 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Domain Adaptation: Representations, Weights and Inductive Bias
Paper and Code

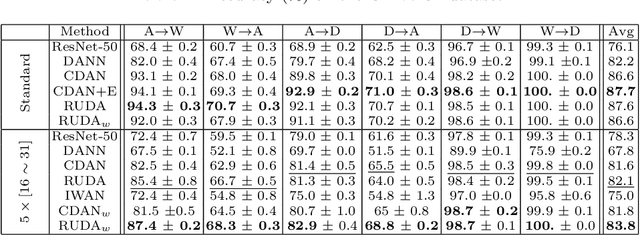
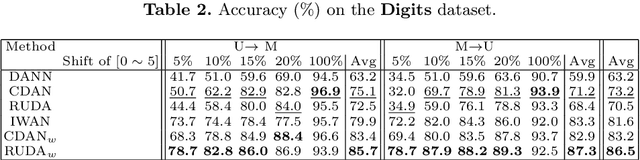

Unsupervised Domain Adaptation (UDA) has attracted a lot of attention in the last ten years. The emergence of Domain Invariant Representations (IR) has improved drastically the transferability of representations from a labelled source domain to a new and unlabelled target domain. However, a potential pitfall of this approach, namely the presence of \textit{label shift}, has been brought to light. Some works address this issue with a relaxed version of domain invariance obtained by weighting samples, a strategy often referred to as Importance Sampling. From our point of view, the theoretical aspects of how Importance Sampling and Invariant Representations interact in UDA have not been studied in depth. In the present work, we present a bound of the target risk which incorporates both weights and invariant representations. Our theoretical analysis highlights the role of inductive bias in aligning distributions across domains. We illustrate it on standard benchmarks by proposing a new learning procedure for UDA. We observed empirically that weak inductive bias makes adaptation more robust. The elaboration of stronger inductive bias is a promising direction for new UDA algorithms.