 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Clear Expectations for Uncertainty Estimation
Paper and Code
Jul 27, 2022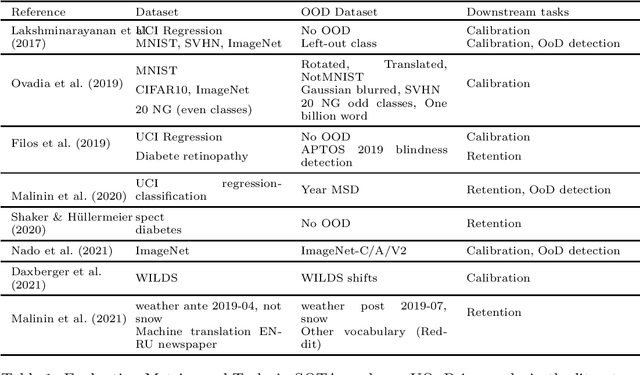
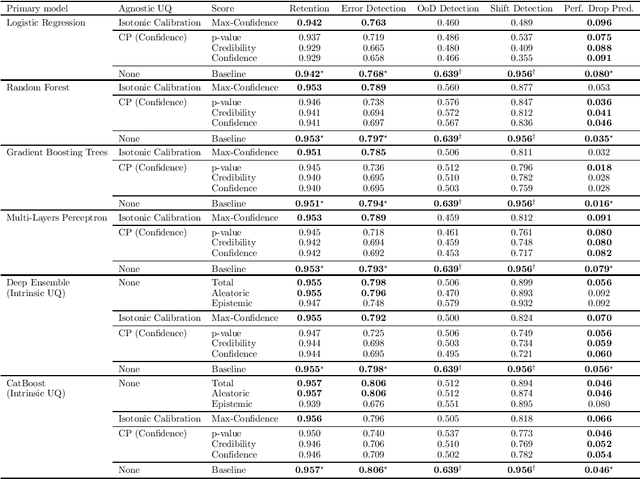
If Uncertainty Quantification (UQ) is crucial to achieve trustworthy Machine Learning (ML), most UQ methods suffer from disparate and inconsistent evaluation protocols. We claim this inconsistency results from the unclear requirements the community expects from UQ. This opinion paper offers a new perspective by specifying those requirements through five downstream tasks where we expect uncertainty scores to have substantial predictive power. We design these downstream tasks carefully to reflect real-life usage of ML models. On an example benchmark of 7 classification datasets, we did not observe statistical superiority of state-of-the-art intrinsic UQ methods against simple baselines. We believe that our findings question the very rationale of why we quantify uncertainty and call for a standardized protocol for UQ evaluation based on metrics proven to be relevant for the ML practitioner.