 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Learning for Textual Few-Shot Classification in API-based Embedding Models
Oct 21, 2023



Proprietary and closed APIs are becoming increasingly common to process natural language, and are impacting the practical applications of natural language processing, including few-shot classification. Few-shot classification involves training a model to perform a new classification task with a handful of labeled data. This paper presents three contributions. First, we introduce a scenario where the embedding of a pre-trained model is served through a gated API with compute-cost and data-privacy constraints. Second, we propose a transductive inference, a learning paradigm that has been overlooked by the NLP community. Transductive inference, unlike traditional inductive learning, leverages the statistics of unlabeled data. We also introduce a new parameter-free transductive regularizer based on the Fisher-Rao loss, which can be used on top of the gated API embeddings. This method fully utilizes unlabeled data, does not share any label with the third-party API provider and could serve as a baseline for future research. Third, we propose an improved experimental setting and compile a benchmark of eight datasets involving multiclass classification in four different languages, with up to 151 classes. We evaluate our methods using eight backbone models, along with an episodic evaluation over 1,000 episodes, which demonstrate the superiority of transductive inference over the standard inductive setting.
Model-Agnostic Few-Shot Open-Set Recognition
Jun 18, 2022

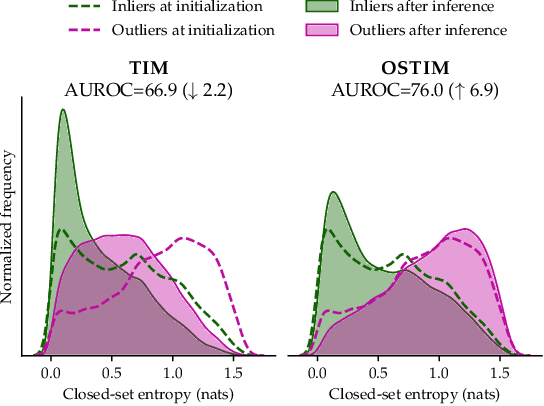
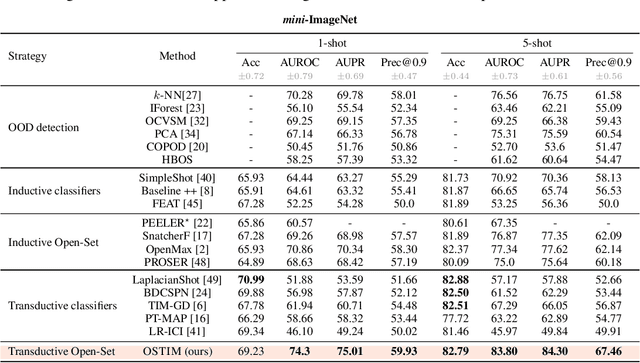
We tackle the Few-Shot Open-Set Recognition (FSOSR) problem, i.e. classifying instances among a set of classes for which we only have few labeled samples, while simultaneously detecting instances that do not belong to any known class. Departing from existing literature, we focus on developing model-agnostic inference methods that can be plugged into any existing model, regardless of its architecture or its training procedure. Through evaluating the embedding's quality of a variety of models, we quantify the intrinsic difficulty of model-agnostic FSOSR. Furthermore, a fair empirical evaluation suggests that the naive combination of a kNN detector and a prototypical classifier ranks before specialized or complex methods in the inductive setting of FSOSR. These observations motivated us to resort to transduction, as a popular and practical relaxation of standard few-shot learning problems. We introduce an Open Set Transductive Information Maximization method OSTIM, which hallucinates an outlier prototype while maximizing the mutual information between extracted features and assignments. Through extensive experiments spanning 5 datasets, we show that OSTIM surpasses both inductive and existing transductive methods in detecting open-set instances while competing with the strongest transductive methods in classifying closed-set instances. We further show that OSTIM's model agnosticity allows it to successfully leverage the strong expressive abilities of the latest architectures and training strategies without any hyperparameter modification, a promising sign that architectural advances to come will continue to positively impact OSTIM's performances.
Few-Shot Image Classification Benchmarks are Too Far From Reality: Build Back Better with Semantic Task Sampling
May 10, 2022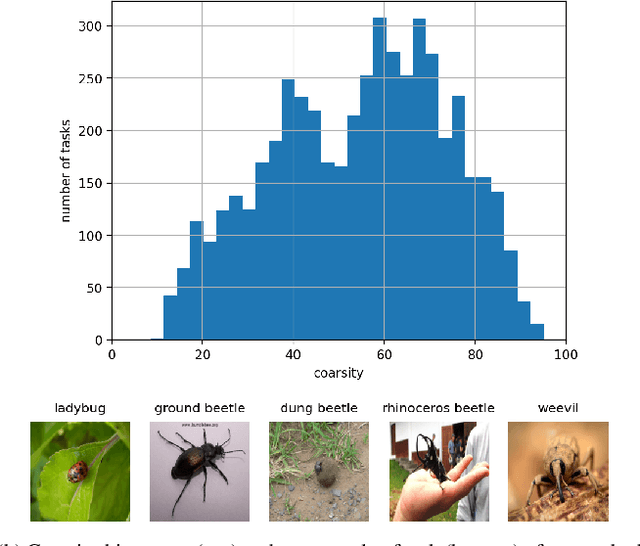
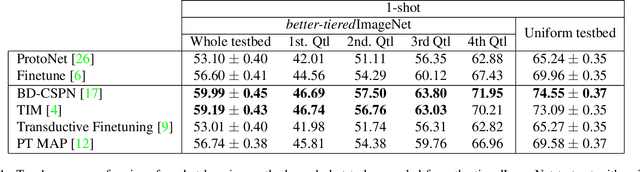
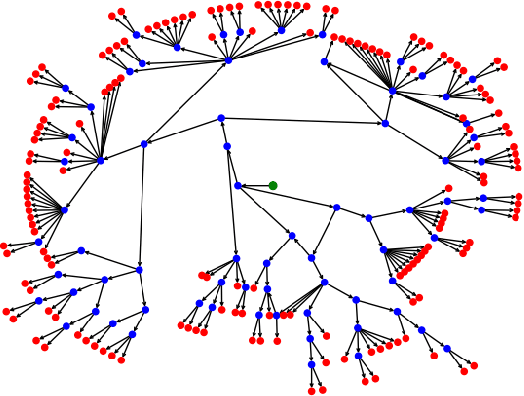
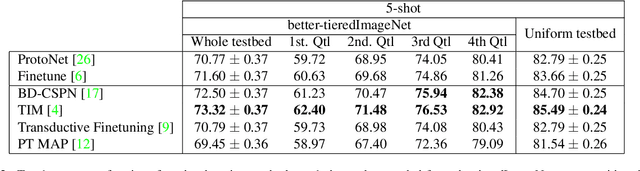
Every day, a new method is published to tackle Few-Shot Image Classification, showing better and better performances on academic benchmarks. Nevertheless, we observe that these current benchmarks do not accurately represent the real industrial use cases that we encountered. In this work, through both qualitative and quantitative studies, we expose that the widely used benchmark tieredImageNet is strongly biased towards tasks composed of very semantically dissimilar classes e.g. bathtub, cabbage, pizza, schipperke, and cardoon. This makes tieredImageNet (and similar benchmarks) irrelevant to evaluate the ability of a model to solve real-life use cases usually involving more fine-grained classification. We mitigate this bias using semantic information about the classes of tieredImageNet and generate an improved, balanced benchmark. Going further, we also introduce a new benchmark for Few-Shot Image Classification using the Danish Fungi 2020 dataset. This benchmark proposes a wide variety of evaluation tasks with various fine-graininess. Moreover, this benchmark includes many-way tasks (e.g. composed of 100 classes), which is a challenging setting yet very common in industrial applications. Our experiments bring out the correlation between the difficulty of a task and the semantic similarity between its classes, as well as a heavy performance drop of state-of-the-art methods on many-way few-shot classification, raising questions about the scaling abilities of these methods. We hope that our work will encourage the community to further question the quality of standard evaluation processes and their relevance to real-life applications.