 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards efficient feature sharing in MIMO architectures
Paper and Code


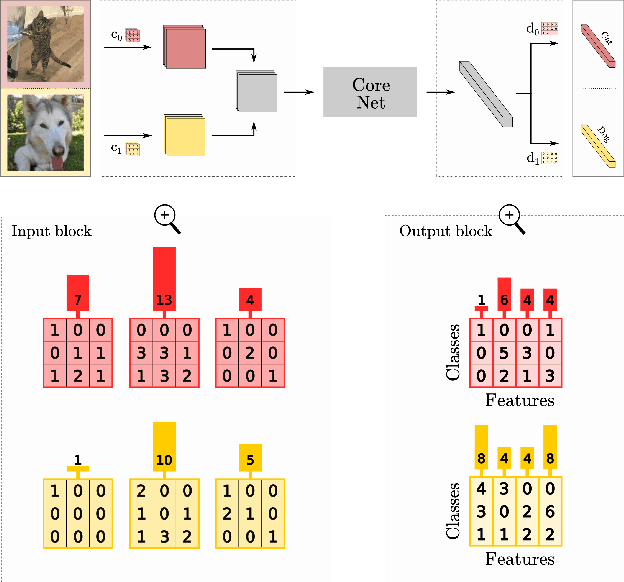
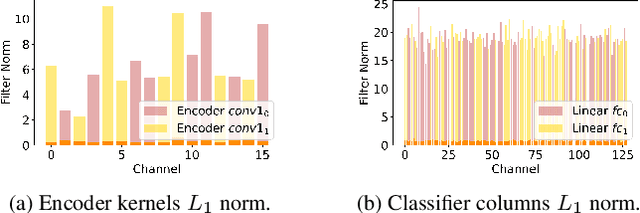
Multi-input multi-output architectures propose to train multiple subnetworks within one base network and then average the subnetwork predictions to benefit from ensembling for free. Despite some relative success, these architectures are wasteful in their use of parameters. Indeed, we highlight in this paper that the learned subnetwork fail to share even generic features which limits their applicability on smaller mobile and AR/VR devices. We posit this behavior stems from an ill-posed part of the multi-input multi-output framework. To solve this issue, we propose a novel unmixing step in MIMO architectures that allows subnetworks to properly share features. Preliminary experiments on CIFAR-100 show our adjustments allow feature sharing and improve model performance for small architectures.