 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Adversarial Gradient Embedding for Active Domain Adaptation
Dec 03, 2020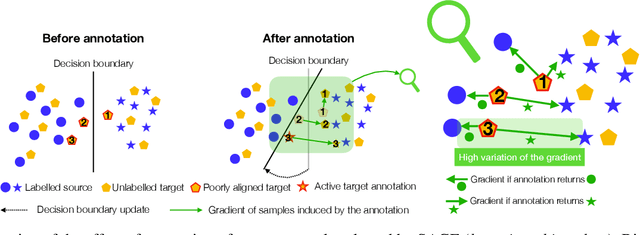



Unsupervised Domain Adaptation (UDA) aims to bridge the gap between a source domain, where labelled data are available, and a target domain only represented with unlabelled data. If domain invariant representations have dramatically improved the adaptability of models, to guarantee their good transferability remains a challenging problem. This paper addresses this problem by using active learning to annotate a small budget of target data. Although this setup, called Active Domain Adaptation (ADA), deviates from UDA's standard setup, a wide range of practical applications are faced with this situation. To this purpose, we introduce \textit{Stochastic Adversarial Gradient Embedding} (SAGE), a framework that makes a triple contribution to ADA. First, we select for annotation target samples that are likely to improve the representations' transferability by measuring the variation, before and after annotation, of the transferability loss gradient. Second, we increase sampling diversity by promoting different gradient directions. Third, we introduce a novel training procedure for actively incorporating target samples when learning invariant representations. SAGE is based on solid theoretical ground and validated on various UDA benchmarks against several baselines. Our empirical investigation demonstrates that SAGE takes the best of uncertainty \textit{vs} diversity samplings and improves representations transferability substantially.
Robust Domain Adaptation: Representations, Weights and Inductive Bias
Jun 24, 2020
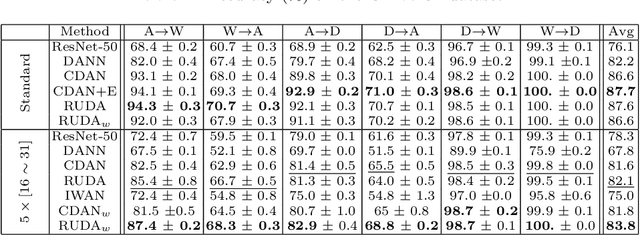
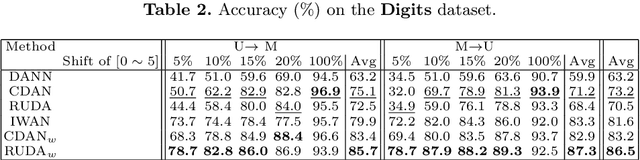

Unsupervised Domain Adaptation (UDA) has attracted a lot of attention in the last ten years. The emergence of Domain Invariant Representations (IR) has improved drastically the transferability of representations from a labelled source domain to a new and unlabelled target domain. However, a potential pitfall of this approach, namely the presence of \textit{label shift}, has been brought to light. Some works address this issue with a relaxed version of domain invariance obtained by weighting samples, a strategy often referred to as Importance Sampling. From our point of view, the theoretical aspects of how Importance Sampling and Invariant Representations interact in UDA have not been studied in depth. In the present work, we present a bound of the target risk which incorporates both weights and invariant representations. Our theoretical analysis highlights the role of inductive bias in aligning distributions across domains. We illustrate it on standard benchmarks by proposing a new learning procedure for UDA. We observed empirically that weak inductive bias makes adaptation more robust. The elaboration of stronger inductive bias is a promising direction for new UDA algorithms.
Learning Invariant Representations for Sentiment Analysis: The Missing Material is Datasets
Jul 29, 2019

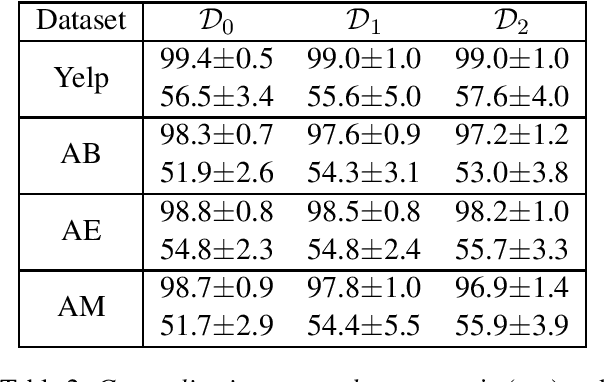
Learning representations which remain invariant to a nuisance factor has a great interest in Domain Adaptation, Transfer Learning, and Fair Machine Learning. Finding such representations becomes highly challenging in NLP tasks since the nuisance factor is entangled in a raw text. To our knowledge, a major issue is also that only few NLP datasets allow assessing the impact of such factor. In this paper, we introduce two generalization metrics to assess model robustness to a nuisance factor: \textit{generalization under target bias} and \textit{generalization onto unknown}. We combine those metrics with a simple data filtering approach to control the impact of the nuisance factor on the data and thus to build experimental biased datasets. We apply our method to standard datasets of the literature (\textit{Amazon} and \textit{Yelp}). Our work shows that a simple text classification baseline (i.e., sentiment analysis on reviews) may be badly affected by the \textit{product ID} (considered as a nuisance factor) when learning the polarity of a review. The method proposed is generic and applicable as soon as the nuisance variable is annotated in the dataset.
Hidden Covariate Shift: A Minimal Assumption For Domain Adaptation
Jul 29, 2019



Unsupervised Domain Adaptation aims to learn a model on a source domain with labeled data in order to perform well on unlabeled data of a target domain. Current approaches focus on learning \textit{Domain Invariant Representations}. It relies on the assumption that such representations are well-suited for learning the supervised task in the target domain. We rather believe that a better and minimal assumption for performing Domain Adaptation is the \textit{Hidden Covariate Shift} hypothesis. Such approach consists in learning a representation of the data such that the label distribution conditioned on this representation is domain invariant. From the Hidden Covariate Shift assumption, we derive an optimization procedure which learns to match an estimated joint distribution on the target domain and a re-weighted joint distribution on the source domain. The re-weighting is done in the representation space and is learned during the optimization procedure. We show on synthetic data and real world data that our approach deals with both \textit{Target Shift} and \textit{Concept Drift}. We report state-of-the-art performances on Amazon Reviews dataset \cite{blitzer2007biographies} demonstrating the viability of this approach.