 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBicameral Structuring and Synthetic Imagery for Jointly Predicting Instance Boundaries and Nearby Occlusions from a Single Image
Jun 18, 2019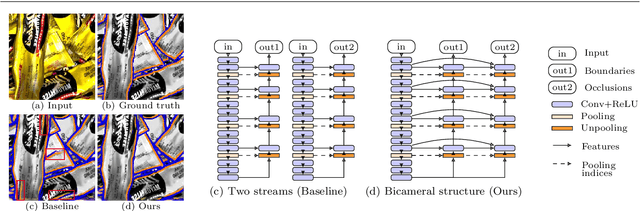



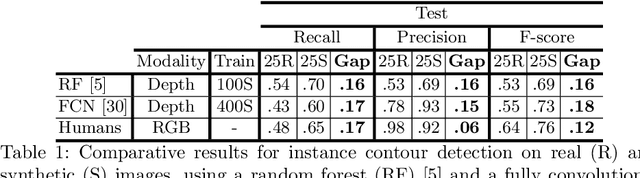
Oriented boundary detection is a challenging task aimed at both delineating category-agnostic object instances and inferring their spatial layout from a single RGB image. State-of-the-art deep convolutional networks for this task rely on two independent streams that predict boundaries and occlusions respectively, although both require similar local and global cues, and occlusions cause boundaries. We therefore propose a fully convolutional bicameral structuring, composed of two cascaded decoders sharing one deep encoder, linked altogether by skip connections to combine local and global features, for jointly predicting instance boundaries and their unoccluded side. Furthermore, state-of-the-art datasets contain real images with few instances and occlusions mostly due to objects occluding the background, thereby missing meaningful occlusions between instances. For evaluating the missing scenario of dense piles of objects as well, we introduce synthetic data (Mikado), which extensibly contains more instances and inter-instance occlusions per image than the PASCAL Instance Occlusion Dataset (PIOD), the COCO Amodal dataset (COCOA), and the Densely Segmented Supermarket Amodal dataset (D2SA). We show that the proposed network design outperforms the two-stream baseline and alternative archiectures for oriented boundary detection on both PIOD and Mikado, and the amodal segmentation approach on COCOA as well. Our experiments on D2SA also show that Mikado is plausible in the sense that it enables the learning of performance-enhancing representations transferable to real data, while drastically reducing the need of hand-made annotations for finetuning.
Object segmentation in depth maps with one user click and a synthetically trained fully convolutional network
Sep 24, 2018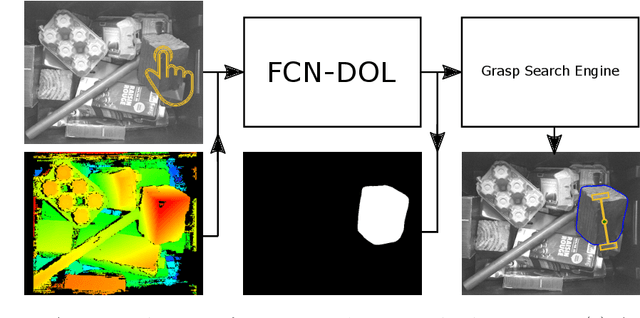


With more and more household objects built on planned obsolescence and consumed by a fast-growing population, hazardous waste recycling has become a critical challenge. Given the large variability of household waste, current recycling platforms mostly rely on human operators to analyze the scene, typically composed of many object instances piled up in bulk. Helping them by robotizing the unitary extraction is a key challenge to speed up this tedious process. Whereas supervised deep learning has proven very efficient for such object-level scene understanding, e.g., generic object detection and segmentation in everyday scenes, it however requires large sets of per-pixel labeled images, that are hardly available for numerous application contexts, including industrial robotics. We thus propose a step towards a practical interactive application for generating an object-oriented robotic grasp, requiring as inputs only one depth map of the scene and one user click on the next object to extract. More precisely, we address in this paper the middle issue of object seg-mentation in top views of piles of bulk objects given a pixel location, namely seed, provided interactively by a human operator. We propose a twofold framework for generating edge-driven instance segments. First, we repurpose a state-of-the-art fully convolutional object contour detector for seed-based instance segmentation by introducing the notion of edge-mask duality with a novel patch-free and contour-oriented loss function. Second, we train one model using only synthetic scenes, instead of manually labeled training data. Our experimental results show that considering edge-mask duality for training an encoder-decoder network, as we suggest, outperforms a state-of-the-art patch-based network in the present application context.