 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
Transferability Metrics for Object Detection
Jun 27, 2023Transfer learning aims to make the most of existing pre-trained models to achieve better performance on a new task in limited data scenarios. However, it is unclear which models will perform best on which task, and it is prohibitively expensive to try all possible combinations. If transferability estimation offers a computation-efficient approach to evaluate the generalisation ability of models, prior works focused exclusively on classification settings. To overcome this limitation, we extend transferability metrics to object detection. We design a simple method to extract local features corresponding to each object within an image using ROI-Align. We also introduce TLogME, a transferability metric taking into account the coordinates regression task. In our experiments, we compare TLogME to state-of-the-art metrics in the estimation of transfer performance of the Faster-RCNN object detector. We evaluate all metrics on source and target selection tasks, for real and synthetic datasets, and with different backbone architectures. We show that, over different tasks, TLogME using the local extraction method provides a robust correlation with transfer performance and outperforms other transferability metrics on local and global level features.
Towards Clear Expectations for Uncertainty Estimation
Jul 27, 2022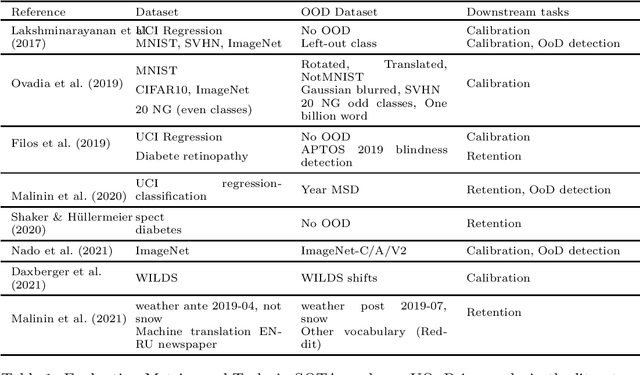
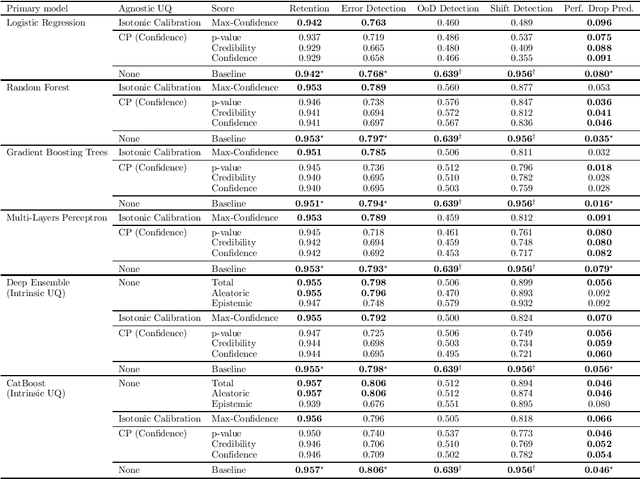
If Uncertainty Quantification (UQ) is crucial to achieve trustworthy Machine Learning (ML), most UQ methods suffer from disparate and inconsistent evaluation protocols. We claim this inconsistency results from the unclear requirements the community expects from UQ. This opinion paper offers a new perspective by specifying those requirements through five downstream tasks where we expect uncertainty scores to have substantial predictive power. We design these downstream tasks carefully to reflect real-life usage of ML models. On an example benchmark of 7 classification datasets, we did not observe statistical superiority of state-of-the-art intrinsic UQ methods against simple baselines. We believe that our findings question the very rationale of why we quantify uncertainty and call for a standardized protocol for UQ evaluation based on metrics proven to be relevant for the ML practitioner.
Performance Prediction Under Dataset Shift
Jun 21, 2022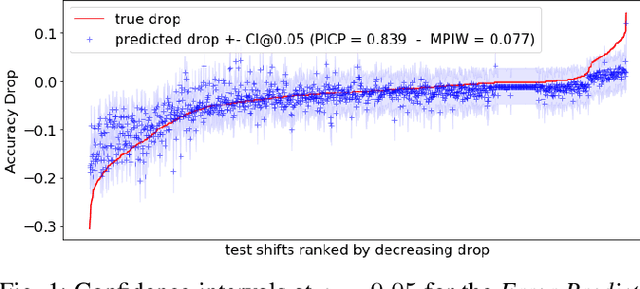
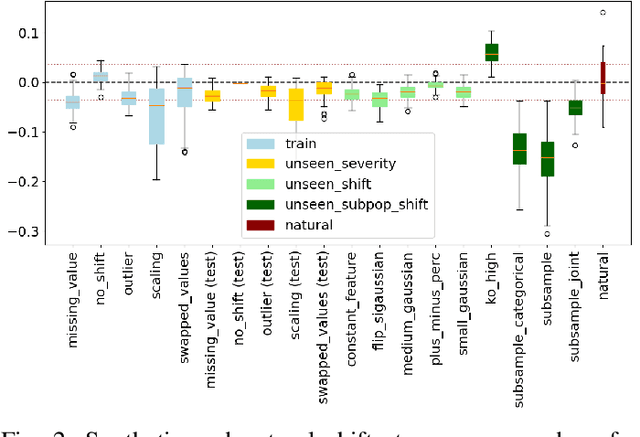
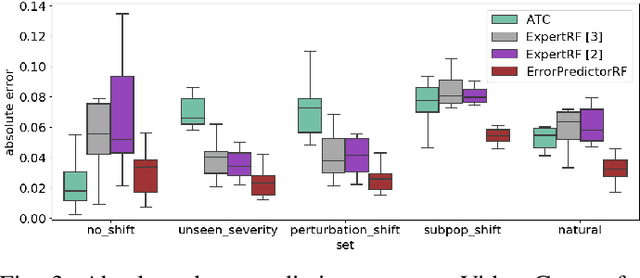
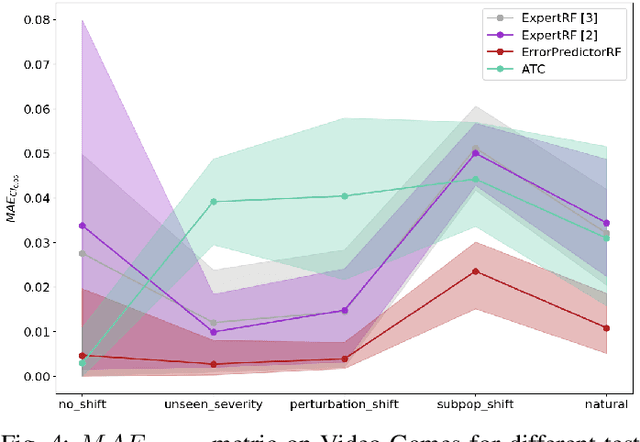
ML models deployed in production often have to face unknown domain changes, fundamentally different from their training settings. Performance prediction models carry out the crucial task of measuring the impact of these changes on model performance. We study the generalization capabilities of various performance prediction models to new domains by learning on generated synthetic perturbations. Empirical validation on a benchmark of ten tabular datasets shows that models based upon state-of-the-art shift detection metrics are not expressive enough to generalize to unseen domains, while Error Predictors bring a consistent improvement in performance prediction under shift. We additionally propose a natural and effortless uncertainty estimation of the predicted accuracy that ensures reliable use of performance predictors. Our implementation is available at https: //github.com/dataiku-research/performance_prediction_under_shift.
Sample Noise Impact on Active Learning
Sep 03, 2021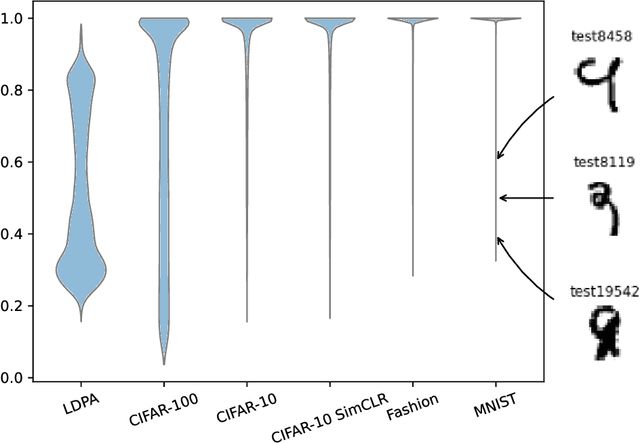
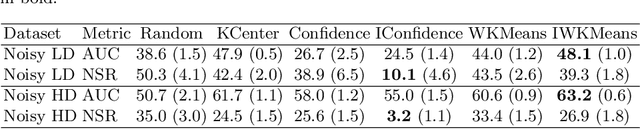
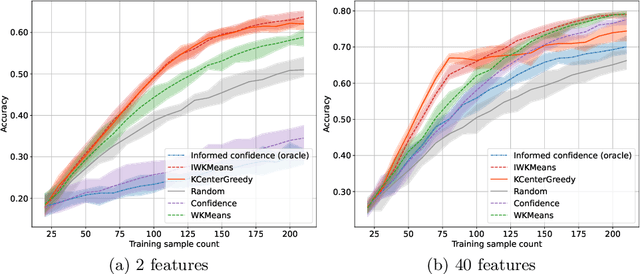
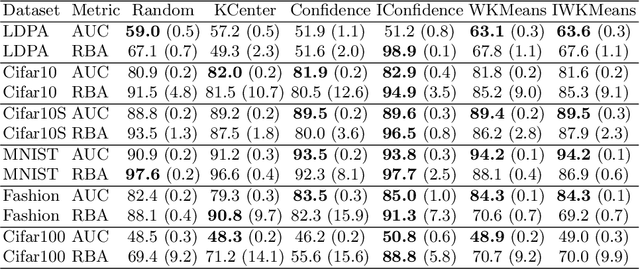
This work explores the effect of noisy sample selection in active learning strategies. We show on both synthetic problems and real-life use-cases that knowledge of the sample noise can significantly improve the performance of active learning strategies. Building on prior work, we propose a robust sampler, Incremental Weighted K-Means that brings significant improvement on the synthetic tasks but only a marginal uplift on real-life ones. We hope that the questions raised in this paper are of interest to the community and could open new paths for active learning research.
* 9 pages, 3 figure, for the code, see https://github.com/dataiku-research/paper_ial_2021
Ensembling Shift Detectors: an Extensive Empirical Evaluation
Jun 28, 2021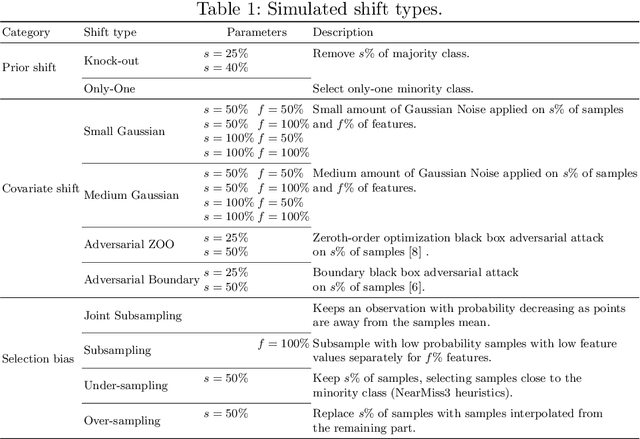
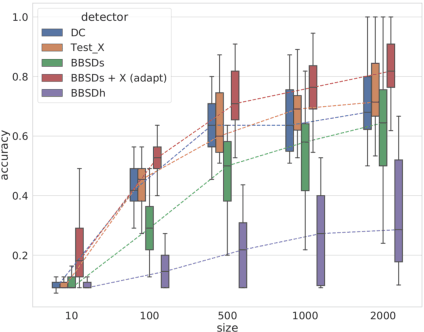
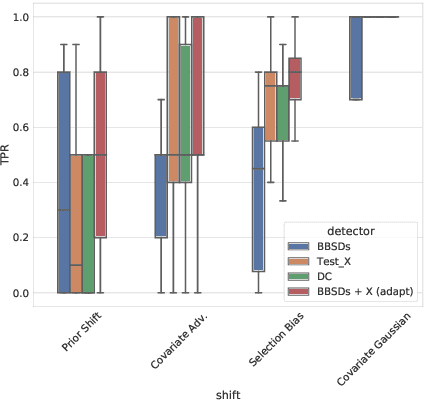
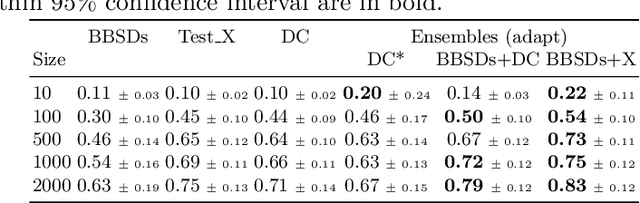
The term dataset shift refers to the situation where the data used to train a machine learning model is different from where the model operates. While several types of shifts naturally occur, existing shift detectors are usually designed to address only a specific type of shift. We propose a simple yet powerful technique to ensemble complementary shift detectors, while tuning the significance level of each detector's statistical test to the dataset. This enables a more robust shift detection, capable of addressing all different types of shift, which is essential in real-life settings where the precise shift type is often unknown. This approach is validated by a large-scale statistically sound benchmark study over various synthetic shifts applied to real-world structured datasets.
Rebuilding Trust in Active Learning with Actionable Metrics
Dec 18, 2020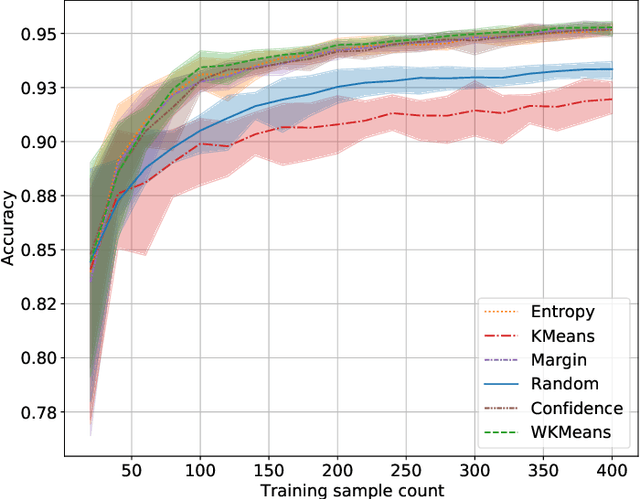
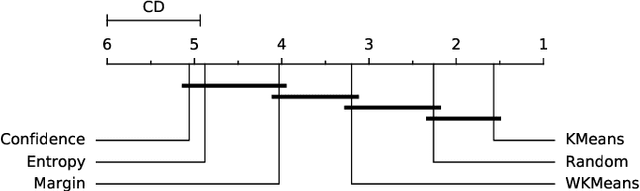
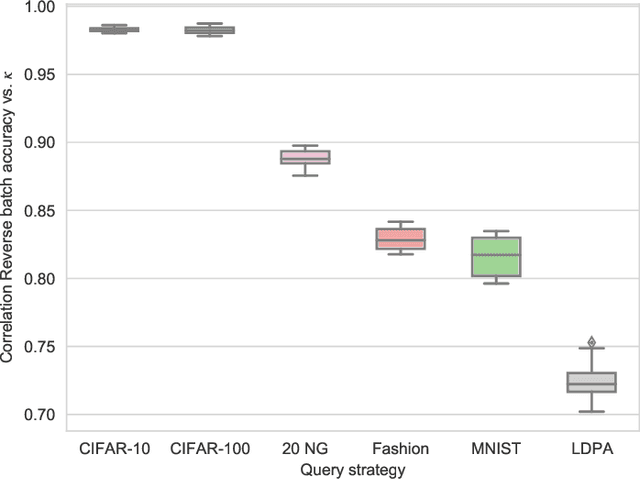
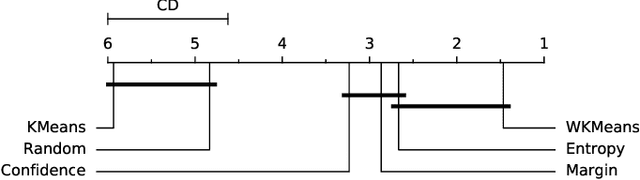
Active Learning (AL) is an active domain of research, but is seldom used in the industry despite the pressing needs. This is in part due to a misalignment of objectives, while research strives at getting the best results on selected datasets, the industry wants guarantees that Active Learning will perform consistently and at least better than random labeling. The very one-off nature of Active Learning makes it crucial to understand how strategy selection can be carried out and what drives poor performance (lack of exploration, selection of samples that are too hard to classify, ...). To help rebuild trust of industrial practitioners in Active Learning, we present various actionable metrics. Through extensive experiments on reference datasets such as CIFAR100, Fashion-MNIST, and 20Newsgroups, we show that those metrics brings interpretability to AL strategies that can be leveraged by the practitioner.
* 16 pages, 38 figures