 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotlighting Task-Relevant Features: Object-Centric Representations for Better Generalization in Robotic Manipulation
Jan 29, 2026The generalization capabilities of robotic manipulation policies are heavily influenced by the choice of visual representations. Existing approaches typically rely on representations extracted from pre-trained encoders, using two dominant types of features: global features, which summarize an entire image via a single pooled vector, and dense features, which preserve a patch-wise embedding from the final encoder layer. While widely used, both feature types mix task-relevant and irrelevant information, leading to poor generalization under distribution shifts, such as changes in lighting, textures, or the presence of distractors. In this work, we explore an intermediate structured alternative: Slot-Based Object-Centric Representations (SBOCR), which group dense features into a finite set of object-like entities. This representation permits to naturally reduce the noise provided to the robotic manipulation policy while keeping enough information to efficiently perform the task. We benchmark a range of global and dense representations against intermediate slot-based representations, across a suite of simulated and real-world manipulation tasks ranging from simple to complex. We evaluate their generalization under diverse visual conditions, including changes in lighting, texture, and the presence of distractors. Our findings reveal that SBOCR-based policies outperform dense and global representation-based policies in generalization settings, even without task-specific pretraining. These insights suggest that SBOCR is a promising direction for designing visual systems that generalize effectively in dynamic, real-world robotic environments.
STORM: Slot-based Task-aware Object-centric Representation for robotic Manipulation
Jan 28, 2026Visual foundation models provide strong perceptual features for robotics, but their dense representations lack explicit object-level structure, limiting robustness and contractility in manipulation tasks. We propose STORM (Slot-based Task-aware Object-centric Representation for robotic Manipulation), a lightweight object-centric adaptation module that augments frozen visual foundation models with a small set of semantic-aware slots for robotic manipulation. Rather than retraining large backbones, STORM employs a multi-phase training strategy: object-centric slots are first stabilized through visual--semantic pretraining using language embeddings, then jointly adapted with a downstream manipulation policy. This staged learning prevents degenerate slot formation and preserves semantic consistency while aligning perception with task objectives. Experiments on object discovery benchmarks and simulated manipulation tasks show that STORM improves generalization to visual distractors, and control performance compared to directly using frozen foundation model features or training object-centric representations end-to-end. Our results highlight multi-phase adaptation as an efficient mechanism for transforming generic foundation model features into task-aware object-centric representations for robotic control.
Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent
Feb 15, 2024
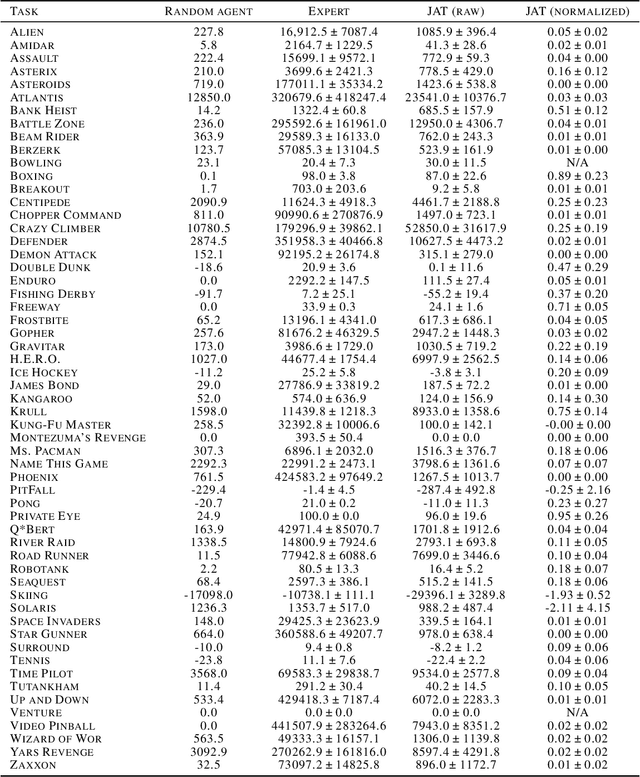


The search for a general model that can operate seamlessly across multiple domains remains a key goal in machine learning research. The prevailing methodology in Reinforcement Learning (RL) typically limits models to a single task within a unimodal framework, a limitation that contrasts with the broader vision of a versatile, multi-domain model. In this paper, we present Jack of All Trades (JAT), a transformer-based model with a unique design optimized for handling sequential decision-making tasks and multimodal data types. The JAT model demonstrates its robust capabilities and versatility by achieving strong performance on very different RL benchmarks, along with promising results on Computer Vision (CV) and Natural Language Processing (NLP) tasks, all using a single set of weights. The JAT model marks a significant step towards more general, cross-domain AI model design, and notably, it is the first model of its kind to be fully open-sourced (see https://huggingface.co/jat-project/jat), including a pioneering general-purpose dataset.
Look Beyond Bias with Entropic Adversarial Data Augmentation
Jan 10, 2023
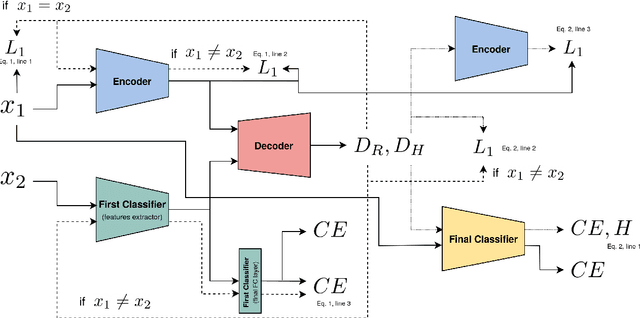

Deep neural networks do not discriminate between spurious and causal patterns, and will only learn the most predictive ones while ignoring the others. This shortcut learning behaviour is detrimental to a network's ability to generalize to an unknown test-time distribution in which the spurious correlations do not hold anymore. Debiasing methods were developed to make networks robust to such spurious biases but require to know in advance if a dataset is biased and make heavy use of minority counterexamples that do not display the majority bias of their class. In this paper, we argue that such samples should not be necessarily needed because the ''hidden'' causal information is often also contained in biased images. To study this idea, we propose 3 publicly released synthetic classification benchmarks, exhibiting predictive classification shortcuts, each of a different and challenging nature, without any minority samples acting as counterexamples. First, we investigate the effectiveness of several state-of-the-art strategies on our benchmarks and show that they do not yield satisfying results on them. Then, we propose an architecture able to succeed on our benchmarks, despite their unusual properties, using an entropic adversarial data augmentation training scheme. An encoder-decoder architecture is tasked to produce images that are not recognized by a classifier, by maximizing the conditional entropy of its outputs, and keep as much as possible of the initial content. A precise control of the information destroyed, via a disentangling process, enables us to remove the shortcut and leave everything else intact. Furthermore, results competitive with the state-of-the-art on the BAR dataset ensure the applicability of our method in real-life situations.
Learning Less Generalizable Patterns with an Asymmetrically Trained Double Classifier for Better Test-Time Adaptation
Oct 17, 2022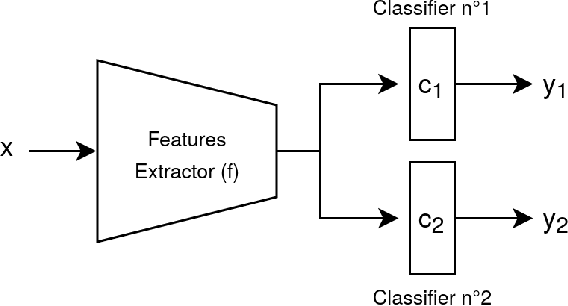
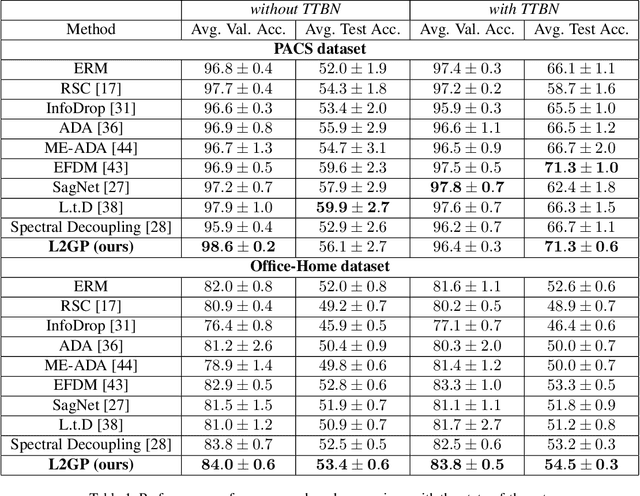
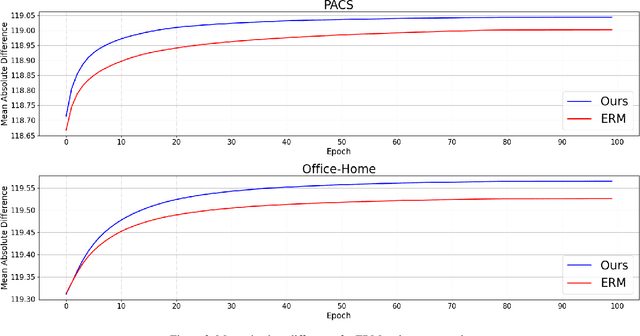
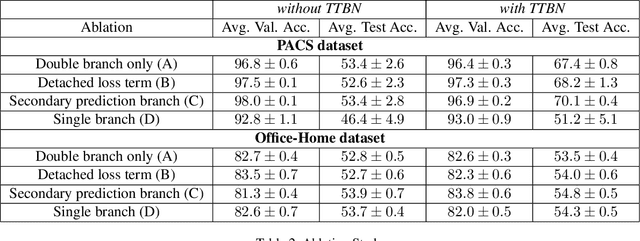
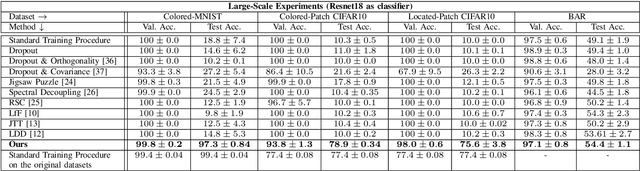
Deep neural networks often fail to generalize outside of their training distribution, in particular when only a single data domain is available during training. While test-time adaptation has yielded encouraging results in this setting, we argue that, to reach further improvements, these approaches should be combined with training procedure modifications aiming to learn a more diverse set of patterns. Indeed, test-time adaptation methods usually have to rely on a limited representation because of the shortcut learning phenomenon: only a subset of the available predictive patterns is learned with standard training. In this paper, we first show that the combined use of existing training-time strategies, and test-time batch normalization, a simple adaptation method, does not always improve upon the test-time adaptation alone on the PACS benchmark. Furthermore, experiments on Office-Home show that very few training-time methods improve upon standard training, with or without test-time batch normalization. We therefore propose a novel approach using a pair of classifiers and a shortcut patterns avoidance loss that mitigates the shortcut learning behavior by reducing the generalization ability of the secondary classifier, using the additional shortcut patterns avoidance loss that encourages the learning of samples specific patterns. The primary classifier is trained normally, resulting in the learning of both the natural and the more complex, less generalizable, features. Our experiments show that our method improves upon the state-of-the-art results on both benchmarks and benefits the most to test-time batch normalization.
Cell-Free Latent Go-Explore
Aug 31, 2022
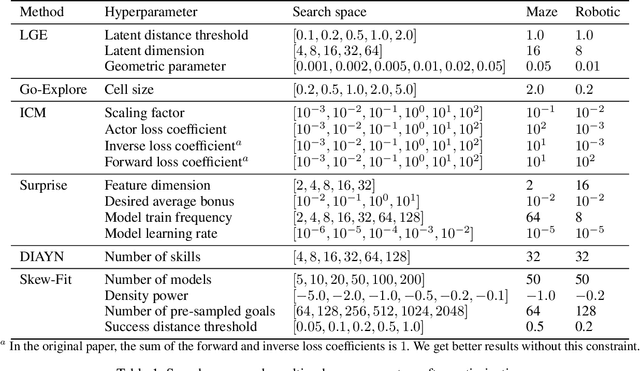
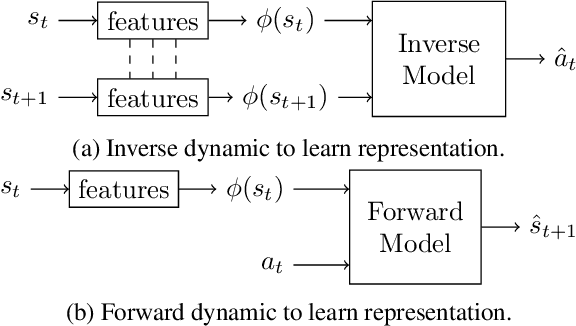

In this paper, we introduce Latent Go-Explore (LGE), a simple and general approach based on the Go-Explore paradigm for exploration in reinforcement learning (RL). Go-Explore was initially introduced with a strong domain knowledge constraint for partitioning the state space into cells. However, in most real-world scenarios, drawing domain knowledge from raw observations is complex and tedious. If the cell partitioning is not informative enough, Go-Explore can completely fail to explore the environment. We argue that the Go-Explore approach can be generalized to any environment without domain knowledge and without cells by exploiting a learned latent representation. Thus, we show that LGE can be flexibly combined with any strategy for learning a latent representation. We show that LGE, although simpler than Go-Explore, is more robust and outperforms all state-of-the-art algorithms in terms of pure exploration on multiple hard-exploration environments. The LGE implementation is available as open-source at https://github.com/qgallouedec/lge.
Multi-Goal Reinforcement Learning environments for simulated Franka Emika Panda robot
Jun 25, 2021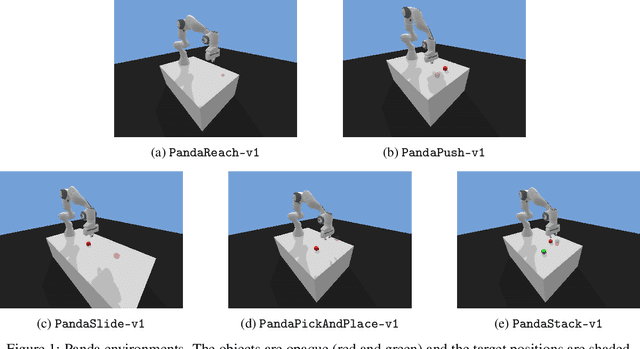

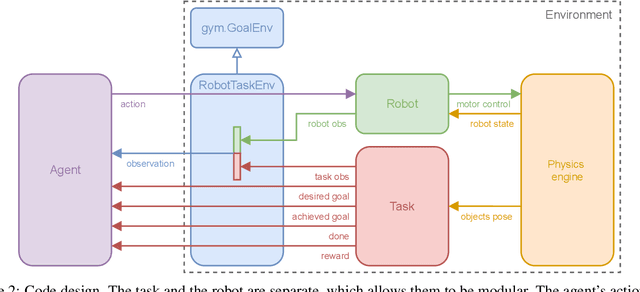
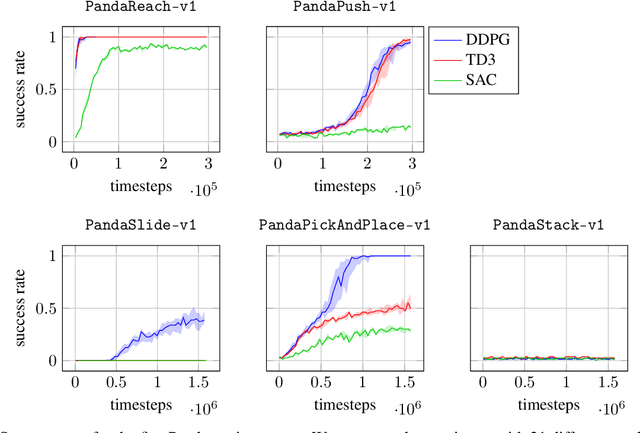
This technical report presents panda-gym, a set Reinforcement Learning (RL) environments for the Franka Emika Panda robot integrated with OpenAI Gym. Five tasks are included: reach, push, slide, pick & place and stack. They all follow a Multi-Goal RL framework, allowing to use goal-oriented RL algorithms. To foster open-research, we chose to use the open-source physics engine PyBullet. The implementation chosen for this package allows to define very easily new tasks or new robots. This report also presents a baseline of results obtained with state-of-the-art model-free off-policy algorithms. panda-gym is open-source at https://github.com/qgallouedec/panda-gym.
Encouraging Intra-Class Diversity Through a Reverse Contrastive Loss for Better Single-Source Domain Generalization
Jun 15, 2021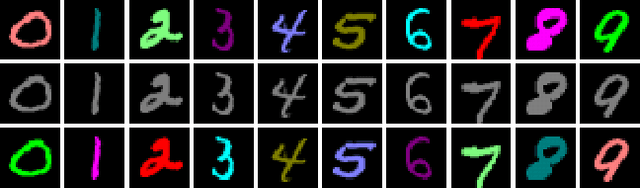
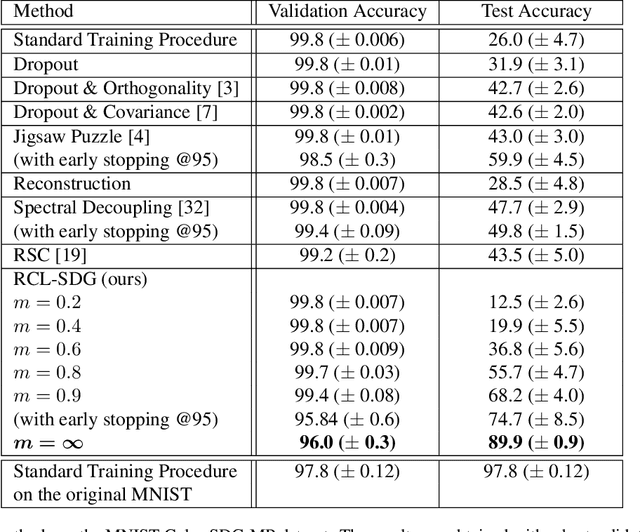
Traditional deep learning algorithms often fail to generalize when they are tested outside of the domain of training data. Because data distributions can change dynamically in real-life applications once a learned model is deployed, in this paper we are interested in single-source domain generalization (SDG) which aims to develop deep learning algorithms able to generalize from a single training domain where no information about the test domain is available at training time. Firstly, we design two simple MNISTbased SDG benchmarks, namely MNIST Color SDG-MP and MNIST Color SDG-UP, which highlight the two different fundamental SDG issues of increasing difficulties: 1) a class-correlated pattern in the training domain is missing (SDG-MP), or 2) uncorrelated with the class (SDG-UP), in the testing data domain. This is in sharp contrast with the current domain generalization (DG) benchmarks which mix up different correlation and variation factors and thereby make hard to disentangle success or failure factors when benchmarking DG algorithms. We further evaluate several state-of-the-art SDG algorithms through our simple benchmark, namely MNIST Color SDG-MP, and show that the issue SDG-MP is largely unsolved despite of a decade of efforts in developing DG algorithms. Finally, we also propose a partially reversed contrastive loss to encourage intra-class diversity and find less strongly correlated patterns, to deal with SDG-MP and show that the proposed approach is very effective on our MNIST Color SDG-MP benchmark.
Optimizing Correlated Graspability Score and Grasp Regression for Better Grasp Prediction
Feb 03, 2020
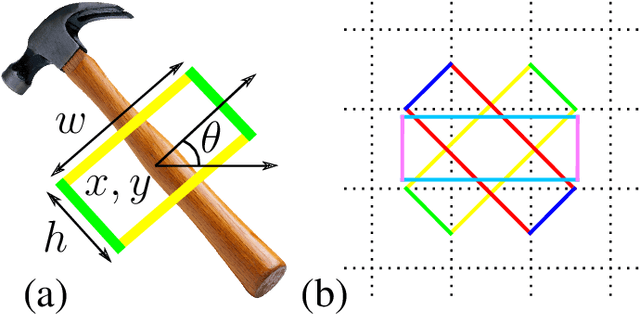
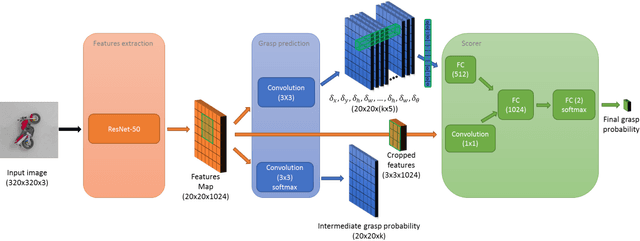
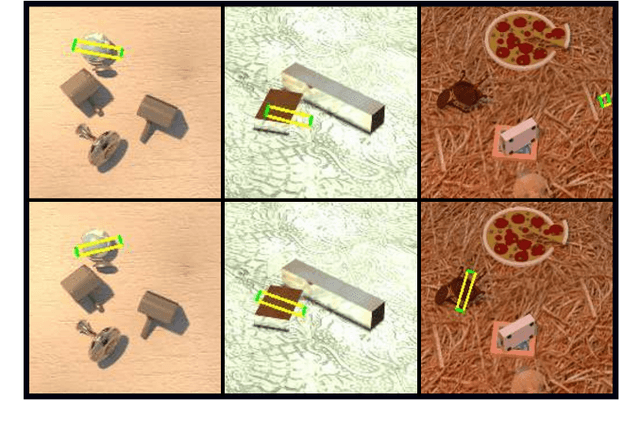
Grasping objects is one of the most important abilities to master for a robot in order to interact with its environment. Current state-of-the-art methods rely on deep neural networks trained to predict a graspability score jointly but separately from regression of an offset of grasp reference parameters, although the predicted offset could decrease the graspability score. In this paper, we extend a state-of-the-art neural network with a scorer which evaluates the graspability of a given position and introduce a novel loss function which correlates regression of grasp parameters with graspability score. We show that this novel architecture improves the performance from 81.95% for a state-of-the-art grasp detection network to 85.74% on Jacquard dataset. Because real-life applications generally feature scenes of multiple objects laid on a variable decor, we also introduce Jacquard+, a test-only extension of Jacquard dataset. Its role is to complete the traditional real robot evaluation by benchmarking the adaptability of a learned grasp prediction model on a different data distribution than the training one while remaining in totally reproducible conditions. Using this novel benchmark and evaluated through the Simulated Grasp Trial criterion, our proposed model outperforms a state-of-the-art one by 7 points.
Bicameral Structuring and Synthetic Imagery for Jointly Predicting Instance Boundaries and Nearby Occlusions from a Single Image
Jun 18, 2019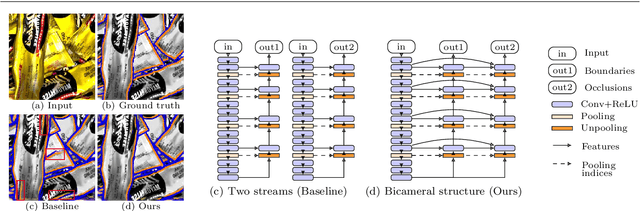



Oriented boundary detection is a challenging task aimed at both delineating category-agnostic object instances and inferring their spatial layout from a single RGB image. State-of-the-art deep convolutional networks for this task rely on two independent streams that predict boundaries and occlusions respectively, although both require similar local and global cues, and occlusions cause boundaries. We therefore propose a fully convolutional bicameral structuring, composed of two cascaded decoders sharing one deep encoder, linked altogether by skip connections to combine local and global features, for jointly predicting instance boundaries and their unoccluded side. Furthermore, state-of-the-art datasets contain real images with few instances and occlusions mostly due to objects occluding the background, thereby missing meaningful occlusions between instances. For evaluating the missing scenario of dense piles of objects as well, we introduce synthetic data (Mikado), which extensibly contains more instances and inter-instance occlusions per image than the PASCAL Instance Occlusion Dataset (PIOD), the COCO Amodal dataset (COCOA), and the Densely Segmented Supermarket Amodal dataset (D2SA). We show that the proposed network design outperforms the two-stream baseline and alternative archiectures for oriented boundary detection on both PIOD and Mikado, and the amodal segmentation approach on COCOA as well. Our experiments on D2SA also show that Mikado is plausible in the sense that it enables the learning of performance-enhancing representations transferable to real data, while drastically reducing the need of hand-made annotations for finetuning.