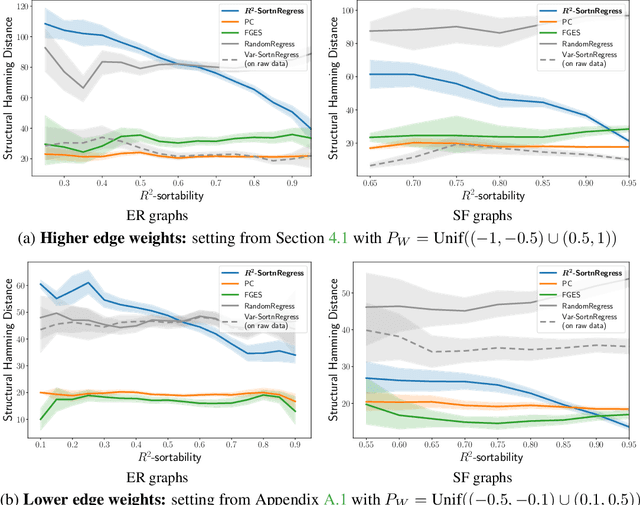
Additive Noise Models (ANM) encode a popular functional assumption that enables learning causal structure from observational data. Due to a lack of real-world data meeting the assumptions, synthetic ANM data are often used to evaluate causal discovery algorithms. Reisach et al. (2021) show that, for common simulation parameters, a variable ordering by increasing variance is closely aligned with a causal order and introduce var-sortability to quantify the alignment. Here, we show that not only variance, but also the fraction of a variable's variance explained by all others, as captured by the coefficient of determination $R^2$, tends to increase along the causal order. Simple baseline algorithms can use $R^2$-sortability to match the performance of established methods. Since $R^2$-sortability is invariant under data rescaling, these algorithms perform equally well on standardized or rescaled data, addressing a key limitation of algorithms exploiting var-sortability. We characterize and empirically assess $R^2$-sortability for different simulation parameters. We show that all simulation parameters can affect $R^2$-sortability and must be chosen deliberately to control the difficulty of the causal discovery task and the real-world plausibility of the simulated data. We provide an implementation of the sortability measures and sortability-based algorithms in our library CausalDisco (https://github.com/CausalDisco/CausalDisco).
Open-Set Likelihood Maximization for Few-Shot Learning
Jan 20, 2023We tackle the Few-Shot Open-Set Recognition (FSOSR) problem, i.e. classifying instances among a set of classes for which we only have a few labeled samples, while simultaneously detecting instances that do not belong to any known class. We explore the popular transductive setting, which leverages the unlabelled query instances at inference. Motivated by the observation that existing transductive methods perform poorly in open-set scenarios, we propose a generalization of the maximum likelihood principle, in which latent scores down-weighing the influence of potential outliers are introduced alongside the usual parametric model. Our formulation embeds supervision constraints from the support set and additional penalties discouraging overconfident predictions on the query set. We proceed with a block-coordinate descent, with the latent scores and parametric model co-optimized alternately, thereby benefiting from each other. We call our resulting formulation \textit{Open-Set Likelihood Optimization} (OSLO). OSLO is interpretable and fully modular; it can be applied on top of any pre-trained model seamlessly. Through extensive experiments, we show that our method surpasses existing inductive and transductive methods on both aspects of open-set recognition, namely inlier classification and outlier detection.
Model-Agnostic Few-Shot Open-Set Recognition
Jun 18, 2022

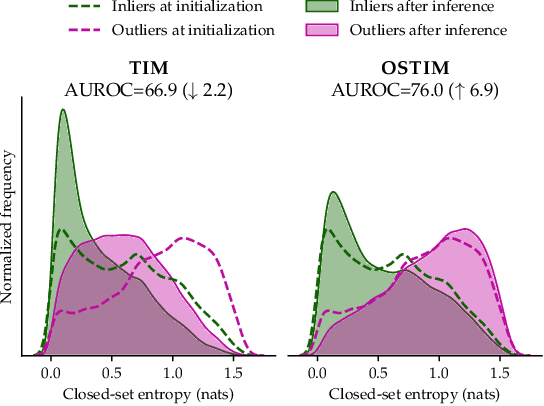
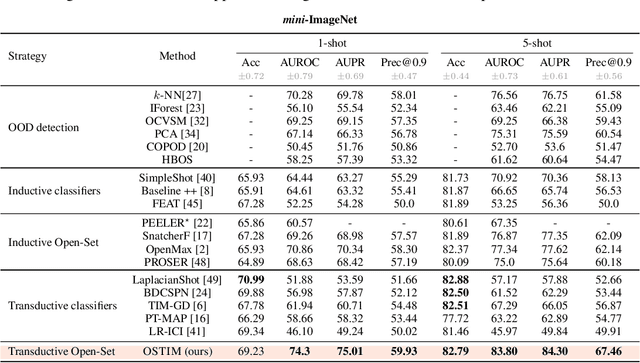
We tackle the Few-Shot Open-Set Recognition (FSOSR) problem, i.e. classifying instances among a set of classes for which we only have few labeled samples, while simultaneously detecting instances that do not belong to any known class. Departing from existing literature, we focus on developing model-agnostic inference methods that can be plugged into any existing model, regardless of its architecture or its training procedure. Through evaluating the embedding's quality of a variety of models, we quantify the intrinsic difficulty of model-agnostic FSOSR. Furthermore, a fair empirical evaluation suggests that the naive combination of a kNN detector and a prototypical classifier ranks before specialized or complex methods in the inductive setting of FSOSR. These observations motivated us to resort to transduction, as a popular and practical relaxation of standard few-shot learning problems. We introduce an Open Set Transductive Information Maximization method OSTIM, which hallucinates an outlier prototype while maximizing the mutual information between extracted features and assignments. Through extensive experiments spanning 5 datasets, we show that OSTIM surpasses both inductive and existing transductive methods in detecting open-set instances while competing with the strongest transductive methods in classifying closed-set instances. We further show that OSTIM's model agnosticity allows it to successfully leverage the strong expressive abilities of the latest architectures and training strategies without any hyperparameter modification, a promising sign that architectural advances to come will continue to positively impact OSTIM's performances.
Few-Shot Image Classification Benchmarks are Too Far From Reality: Build Back Better with Semantic Task Sampling
May 10, 2022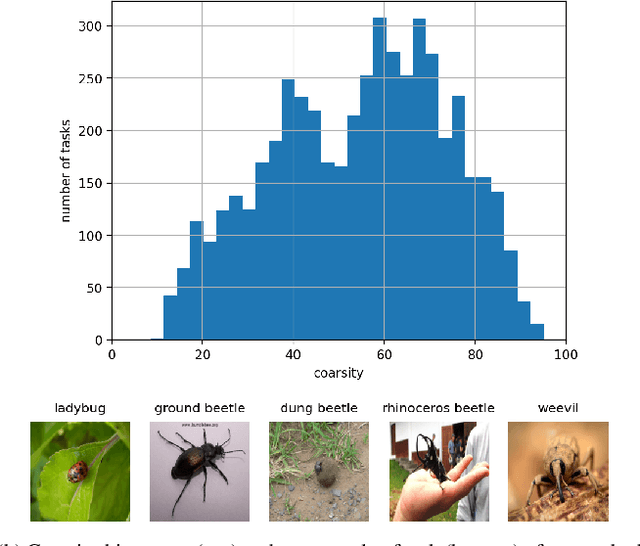
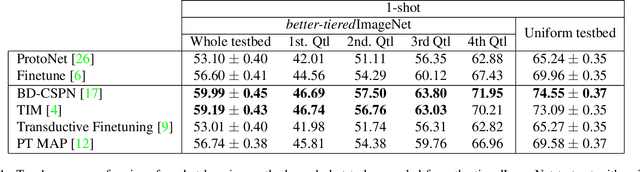
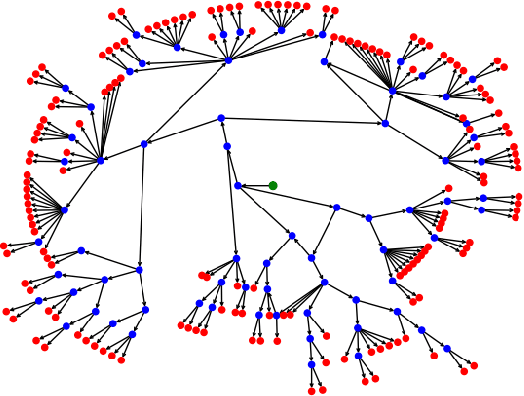
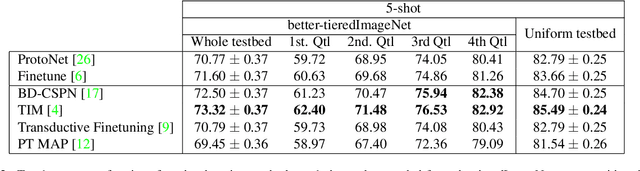
Every day, a new method is published to tackle Few-Shot Image Classification, showing better and better performances on academic benchmarks. Nevertheless, we observe that these current benchmarks do not accurately represent the real industrial use cases that we encountered. In this work, through both qualitative and quantitative studies, we expose that the widely used benchmark tieredImageNet is strongly biased towards tasks composed of very semantically dissimilar classes e.g. bathtub, cabbage, pizza, schipperke, and cardoon. This makes tieredImageNet (and similar benchmarks) irrelevant to evaluate the ability of a model to solve real-life use cases usually involving more fine-grained classification. We mitigate this bias using semantic information about the classes of tieredImageNet and generate an improved, balanced benchmark. Going further, we also introduce a new benchmark for Few-Shot Image Classification using the Danish Fungi 2020 dataset. This benchmark proposes a wide variety of evaluation tasks with various fine-graininess. Moreover, this benchmark includes many-way tasks (e.g. composed of 100 classes), which is a challenging setting yet very common in industrial applications. Our experiments bring out the correlation between the difficulty of a task and the semantic similarity between its classes, as well as a heavy performance drop of state-of-the-art methods on many-way few-shot classification, raising questions about the scaling abilities of these methods. We hope that our work will encourage the community to further question the quality of standard evaluation processes and their relevance to real-life applications.
StreaMulT: Streaming Multimodal Transformer for Heterogeneous and Arbitrary Long Sequential Data
Oct 15, 2021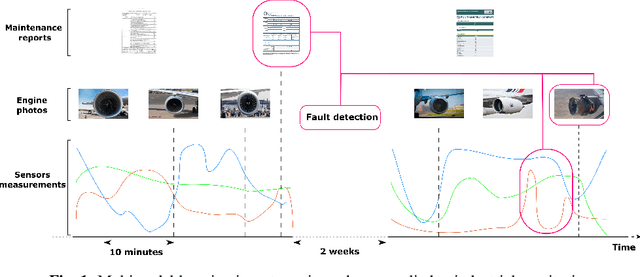
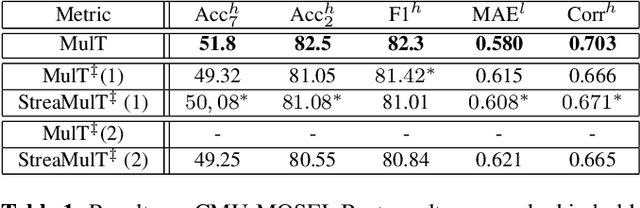
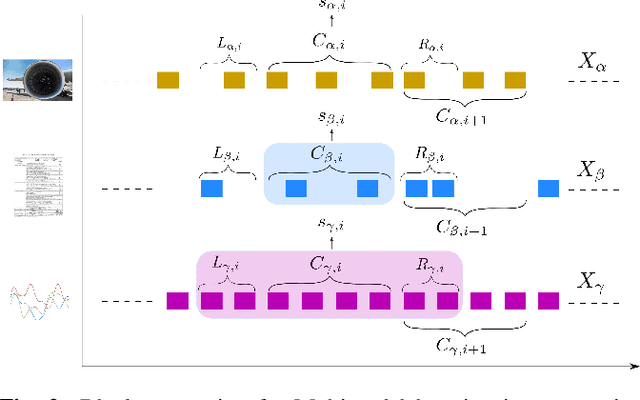
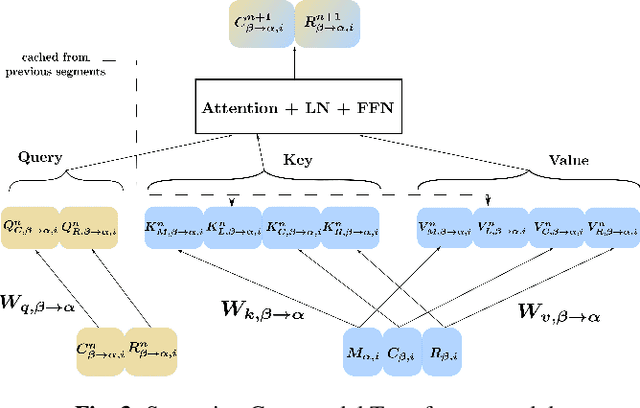
This paper tackles the problem of processing and combining efficiently arbitrary long data streams, coming from different modalities with different acquisition frequencies. Common applications can be, for instance, long-time industrial or real-life systems monitoring from multimodal heterogeneous data (sensor data, monitoring report, images, etc.). To tackle this problem, we propose StreaMulT, a Streaming Multimodal Transformer, relying on cross-modal attention and an augmented memory bank to process arbitrary long input sequences at training time and run in a streaming way at inference. StreaMulT reproduces state-of-the-art results on CMU-MOSEI dataset, while being able to deal with much longer inputs than other models such as previous Multimodal Transformer.
Bridging Few-Shot Learning and Adaptation: New Challenges of Support-Query Shift
May 25, 2021
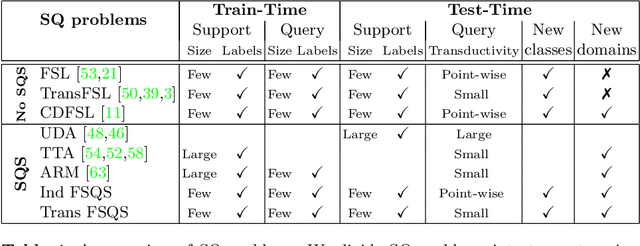

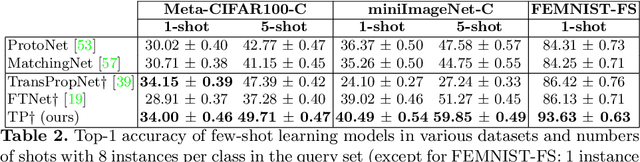
Few-Shot Learning (FSL) algorithms have made substantial progress in learning novel concepts with just a handful of labelled data. To classify query instances from novel classes encountered at test-time, they only require a support set composed of a few labelled samples. FSL benchmarks commonly assume that those queries come from the same distribution as instances in the support set. However, in a realistic set-ting, data distribution is plausibly subject to change, a situation referred to as Distribution Shift (DS). The present work addresses the new and challenging problem of Few-Shot Learning under Support/Query Shift (FSQS) i.e., when support and query instances are sampled from related but different distributions. Our contributions are the following. First, we release a testbed for FSQS, including datasets, relevant baselines and a protocol for a rigorous and reproducible evaluation. Second, we observe that well-established FSL algorithms unsurprisingly suffer from a considerable drop in accuracy when facing FSQS, stressing the significance of our study. Finally, we show that transductive algorithms can limit the inopportune effect of DS. In particular, we study both the role of Batch-Normalization and Optimal Transport (OT) in aligning distributions, bridging Unsupervised Domain Adaptation with FSL. This results in a new method that efficiently combines OT with the celebrated Prototypical Networks. We bring compelling experiments demonstrating the advantage of our method. Our work opens an exciting line of research by providing a testbed and strong baselines. Our code is available at https://github.com/ebennequin/meta-domain-shift.