 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mixtures and Products for Ensemble Aggregation: A Likelihood Perspective on Generalized Means
Mar 04, 2026Density aggregation is a central problem in machine learning, for instance when combining predictions from a Deep Ensemble. The choice of aggregation remains an open question with two commonly proposed approaches being linear pooling (probability averaging) and geometric pooling (logit averaging). In this work, we address this question by studying the normalized generalized mean of order $r \in \mathbb{R} \cup \{-\infty,+\infty\}$ through the lens of log-likelihood, the standard evaluation criterion in machine learning. This provides a unifying aggregation formalism and shows different optimal configurations for different situations. We show that the regime $r \in [0,1]$ is the only range ensuring systematic improvements relative to individual distributions, thereby providing a principled justification for the reliability and widespread practical use of linear ($r=1$) and geometric ($r=0$) pooling. In contrast, we show that aggregation rules with $r \notin [0,1]$ may fail to provide consistent gains with explicit counterexamples. Finally, we corroborate our theoretical findings with empirical evaluations using Deep Ensembles on image and text classification benchmarks.
When Are Two Scores Better Than One? Investigating Ensembles of Diffusion Models
Jan 16, 2026Diffusion models now generate high-quality, diverse samples, with an increasing focus on more powerful models. Although ensembling is a well-known way to improve supervised models, its application to unconditional score-based diffusion models remains largely unexplored. In this work we investigate whether it provides tangible benefits for generative modelling. We find that while ensembling the scores generally improves the score-matching loss and model likelihood, it fails to consistently enhance perceptual quality metrics such as FID on image datasets. We confirm this observation across a breadth of aggregation rules using Deep Ensembles, Monte Carlo Dropout, on CIFAR-10 and FFHQ. We attempt to explain this discrepancy by investigating possible explanations, such as the link between score estimation and image quality. We also look into tabular data through random forests, and find that one aggregation strategy outperforms the others. Finally, we provide theoretical insights into the summing of score models, which shed light not only on ensembling but also on several model composition techniques (e.g. guidance).
Leveraging multimodal explanatory annotations for video interpretation with Modality Specific Dataset
Apr 15, 2025We examine the impact of concept-informed supervision on multimodal video interpretation models using MOByGaze, a dataset containing human-annotated explanatory concepts. We introduce Concept Modality Specific Datasets (CMSDs), which consist of data subsets categorized by the modality (visual, textual, or audio) of annotated concepts. Models trained on CMSDs outperform those using traditional legacy training in both early and late fusion approaches. Notably, this approach enables late fusion models to achieve performance close to that of early fusion models. These findings underscore the importance of modality-specific annotations in developing robust, self-explainable video models and contribute to advancing interpretable multimodal learning in complex video analysis.
Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
Nov 17, 2023Online High Definition Map (HDMap) estimation from sensors offers a low-cost alternative to manually acquired HDMaps. As such, it promises to lighten costs for already HDMap-reliant Autonomous Driving systems, and potentially even spread their use to new systems. In this paper, we propose to improve online HDMap estimation by accounting for already existing maps. We identify 3 reasonable types of useful existing maps (minimalist, noisy, and outdated). We also introduce MapEX, a novel online HDMap estimation framework that accounts for existing maps. MapEX achieves this by encoding map elements into query tokens and by refining the matching algorithm used to train classic query based map estimation models. We demonstrate that MapEX brings significant improvements on the nuScenes dataset. For instance, MapEX - given noisy maps - improves by 38% over the MapTRv2 detector it is based on and by 16% over the current SOTA.
Swapping Semantic Contents for Mixing Images
May 20, 2022
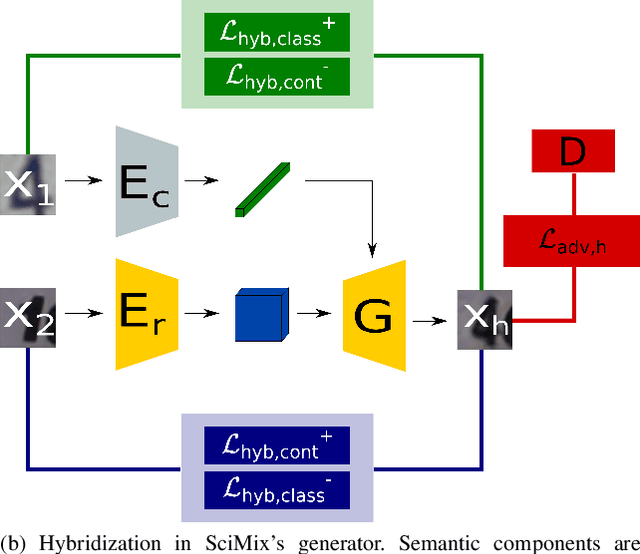


Deep architecture have proven capable of solving many tasks provided a sufficient amount of labeled data. In fact, the amount of available labeled data has become the principal bottleneck in low label settings such as Semi-Supervised Learning. Mixing Data Augmentations do not typically yield new labeled samples, as indiscriminately mixing contents creates between-class samples. In this work, we introduce the SciMix framework that can learn to generator to embed a semantic style code into image backgrounds, we obtain new mixing scheme for data augmentation. We then demonstrate that SciMix yields novel mixed samples that inherit many characteristics from their non-semantic parents. Afterwards, we verify those samples can be used to improve the performance semi-supervised frameworks like Mean Teacher or Fixmatch, and even fully supervised learning on a small labeled dataset.
Towards efficient feature sharing in MIMO architectures
May 20, 2022

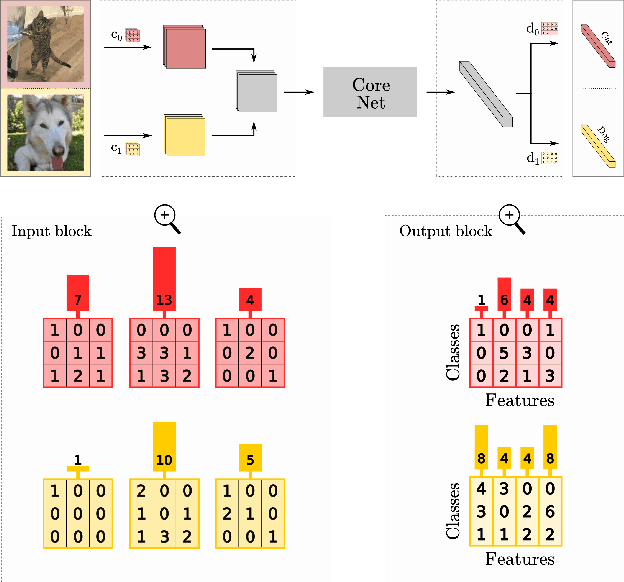
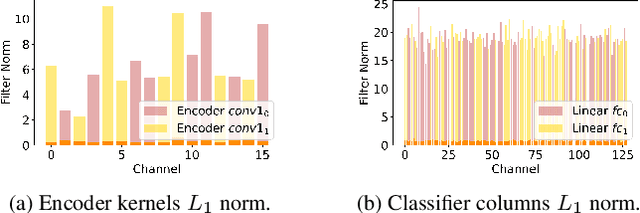
Multi-input multi-output architectures propose to train multiple subnetworks within one base network and then average the subnetwork predictions to benefit from ensembling for free. Despite some relative success, these architectures are wasteful in their use of parameters. Indeed, we highlight in this paper that the learned subnetwork fail to share even generic features which limits their applicability on smaller mobile and AR/VR devices. We posit this behavior stems from an ill-posed part of the multi-input multi-output framework. To solve this issue, we propose a novel unmixing step in MIMO architectures that allows subnetworks to properly share features. Preliminary experiments on CIFAR-100 show our adjustments allow feature sharing and improve model performance for small architectures.
A theory of independent mechanisms for extrapolation in generative models
Apr 01, 2020
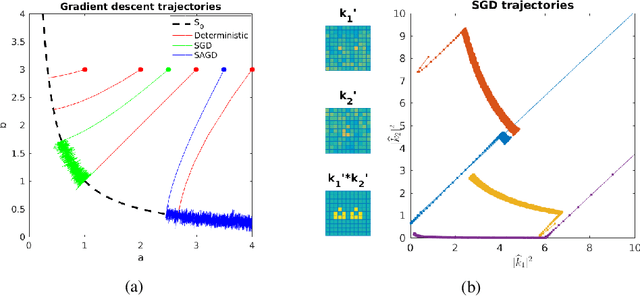
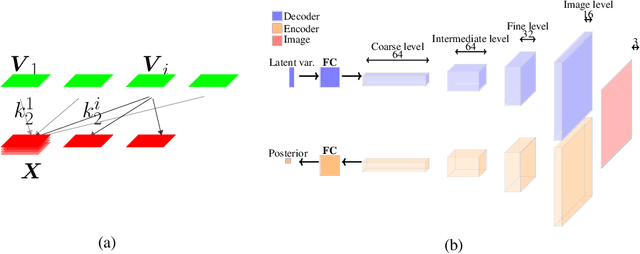
Deep generative models reproduce complex empirical data but cannot extrapolate to novel environments. An intuitive idea to promote extrapolation capabilities is to enforce the architecture to have the modular structure of a causal graphical model, where one can intervene on each module independently of the others in the graph. We develop a framework to formalize this intuition, using the principle of Independent Causal Mechanisms, and show how over-parameterization of generative neural networks can hinder extrapolation capabilities. Our experiments on the generation of human faces shows successive layers of a generator architecture implement independent mechanisms to some extent, allowing meaningful extrapolations. Finally, we illustrate that independence of mechanisms may be enforced during training to improve extrapolation.
Counterfactuals uncover the modular structure of deep generative models
Dec 08, 2018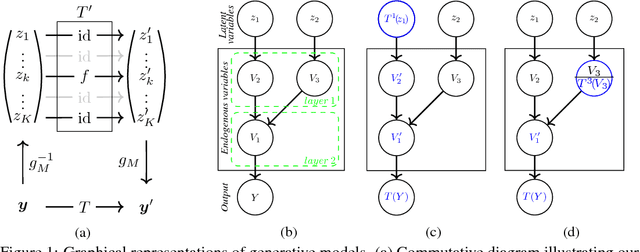

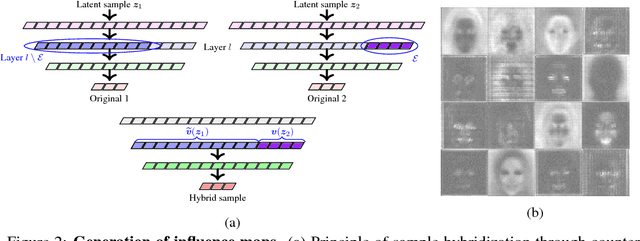

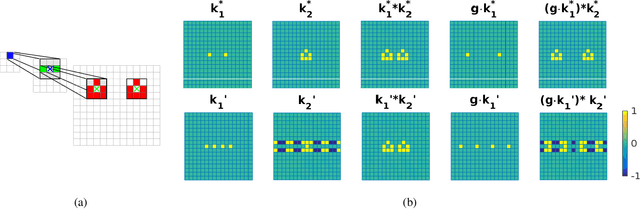
Deep generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are important tools to capture and investigate the properties of complex empirical data. However, the complexity of their inner elements makes their functioning challenging to assess and modify. In this respect, these architectures behave as black box models. In order to better understand the function of such networks, we analyze their modularity based on the counterfactual manipulation of their internal variables. Experiments with face images support that modularity between groups of channels is achieved to some degree within convolutional layers of vanilla VAE and GAN generators. This helps understand the functional organization of these systems and allows designing meaningful transformations of the generated images without further training.
KS: A Light-Weight Test if a ConvNet Operates Outside of Its Specifications
Apr 11, 2018
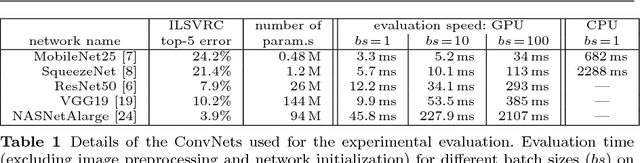
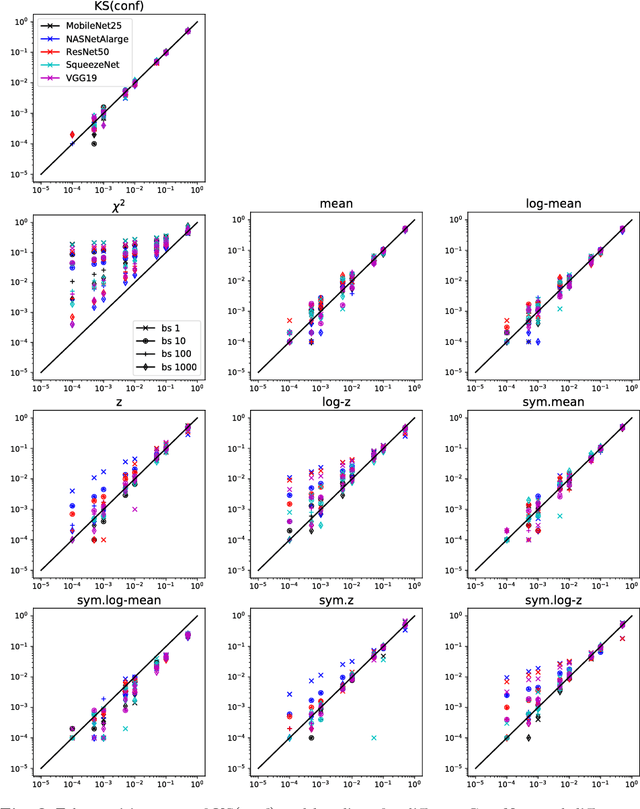
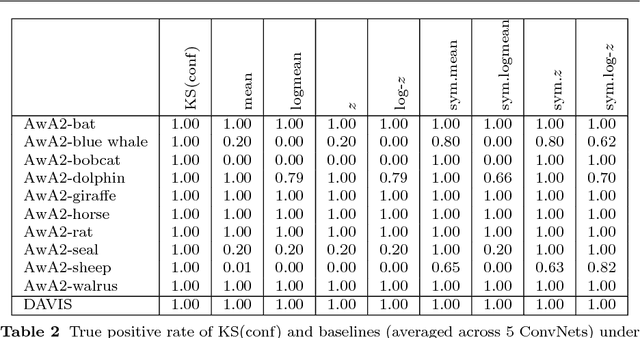
Computer vision systems for automatic image categorization have become accurate and reliable enough that they can run continuously for days or even years as components of real-world commercial applications. A major open problem in this context, however, is quality control. Good classification performance can only be expected if systems run under the specific conditions, in particular data distributions, that they were trained for. Surprisingly, none of the currently used deep network architectures has a built-in functionality that could detect if a network operates on data from a distribution that it was not trained for and potentially trigger a warning to the human users. In this work, we describe KS(conf), a procedure for detecting such outside of the specifications operation. Building on statistical insights, its main step is the applications of a classical Kolmogorov-Smirnov test to the distribution of predicted confidence values. We show by extensive experiments using ImageNet, AwA2 and DAVIS data on a variety of ConvNets architectures that KS(conf) reliably detects out-of-specs situations. It furthermore has a number of properties that make it an excellent candidate for practical deployment: it is easy to implement, adds almost no overhead to the system, works with all networks, including pretrained ones, and requires no a priori knowledge about how the data distribution could change.