 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability Metrics for Object Detection
Jun 27, 2023Transfer learning aims to make the most of existing pre-trained models to achieve better performance on a new task in limited data scenarios. However, it is unclear which models will perform best on which task, and it is prohibitively expensive to try all possible combinations. If transferability estimation offers a computation-efficient approach to evaluate the generalisation ability of models, prior works focused exclusively on classification settings. To overcome this limitation, we extend transferability metrics to object detection. We design a simple method to extract local features corresponding to each object within an image using ROI-Align. We also introduce TLogME, a transferability metric taking into account the coordinates regression task. In our experiments, we compare TLogME to state-of-the-art metrics in the estimation of transfer performance of the Faster-RCNN object detector. We evaluate all metrics on source and target selection tasks, for real and synthetic datasets, and with different backbone architectures. We show that, over different tasks, TLogME using the local extraction method provides a robust correlation with transfer performance and outperforms other transferability metrics on local and global level features.
Towards Clear Expectations for Uncertainty Estimation
Jul 27, 2022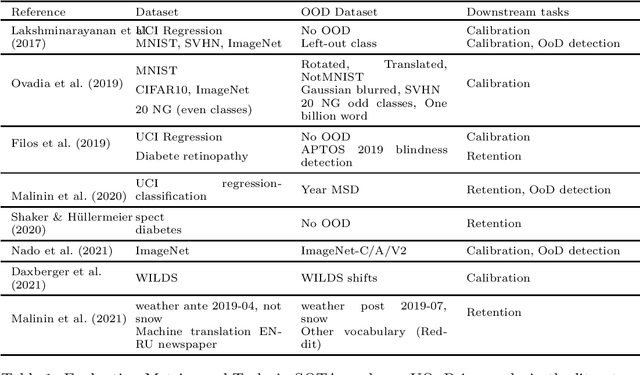
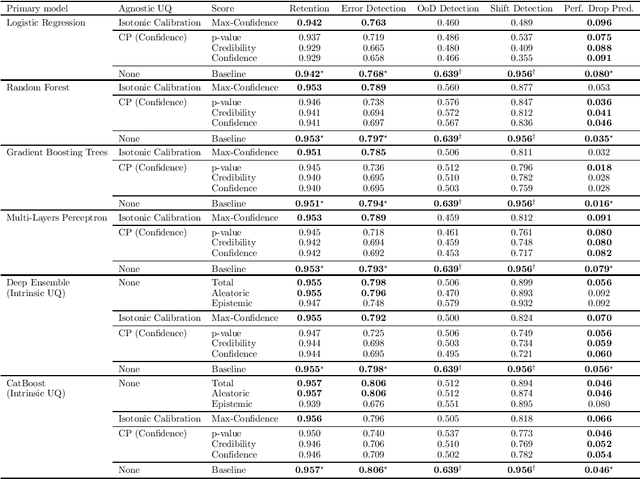
If Uncertainty Quantification (UQ) is crucial to achieve trustworthy Machine Learning (ML), most UQ methods suffer from disparate and inconsistent evaluation protocols. We claim this inconsistency results from the unclear requirements the community expects from UQ. This opinion paper offers a new perspective by specifying those requirements through five downstream tasks where we expect uncertainty scores to have substantial predictive power. We design these downstream tasks carefully to reflect real-life usage of ML models. On an example benchmark of 7 classification datasets, we did not observe statistical superiority of state-of-the-art intrinsic UQ methods against simple baselines. We believe that our findings question the very rationale of why we quantify uncertainty and call for a standardized protocol for UQ evaluation based on metrics proven to be relevant for the ML practitioner.
Performance Prediction Under Dataset Shift
Jun 21, 2022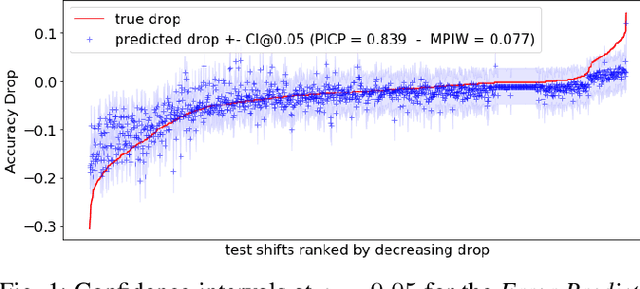
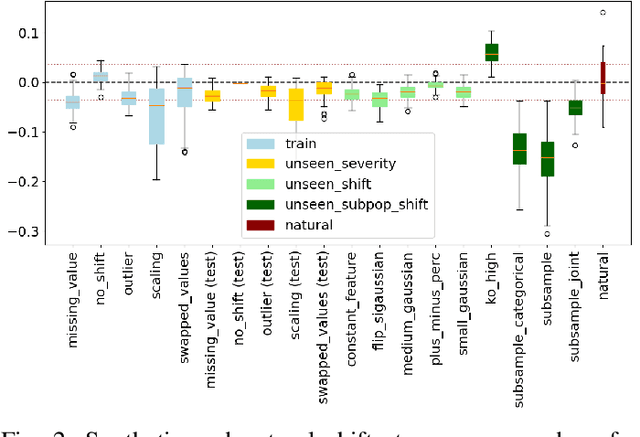
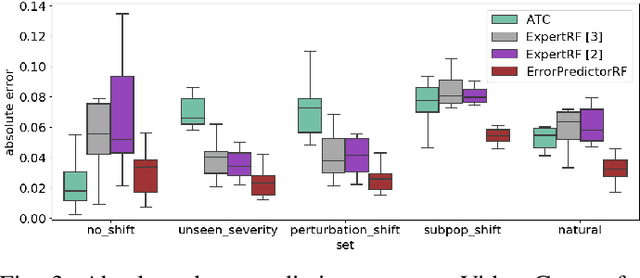
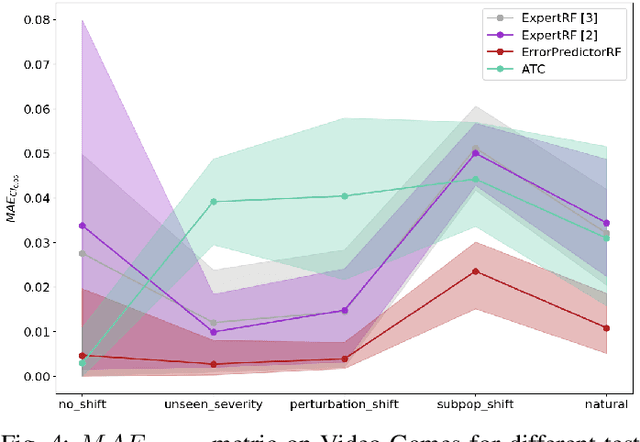
ML models deployed in production often have to face unknown domain changes, fundamentally different from their training settings. Performance prediction models carry out the crucial task of measuring the impact of these changes on model performance. We study the generalization capabilities of various performance prediction models to new domains by learning on generated synthetic perturbations. Empirical validation on a benchmark of ten tabular datasets shows that models based upon state-of-the-art shift detection metrics are not expressive enough to generalize to unseen domains, while Error Predictors bring a consistent improvement in performance prediction under shift. We additionally propose a natural and effortless uncertainty estimation of the predicted accuracy that ensures reliable use of performance predictors. Our implementation is available at https: //github.com/dataiku-research/performance_prediction_under_shift.
Ensembling Shift Detectors: an Extensive Empirical Evaluation
Jun 28, 2021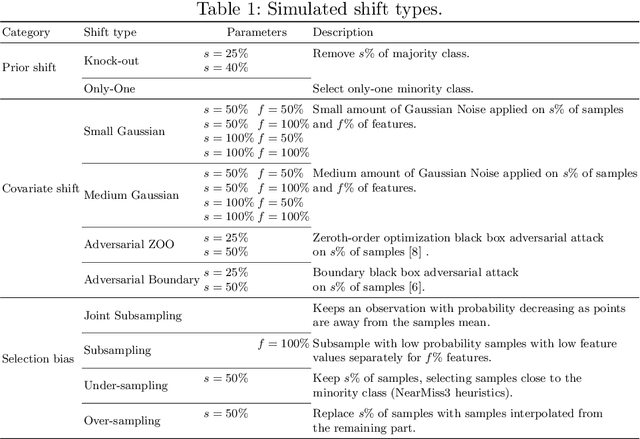
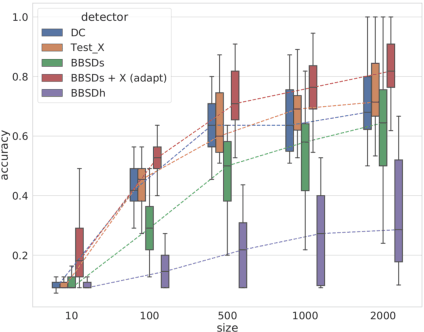
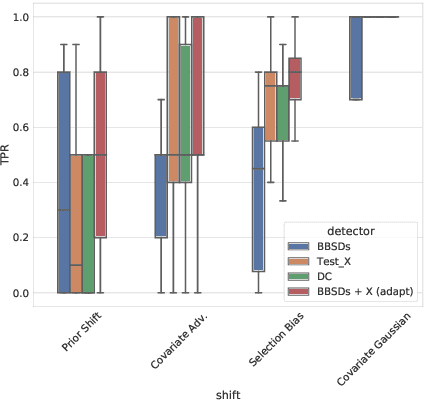
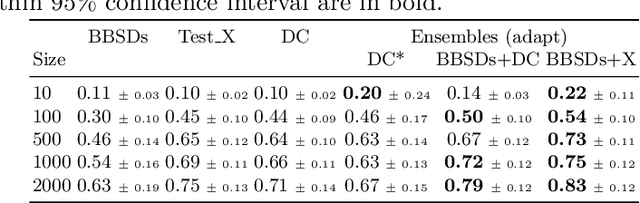
The term dataset shift refers to the situation where the data used to train a machine learning model is different from where the model operates. While several types of shifts naturally occur, existing shift detectors are usually designed to address only a specific type of shift. We propose a simple yet powerful technique to ensemble complementary shift detectors, while tuning the significance level of each detector's statistical test to the dataset. This enables a more robust shift detection, capable of addressing all different types of shift, which is essential in real-life settings where the precise shift type is often unknown. This approach is validated by a large-scale statistically sound benchmark study over various synthetic shifts applied to real-world structured datasets.
Who wrote this book? A challenge for e-commerce
Apr 19, 2019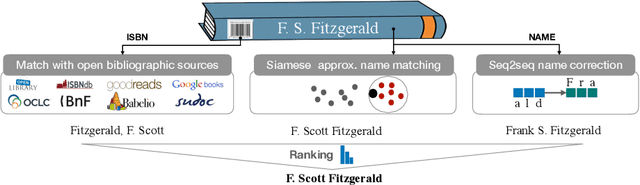

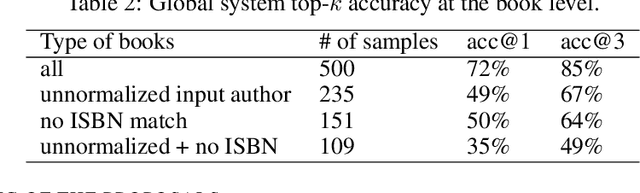
Modern e-commerce catalogs contain millions of references, associated with textual and visual information that is of paramount importance for the products to be found via search or browsing. Of particular significance is the book category, where the author name(s) field poses a significant challenge. Indeed, books written by a given author (such as F. Scott Fitzgerald) might be listed with different authors' names in a catalog due to abbreviations and spelling variants and mistakes, among others. To solve this problem at scale, we design a composite system involving open data sources for books as well as machine learning components leveraging deep learning-based techniques for natural language processing. In particular, we use Siamese neural networks for an approximate match with known author names, and direct correction of the provided author's name using sequence-to-sequence learning with neural networks. We evaluate this approach on product data from the e-commerce website Rakuten France, and find that the top proposal of the system is the normalized author name with 72% accuracy.
Robustness of Rotation-Equivariant Networks to Adversarial Perturbations
May 17, 2018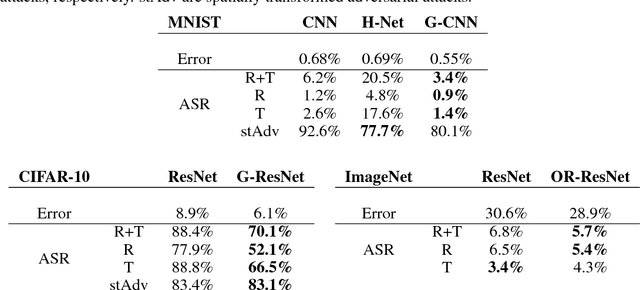
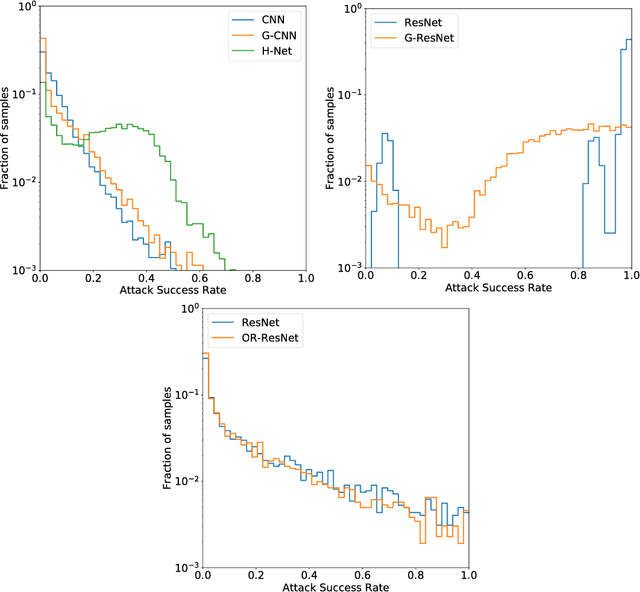
Deep neural networks have been shown to be vulnerable to adversarial examples: very small perturbations of the input having a dramatic impact on the predictions. A wealth of adversarial attacks and distance metrics to quantify the similarity between natural and adversarial images have been proposed, recently enlarging the scope of adversarial examples with geometric transformations beyond pixel-wise attacks. In this context, we investigate the robustness to adversarial attacks of new Convolutional Neural Network architectures providing equivariance to rotations. We found that rotation-equivariant networks are significantly less vulnerable to geometric-based attacks than regular networks on the MNIST, CIFAR-10, and ImageNet datasets.