 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Image Classification Benchmarks are Too Far From Reality: Build Back Better with Semantic Task Sampling
Paper and Code
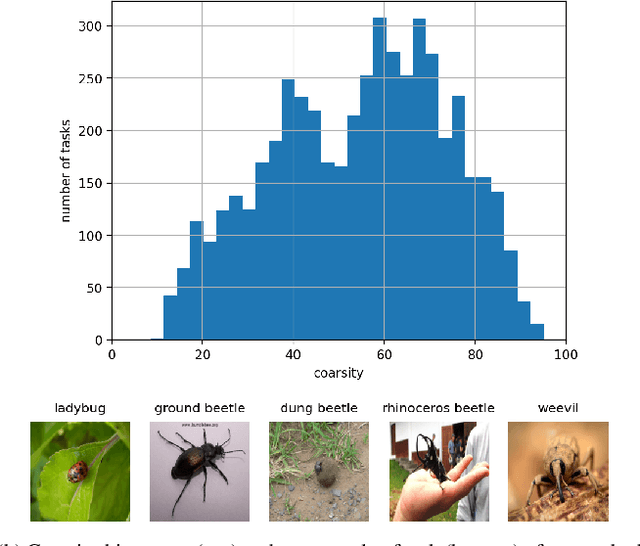
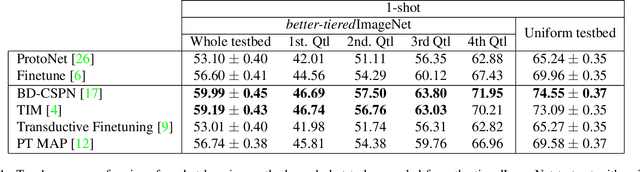
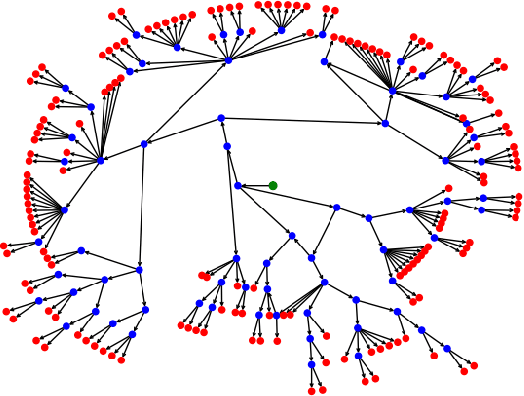
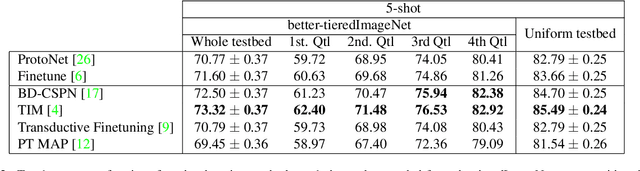
Every day, a new method is published to tackle Few-Shot Image Classification, showing better and better performances on academic benchmarks. Nevertheless, we observe that these current benchmarks do not accurately represent the real industrial use cases that we encountered. In this work, through both qualitative and quantitative studies, we expose that the widely used benchmark tieredImageNet is strongly biased towards tasks composed of very semantically dissimilar classes e.g. bathtub, cabbage, pizza, schipperke, and cardoon. This makes tieredImageNet (and similar benchmarks) irrelevant to evaluate the ability of a model to solve real-life use cases usually involving more fine-grained classification. We mitigate this bias using semantic information about the classes of tieredImageNet and generate an improved, balanced benchmark. Going further, we also introduce a new benchmark for Few-Shot Image Classification using the Danish Fungi 2020 dataset. This benchmark proposes a wide variety of evaluation tasks with various fine-graininess. Moreover, this benchmark includes many-way tasks (e.g. composed of 100 classes), which is a challenging setting yet very common in industrial applications. Our experiments bring out the correlation between the difficulty of a task and the semantic similarity between its classes, as well as a heavy performance drop of state-of-the-art methods on many-way few-shot classification, raising questions about the scaling abilities of these methods. We hope that our work will encourage the community to further question the quality of standard evaluation processes and their relevance to real-life applications.