 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation with Principal Component Analysis
Sep 13, 2022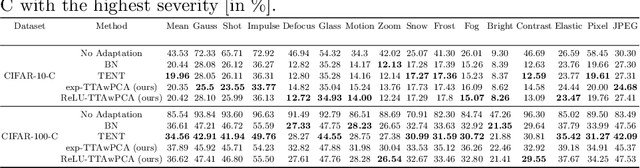
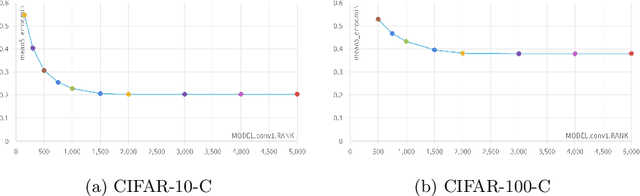

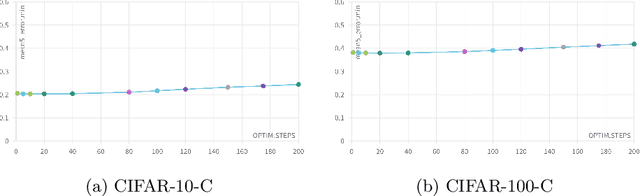
Machine Learning models are prone to fail when test data are different from training data, a situation often encountered in real applications known as distribution shift. While still valid, the training-time knowledge becomes less effective, requiring a test-time adaptation to maintain high performance. Following approaches that assume batch-norm layer and use their statistics for adaptation, we propose a Test-Time Adaptation with Principal Component Analysis (TTAwPCA), which presumes a fitted PCA and adapts at test time a spectral filter based on the singular values of the PCA for robustness to corruptions. TTAwPCA combines three components: the output of a given layer is decomposed using a Principal Component Analysis (PCA), filtered by a penalization of its singular values, and reconstructed with the PCA inverse transform. This generic enhancement adds fewer parameters than current methods. Experiments on CIFAR-10-C and CIFAR- 100-C demonstrate the effectiveness and limits of our method using a unique filter of 2000 parameters.
Towards Clear Expectations for Uncertainty Estimation
Jul 27, 2022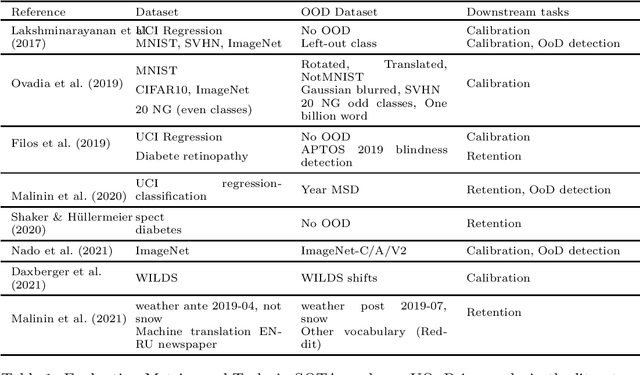
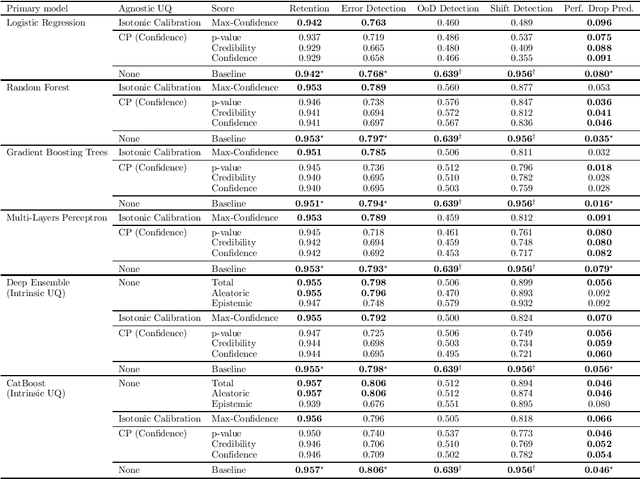
If Uncertainty Quantification (UQ) is crucial to achieve trustworthy Machine Learning (ML), most UQ methods suffer from disparate and inconsistent evaluation protocols. We claim this inconsistency results from the unclear requirements the community expects from UQ. This opinion paper offers a new perspective by specifying those requirements through five downstream tasks where we expect uncertainty scores to have substantial predictive power. We design these downstream tasks carefully to reflect real-life usage of ML models. On an example benchmark of 7 classification datasets, we did not observe statistical superiority of state-of-the-art intrinsic UQ methods against simple baselines. We believe that our findings question the very rationale of why we quantify uncertainty and call for a standardized protocol for UQ evaluation based on metrics proven to be relevant for the ML practitioner.
Performance Prediction Under Dataset Shift
Jun 21, 2022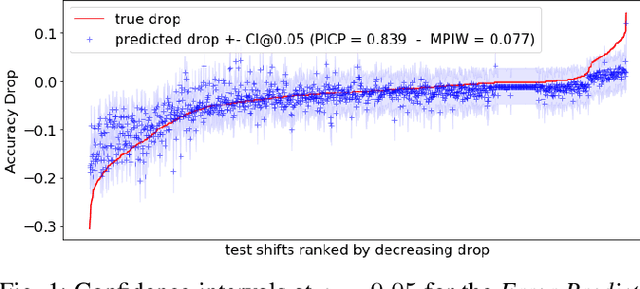
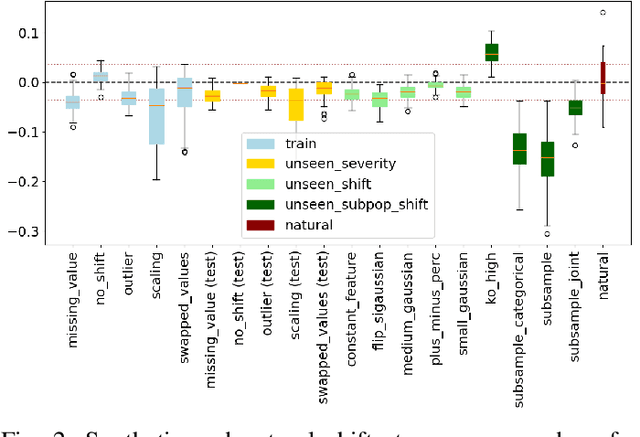
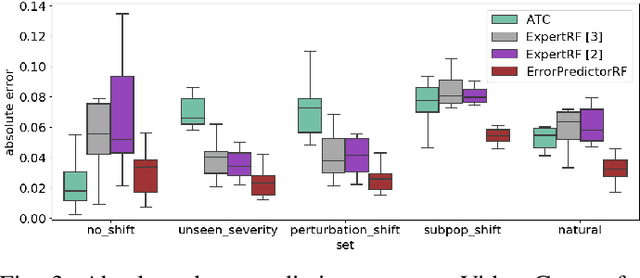
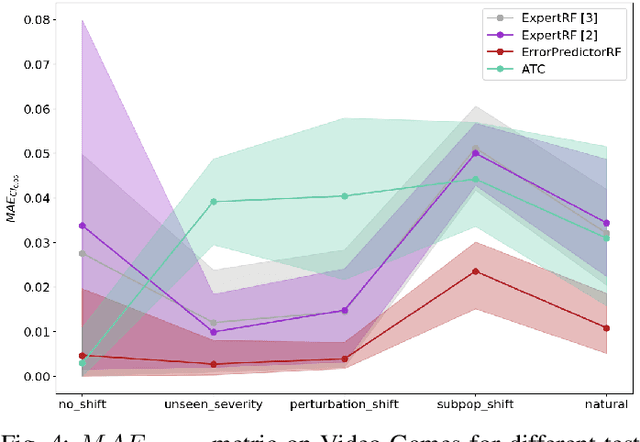
ML models deployed in production often have to face unknown domain changes, fundamentally different from their training settings. Performance prediction models carry out the crucial task of measuring the impact of these changes on model performance. We study the generalization capabilities of various performance prediction models to new domains by learning on generated synthetic perturbations. Empirical validation on a benchmark of ten tabular datasets shows that models based upon state-of-the-art shift detection metrics are not expressive enough to generalize to unseen domains, while Error Predictors bring a consistent improvement in performance prediction under shift. We additionally propose a natural and effortless uncertainty estimation of the predicted accuracy that ensures reliable use of performance predictors. Our implementation is available at https: //github.com/dataiku-research/performance_prediction_under_shift.
Bridging Few-Shot Learning and Adaptation: New Challenges of Support-Query Shift
May 25, 2021
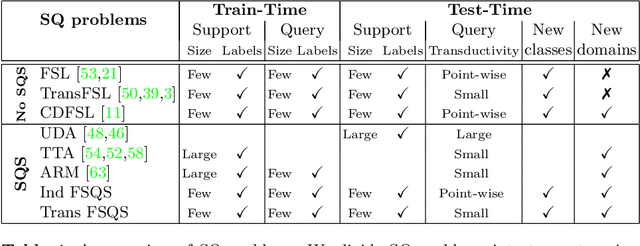

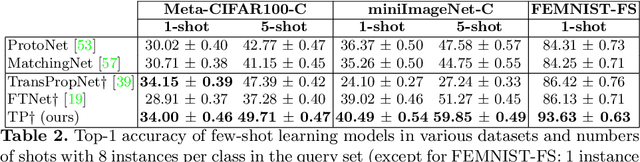
Few-Shot Learning (FSL) algorithms have made substantial progress in learning novel concepts with just a handful of labelled data. To classify query instances from novel classes encountered at test-time, they only require a support set composed of a few labelled samples. FSL benchmarks commonly assume that those queries come from the same distribution as instances in the support set. However, in a realistic set-ting, data distribution is plausibly subject to change, a situation referred to as Distribution Shift (DS). The present work addresses the new and challenging problem of Few-Shot Learning under Support/Query Shift (FSQS) i.e., when support and query instances are sampled from related but different distributions. Our contributions are the following. First, we release a testbed for FSQS, including datasets, relevant baselines and a protocol for a rigorous and reproducible evaluation. Second, we observe that well-established FSL algorithms unsurprisingly suffer from a considerable drop in accuracy when facing FSQS, stressing the significance of our study. Finally, we show that transductive algorithms can limit the inopportune effect of DS. In particular, we study both the role of Batch-Normalization and Optimal Transport (OT) in aligning distributions, bridging Unsupervised Domain Adaptation with FSL. This results in a new method that efficiently combines OT with the celebrated Prototypical Networks. We bring compelling experiments demonstrating the advantage of our method. Our work opens an exciting line of research by providing a testbed and strong baselines. Our code is available at https://github.com/ebennequin/meta-domain-shift.
Stochastic Adversarial Gradient Embedding for Active Domain Adaptation
Dec 03, 2020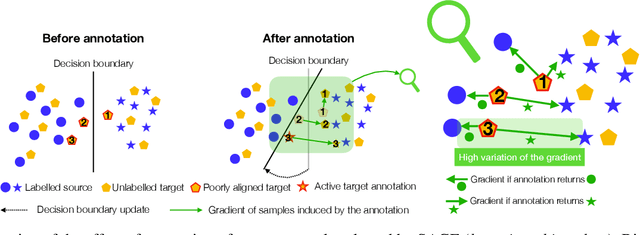



Unsupervised Domain Adaptation (UDA) aims to bridge the gap between a source domain, where labelled data are available, and a target domain only represented with unlabelled data. If domain invariant representations have dramatically improved the adaptability of models, to guarantee their good transferability remains a challenging problem. This paper addresses this problem by using active learning to annotate a small budget of target data. Although this setup, called Active Domain Adaptation (ADA), deviates from UDA's standard setup, a wide range of practical applications are faced with this situation. To this purpose, we introduce \textit{Stochastic Adversarial Gradient Embedding} (SAGE), a framework that makes a triple contribution to ADA. First, we select for annotation target samples that are likely to improve the representations' transferability by measuring the variation, before and after annotation, of the transferability loss gradient. Second, we increase sampling diversity by promoting different gradient directions. Third, we introduce a novel training procedure for actively incorporating target samples when learning invariant representations. SAGE is based on solid theoretical ground and validated on various UDA benchmarks against several baselines. Our empirical investigation demonstrates that SAGE takes the best of uncertainty \textit{vs} diversity samplings and improves representations transferability substantially.
Target Consistency for Domain Adaptation: when Robustness meets Transferability
Jun 30, 2020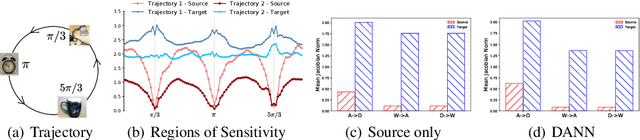
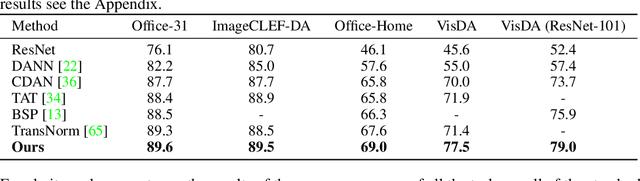

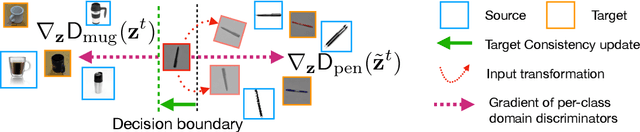
Learning Invariant Representations has been successfully applied for reconciling a source and a target domain for Unsupervised Domain Adaptation. By investigating the robustness of such methods under the prism of the cluster assumption, we bring new evidence that invariance with a low source risk does not guarantee a well-performing target classifier. More precisely, we show that the cluster assumption is violated in the target domain despite being maintained in the source domain, indicating a lack of robustness of the target classifier. To address this problem, we demonstrate the importance of enforcing the cluster assumption in the target domain, named Target Consistency (TC), especially when paired with Class-Level InVariance (CLIV). Our new approach results in a significant improvement, on both image classification and segmentation benchmarks, over state-of-the-art methods based on invariant representations. Importantly, our method is flexible and easy to implement, making it a complementary technique to existing approaches for improving transferability of representations.
Robust Domain Adaptation: Representations, Weights and Inductive Bias
Jun 24, 2020
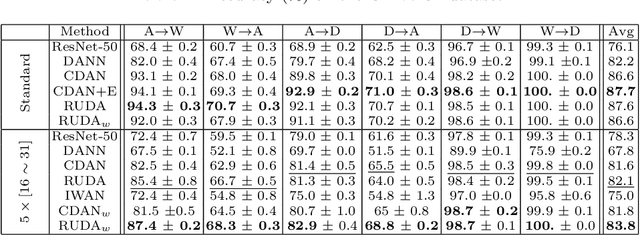

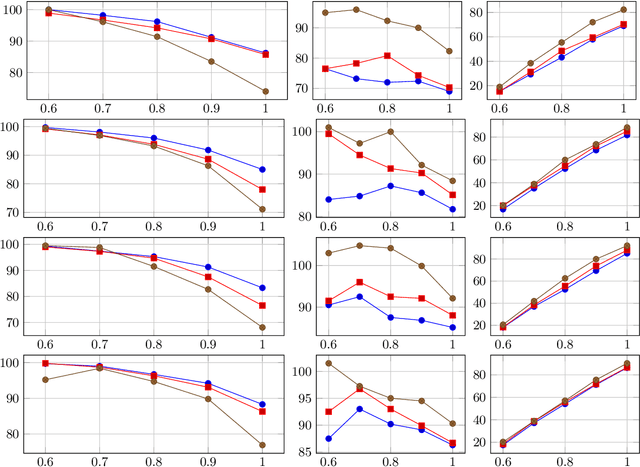
Unsupervised Domain Adaptation (UDA) has attracted a lot of attention in the last ten years. The emergence of Domain Invariant Representations (IR) has improved drastically the transferability of representations from a labelled source domain to a new and unlabelled target domain. However, a potential pitfall of this approach, namely the presence of \textit{label shift}, has been brought to light. Some works address this issue with a relaxed version of domain invariance obtained by weighting samples, a strategy often referred to as Importance Sampling. From our point of view, the theoretical aspects of how Importance Sampling and Invariant Representations interact in UDA have not been studied in depth. In the present work, we present a bound of the target risk which incorporates both weights and invariant representations. Our theoretical analysis highlights the role of inductive bias in aligning distributions across domains. We illustrate it on standard benchmarks by proposing a new learning procedure for UDA. We observed empirically that weak inductive bias makes adaptation more robust. The elaboration of stronger inductive bias is a promising direction for new UDA algorithms.
Learning Invariant Representations for Sentiment Analysis: The Missing Material is Datasets
Jul 29, 2019

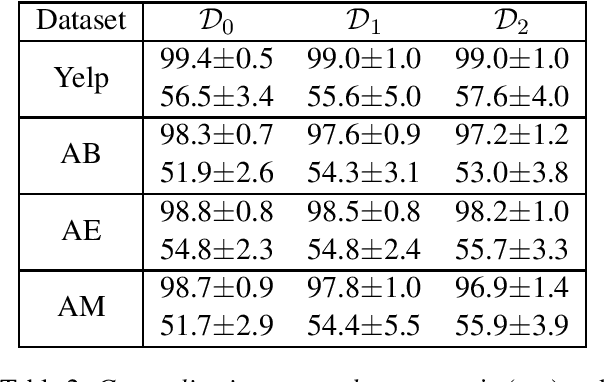
Learning representations which remain invariant to a nuisance factor has a great interest in Domain Adaptation, Transfer Learning, and Fair Machine Learning. Finding such representations becomes highly challenging in NLP tasks since the nuisance factor is entangled in a raw text. To our knowledge, a major issue is also that only few NLP datasets allow assessing the impact of such factor. In this paper, we introduce two generalization metrics to assess model robustness to a nuisance factor: \textit{generalization under target bias} and \textit{generalization onto unknown}. We combine those metrics with a simple data filtering approach to control the impact of the nuisance factor on the data and thus to build experimental biased datasets. We apply our method to standard datasets of the literature (\textit{Amazon} and \textit{Yelp}). Our work shows that a simple text classification baseline (i.e., sentiment analysis on reviews) may be badly affected by the \textit{product ID} (considered as a nuisance factor) when learning the polarity of a review. The method proposed is generic and applicable as soon as the nuisance variable is annotated in the dataset.
Hidden Covariate Shift: A Minimal Assumption For Domain Adaptation
Jul 29, 2019



Unsupervised Domain Adaptation aims to learn a model on a source domain with labeled data in order to perform well on unlabeled data of a target domain. Current approaches focus on learning \textit{Domain Invariant Representations}. It relies on the assumption that such representations are well-suited for learning the supervised task in the target domain. We rather believe that a better and minimal assumption for performing Domain Adaptation is the \textit{Hidden Covariate Shift} hypothesis. Such approach consists in learning a representation of the data such that the label distribution conditioned on this representation is domain invariant. From the Hidden Covariate Shift assumption, we derive an optimization procedure which learns to match an estimated joint distribution on the target domain and a re-weighted joint distribution on the source domain. The re-weighting is done in the representation space and is learned during the optimization procedure. We show on synthetic data and real world data that our approach deals with both \textit{Target Shift} and \textit{Concept Drift}. We report state-of-the-art performances on Amazon Reviews dataset \cite{blitzer2007biographies} demonstrating the viability of this approach.