 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLook Beyond Bias with Entropic Adversarial Data Augmentation
Jan 10, 2023
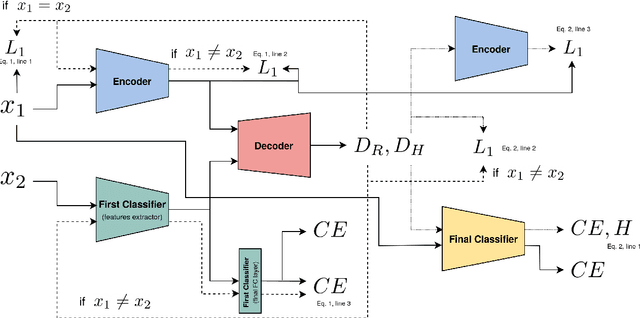

Deep neural networks do not discriminate between spurious and causal patterns, and will only learn the most predictive ones while ignoring the others. This shortcut learning behaviour is detrimental to a network's ability to generalize to an unknown test-time distribution in which the spurious correlations do not hold anymore. Debiasing methods were developed to make networks robust to such spurious biases but require to know in advance if a dataset is biased and make heavy use of minority counterexamples that do not display the majority bias of their class. In this paper, we argue that such samples should not be necessarily needed because the ''hidden'' causal information is often also contained in biased images. To study this idea, we propose 3 publicly released synthetic classification benchmarks, exhibiting predictive classification shortcuts, each of a different and challenging nature, without any minority samples acting as counterexamples. First, we investigate the effectiveness of several state-of-the-art strategies on our benchmarks and show that they do not yield satisfying results on them. Then, we propose an architecture able to succeed on our benchmarks, despite their unusual properties, using an entropic adversarial data augmentation training scheme. An encoder-decoder architecture is tasked to produce images that are not recognized by a classifier, by maximizing the conditional entropy of its outputs, and keep as much as possible of the initial content. A precise control of the information destroyed, via a disentangling process, enables us to remove the shortcut and leave everything else intact. Furthermore, results competitive with the state-of-the-art on the BAR dataset ensure the applicability of our method in real-life situations.
Learning Less Generalizable Patterns with an Asymmetrically Trained Double Classifier for Better Test-Time Adaptation
Oct 17, 2022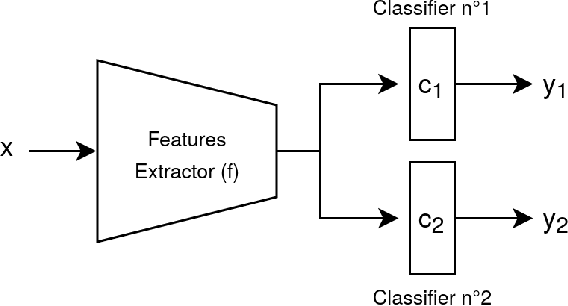
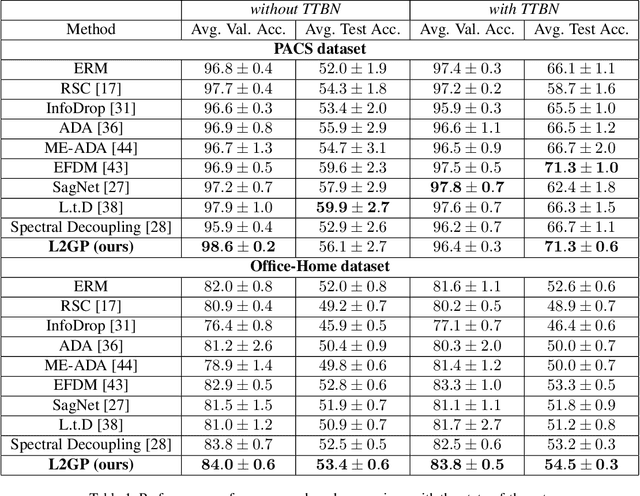
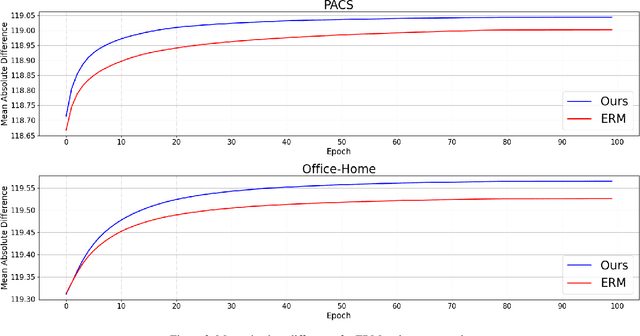
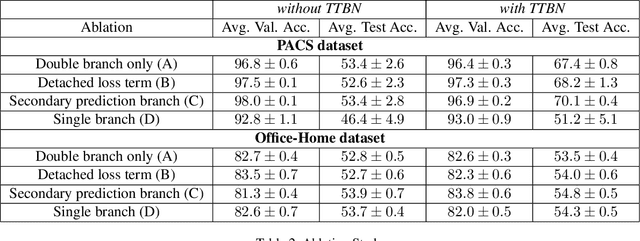
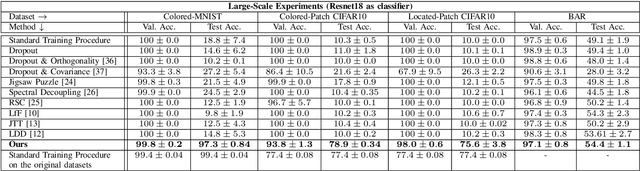
Deep neural networks often fail to generalize outside of their training distribution, in particular when only a single data domain is available during training. While test-time adaptation has yielded encouraging results in this setting, we argue that, to reach further improvements, these approaches should be combined with training procedure modifications aiming to learn a more diverse set of patterns. Indeed, test-time adaptation methods usually have to rely on a limited representation because of the shortcut learning phenomenon: only a subset of the available predictive patterns is learned with standard training. In this paper, we first show that the combined use of existing training-time strategies, and test-time batch normalization, a simple adaptation method, does not always improve upon the test-time adaptation alone on the PACS benchmark. Furthermore, experiments on Office-Home show that very few training-time methods improve upon standard training, with or without test-time batch normalization. We therefore propose a novel approach using a pair of classifiers and a shortcut patterns avoidance loss that mitigates the shortcut learning behavior by reducing the generalization ability of the secondary classifier, using the additional shortcut patterns avoidance loss that encourages the learning of samples specific patterns. The primary classifier is trained normally, resulting in the learning of both the natural and the more complex, less generalizable, features. Our experiments show that our method improves upon the state-of-the-art results on both benchmarks and benefits the most to test-time batch normalization.
Test-Time Adaptation with Principal Component Analysis
Sep 13, 2022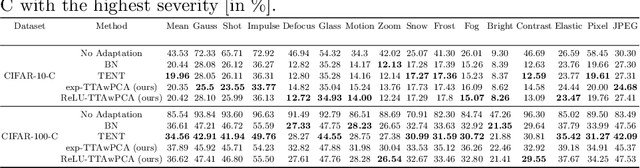
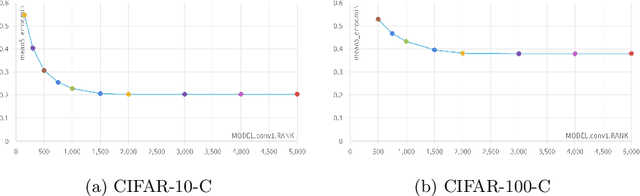

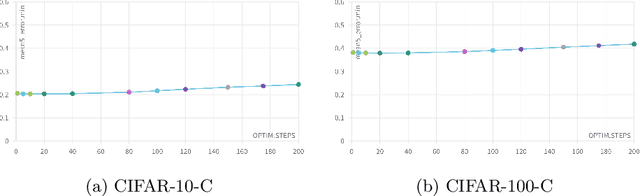
Machine Learning models are prone to fail when test data are different from training data, a situation often encountered in real applications known as distribution shift. While still valid, the training-time knowledge becomes less effective, requiring a test-time adaptation to maintain high performance. Following approaches that assume batch-norm layer and use their statistics for adaptation, we propose a Test-Time Adaptation with Principal Component Analysis (TTAwPCA), which presumes a fitted PCA and adapts at test time a spectral filter based on the singular values of the PCA for robustness to corruptions. TTAwPCA combines three components: the output of a given layer is decomposed using a Principal Component Analysis (PCA), filtered by a penalization of its singular values, and reconstructed with the PCA inverse transform. This generic enhancement adds fewer parameters than current methods. Experiments on CIFAR-10-C and CIFAR- 100-C demonstrate the effectiveness and limits of our method using a unique filter of 2000 parameters.
Swapping Semantic Contents for Mixing Images
May 20, 2022
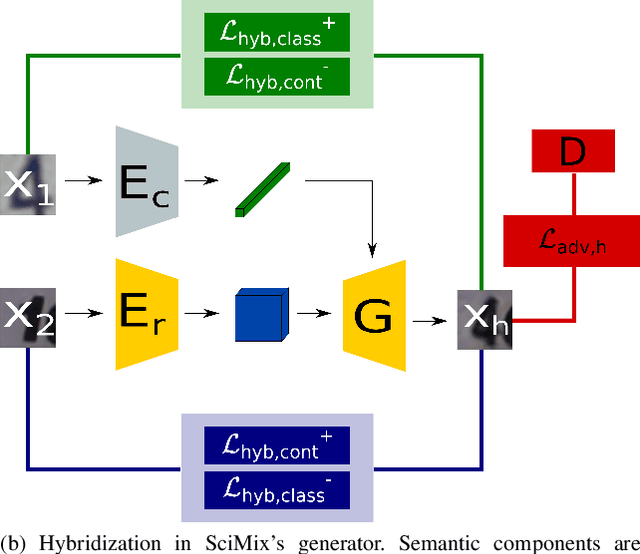


Deep architecture have proven capable of solving many tasks provided a sufficient amount of labeled data. In fact, the amount of available labeled data has become the principal bottleneck in low label settings such as Semi-Supervised Learning. Mixing Data Augmentations do not typically yield new labeled samples, as indiscriminately mixing contents creates between-class samples. In this work, we introduce the SciMix framework that can learn to generator to embed a semantic style code into image backgrounds, we obtain new mixing scheme for data augmentation. We then demonstrate that SciMix yields novel mixed samples that inherit many characteristics from their non-semantic parents. Afterwards, we verify those samples can be used to improve the performance semi-supervised frameworks like Mean Teacher or Fixmatch, and even fully supervised learning on a small labeled dataset.
Encouraging Intra-Class Diversity Through a Reverse Contrastive Loss for Better Single-Source Domain Generalization
Jun 15, 2021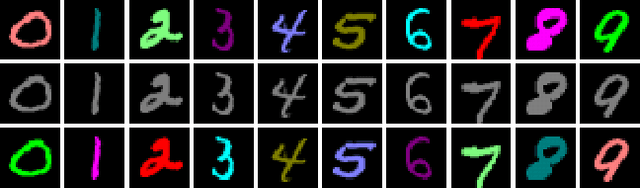
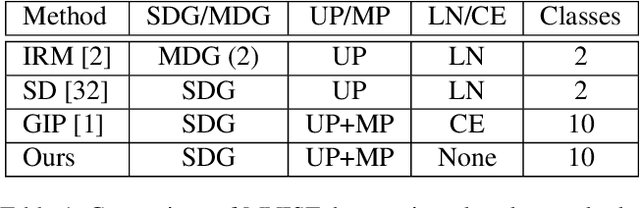
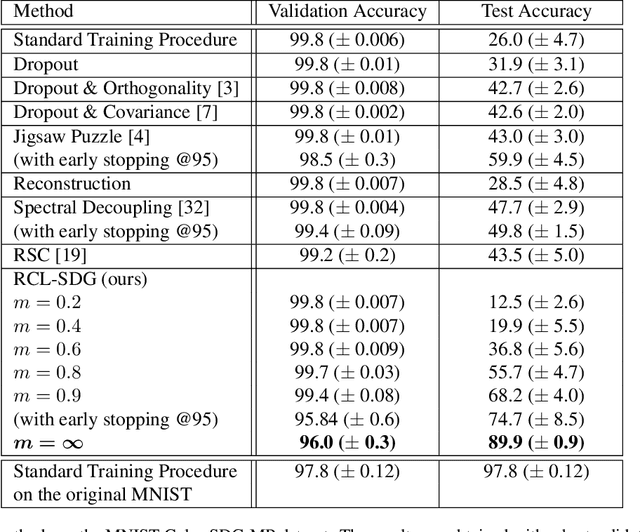
Traditional deep learning algorithms often fail to generalize when they are tested outside of the domain of training data. Because data distributions can change dynamically in real-life applications once a learned model is deployed, in this paper we are interested in single-source domain generalization (SDG) which aims to develop deep learning algorithms able to generalize from a single training domain where no information about the test domain is available at training time. Firstly, we design two simple MNISTbased SDG benchmarks, namely MNIST Color SDG-MP and MNIST Color SDG-UP, which highlight the two different fundamental SDG issues of increasing difficulties: 1) a class-correlated pattern in the training domain is missing (SDG-MP), or 2) uncorrelated with the class (SDG-UP), in the testing data domain. This is in sharp contrast with the current domain generalization (DG) benchmarks which mix up different correlation and variation factors and thereby make hard to disentangle success or failure factors when benchmarking DG algorithms. We further evaluate several state-of-the-art SDG algorithms through our simple benchmark, namely MNIST Color SDG-MP, and show that the issue SDG-MP is largely unsolved despite of a decade of efforts in developing DG algorithms. Finally, we also propose a partially reversed contrastive loss to encourage intra-class diversity and find less strongly correlated patterns, to deal with SDG-MP and show that the proposed approach is very effective on our MNIST Color SDG-MP benchmark.