 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactuals uncover the modular structure of deep generative models
Paper and Code
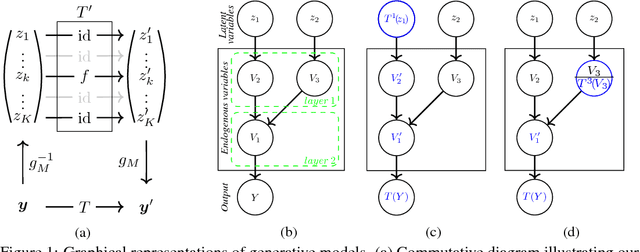

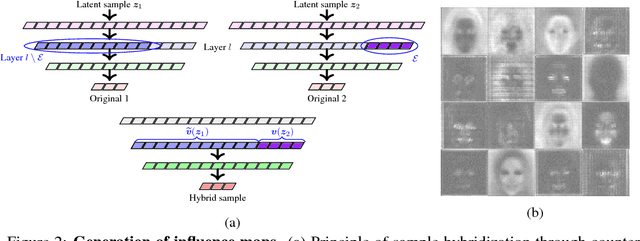

Deep generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are important tools to capture and investigate the properties of complex empirical data. However, the complexity of their inner elements makes their functioning challenging to assess and modify. In this respect, these architectures behave as black box models. In order to better understand the function of such networks, we analyze their modularity based on the counterfactual manipulation of their internal variables. Experiments with face images support that modularity between groups of channels is achieved to some degree within convolutional layers of vanilla VAE and GAN generators. This helps understand the functional organization of these systems and allows designing meaningful transformations of the generated images without further training.