 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN Explanations that do not Explain and How to find Them
Jan 28, 2026Explanations provided by Self-explainable Graph Neural Networks (SE-GNNs) are fundamental for understanding the model's inner workings and for identifying potential misuse of sensitive attributes. Although recent works have highlighted that these explanations can be suboptimal and potentially misleading, a characterization of their failure cases is unavailable. In this work, we identify a critical failure of SE-GNN explanations: explanations can be unambiguously unrelated to how the SE-GNNs infer labels. We show that, on the one hand, many SE-GNNs can achieve optimal true risk while producing these degenerate explanations, and on the other, most faithfulness metrics can fail to identify these failure modes. Our empirical analysis reveals that degenerate explanations can be maliciously planted (allowing an attacker to hide the use of sensitive attributes) and can also emerge naturally, highlighting the need for reliable auditing. To address this, we introduce a novel faithfulness metric that reliably marks degenerate explanations as unfaithful, in both malicious and natural settings. Our code is available in the supplemental.
Enhancing Concept Localization in CLIP-based Concept Bottleneck Models
Oct 08, 2025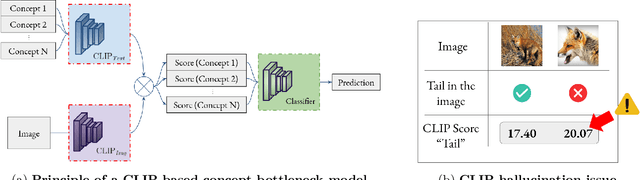

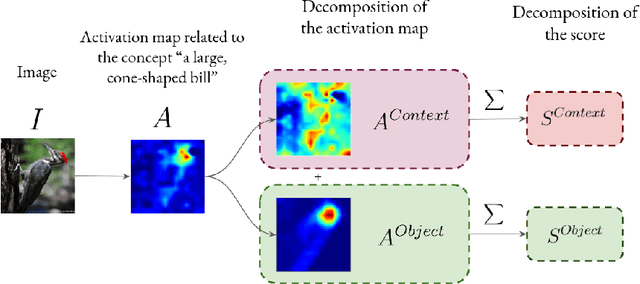

This paper addresses explainable AI (XAI) through the lens of Concept Bottleneck Models (CBMs) that do not require explicit concept annotations, relying instead on concepts extracted using CLIP in a zero-shot manner. We show that CLIP, which is central in these techniques, is prone to concept hallucination, incorrectly predicting the presence or absence of concepts within an image in scenarios used in numerous CBMs, hence undermining the faithfulness of explanations. To mitigate this issue, we introduce Concept Hallucination Inhibition via Localized Interpretability (CHILI), a technique that disentangles image embeddings and localizes pixels corresponding to target concepts. Furthermore, our approach supports the generation of saliency-based explanations that are more interpretable.
Beyond Topological Self-Explainable GNNs: A Formal Explainability Perspective
Feb 04, 2025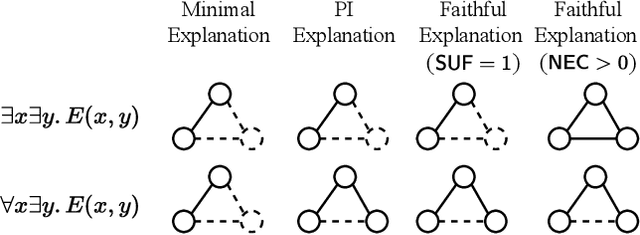
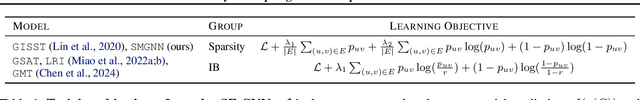


Self-Explainable Graph Neural Networks (SE-GNNs) are popular explainable-by-design GNNs, but the properties and the limitations of their explanations are not well understood. Our first contribution fills this gap by formalizing the explanations extracted by SE-GNNs, referred to as Trivial Explanations (TEs), and comparing them to established notions of explanations, namely Prime Implicant (PI) and faithful explanations. Our analysis reveals that TEs match PI explanations for a restricted but significant family of tasks. In general, however, they can be less informative than PI explanations and are surprisingly misaligned with widely accepted notions of faithfulness. Although faithful and PI explanations are informative, they are intractable to find and we show that they can be prohibitively large. Motivated by this, we propose Dual-Channel GNNs that integrate a white-box rule extractor and a standard SE-GNN, adaptively combining both channels when the task benefits. Our experiments show that even a simple instantiation of Dual-Channel GNNs can recover succinct rules and perform on par or better than widely used SE-GNNs. Our code can be found in the supplementary material.
Benchmarking XAI Explanations with Human-Aligned Evaluations
Nov 04, 2024


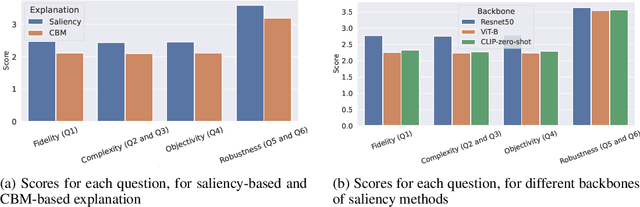
In this paper, we introduce PASTA (Perceptual Assessment System for explanaTion of Artificial intelligence), a novel framework for a human-centric evaluation of XAI techniques in computer vision. Our first key contribution is a human evaluation of XAI explanations on four diverse datasets (COCO, Pascal Parts, Cats Dogs Cars, and MonumAI) which constitutes the first large-scale benchmark dataset for XAI, with annotations at both the image and concept levels. This dataset allows for robust evaluation and comparison across various XAI methods. Our second major contribution is a data-based metric for assessing the interpretability of explanations. It mimics human preferences, based on a database of human evaluations of explanations in the PASTA-dataset. With its dataset and metric, the PASTA framework provides consistent and reliable comparisons between XAI techniques, in a way that is scalable but still aligned with human evaluations. Additionally, our benchmark allows for comparisons between explanations across different modalities, an aspect previously unaddressed. Our findings indicate that humans tend to prefer saliency maps over other explanation types. Moreover, we provide evidence that human assessments show a low correlation with existing XAI metrics that are numerically simulated by probing the model.
Perks and Pitfalls of Faithfulness in Regular, Self-Explainable and Domain Invariant GNNs
Jun 21, 2024As Graph Neural Networks (GNNs) become more pervasive, it becomes paramount to build robust tools for computing explanations of their predictions. A key desideratum is that these explanations are faithful, i.e., that they portray an accurate picture of the GNN's reasoning process. A number of different faithfulness metrics exist, begging the question of what faithfulness is exactly, and what its properties are. We begin by showing that existing metrics are not interchangeable -- i.e., explanations attaining high faithfulness according to one metric may be unfaithful according to others -- and can be systematically insensitive to important properties of the explanation, and suggest how to address these issues. We proceed to show that, surprisingly, optimizing for faithfulness is not always a sensible design goal. Specifically, we show that for injective regular GNN architectures, perfectly faithful explanations are completely uninformative. The situation is different for modular GNNs, such as self-explainable and domain-invariant architectures, where optimizing faithfulness does not compromise informativeness, and is also unexpectedly tied to out-of-distribution generalization.
Explaining the Explainers in Graph Neural Networks: a Comparative Study
Oct 27, 2022Following a fast initial breakthrough in graph based learning, Graph Neural Networks (GNNs) have reached a widespread application in many science and engineering fields, prompting the need for methods to understand their decision process. GNN explainers have started to emerge in recent years, with a multitude of methods both novel or adapted from other domains. To sort out this plethora of alternative approaches, several studies have benchmarked the performance of different explainers in terms of various explainability metrics. However, these earlier works make no attempts at providing insights into why different GNN architectures are more or less explainable, or which explainer should be preferred in a given setting. In this survey, we fill these gaps by devising a systematic experimental study, which tests ten explainers on eight representative architectures trained on six carefully designed graph and node classification datasets. With our results we provide key insights on the choice and applicability of GNN explainers, we isolate key components that make them usable and successful and provide recommendations on how to avoid common interpretation pitfalls. We conclude by highlighting open questions and directions of possible future research.
Global Explainability of GNNs via Logic Combination of Learned Concepts
Oct 14, 2022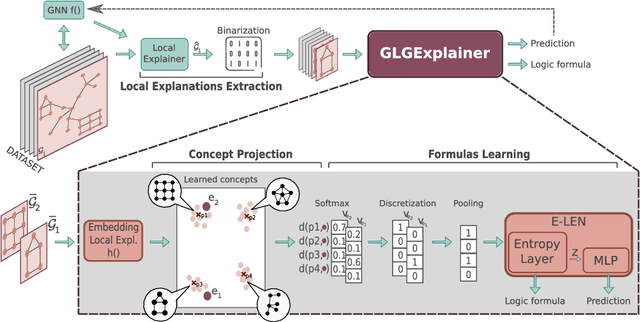

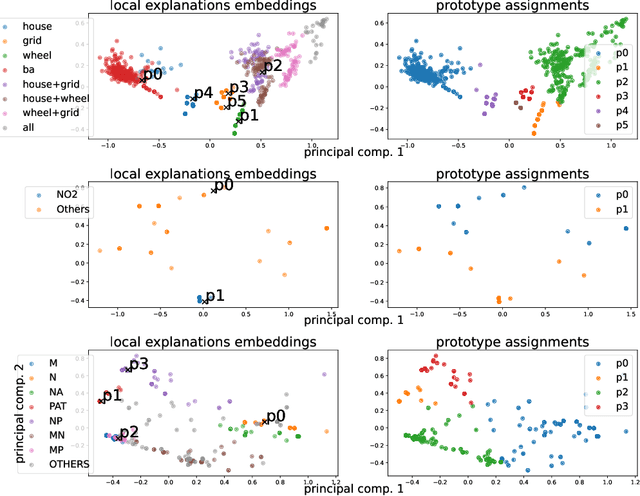
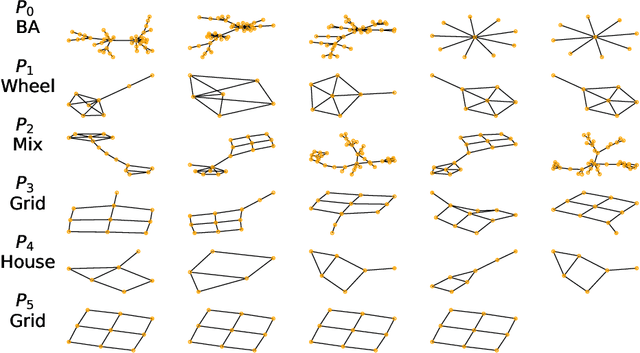
While instance-level explanation of GNN is a well-studied problem with plenty of approaches being developed, providing a global explanation for the behaviour of a GNN is much less explored, despite its potential in interpretability and debugging. Existing solutions either simply list local explanations for a given class, or generate a synthetic prototypical graph with maximal score for a given class, completely missing any combinatorial aspect that the GNN could have learned. In this work, we propose GLGExplainer (Global Logic-based GNN Explainer), the first Global Explainer capable of generating explanations as arbitrary Boolean combinations of learned graphical concepts. GLGExplainer is a fully differentiable architecture that takes local explanations as inputs and combines them into a logic formula over graphical concepts, represented as clusters of local explanations. Contrary to existing solutions, GLGExplainer provides accurate and human-interpretable global explanations that are perfectly aligned with ground-truth explanations (on synthetic data) or match existing domain knowledge (on real-world data). Extracted formulas are faithful to the model predictions, to the point of providing insights into some occasionally incorrect rules learned by the model, making GLGExplainer a promising diagnostic tool for learned GNNs.