 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Concept Localization in CLIP-based Concept Bottleneck Models
Oct 08, 2025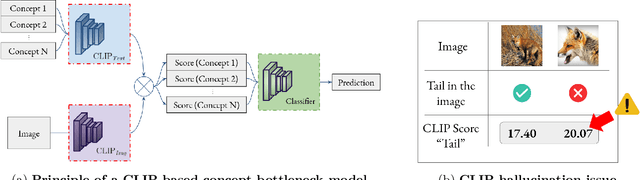

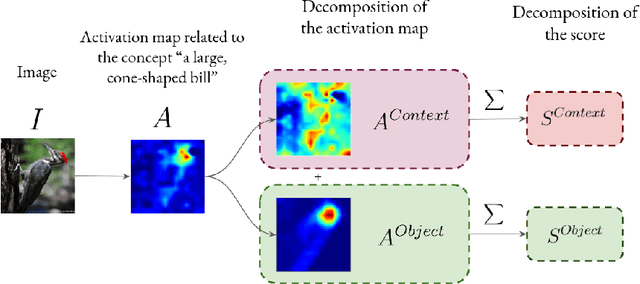

This paper addresses explainable AI (XAI) through the lens of Concept Bottleneck Models (CBMs) that do not require explicit concept annotations, relying instead on concepts extracted using CLIP in a zero-shot manner. We show that CLIP, which is central in these techniques, is prone to concept hallucination, incorrectly predicting the presence or absence of concepts within an image in scenarios used in numerous CBMs, hence undermining the faithfulness of explanations. To mitigate this issue, we introduce Concept Hallucination Inhibition via Localized Interpretability (CHILI), a technique that disentangles image embeddings and localizes pixels corresponding to target concepts. Furthermore, our approach supports the generation of saliency-based explanations that are more interpretable.
Explainability for Vision Foundation Models: A Survey
Jan 21, 2025


As artificial intelligence systems become increasingly integrated into daily life, the field of explainability has gained significant attention. This trend is particularly driven by the complexity of modern AI models and their decision-making processes. The advent of foundation models, characterized by their extensive generalization capabilities and emergent uses, has further complicated this landscape. Foundation models occupy an ambiguous position in the explainability domain: their complexity makes them inherently challenging to interpret, yet they are increasingly leveraged as tools to construct explainable models. In this survey, we explore the intersection of foundation models and eXplainable AI (XAI) in the vision domain. We begin by compiling a comprehensive corpus of papers that bridge these fields. Next, we categorize these works based on their architectural characteristics. We then discuss the challenges faced by current research in integrating XAI within foundation models. Furthermore, we review common evaluation methodologies for these combined approaches. Finally, we present key observations and insights from our survey, offering directions for future research in this rapidly evolving field.
Benchmarking XAI Explanations with Human-Aligned Evaluations
Nov 04, 2024


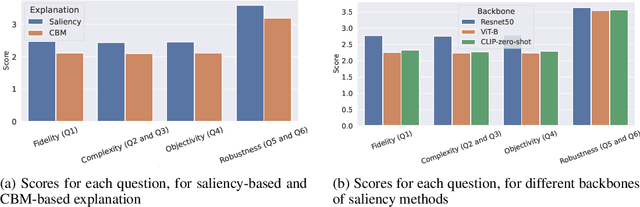
In this paper, we introduce PASTA (Perceptual Assessment System for explanaTion of Artificial intelligence), a novel framework for a human-centric evaluation of XAI techniques in computer vision. Our first key contribution is a human evaluation of XAI explanations on four diverse datasets (COCO, Pascal Parts, Cats Dogs Cars, and MonumAI) which constitutes the first large-scale benchmark dataset for XAI, with annotations at both the image and concept levels. This dataset allows for robust evaluation and comparison across various XAI methods. Our second major contribution is a data-based metric for assessing the interpretability of explanations. It mimics human preferences, based on a database of human evaluations of explanations in the PASTA-dataset. With its dataset and metric, the PASTA framework provides consistent and reliable comparisons between XAI techniques, in a way that is scalable but still aligned with human evaluations. Additionally, our benchmark allows for comparisons between explanations across different modalities, an aspect previously unaddressed. Our findings indicate that humans tend to prefer saliency maps over other explanation types. Moreover, we provide evidence that human assessments show a low correlation with existing XAI metrics that are numerically simulated by probing the model.
CLIP-QDA: An Explainable Concept Bottleneck Model
Nov 30, 2023



In this paper, we introduce an explainable algorithm designed from a multi-modal foundation model, that performs fast and explainable image classification. Drawing inspiration from CLIP-based Concept Bottleneck Models (CBMs), our method creates a latent space where each neuron is linked to a specific word. Observing that this latent space can be modeled with simple distributions, we use a Mixture of Gaussians (MoG) formalism to enhance the interpretability of this latent space. Then, we introduce CLIP-QDA, a classifier that only uses statistical values to infer labels from the concepts. In addition, this formalism allows for both local and global explanations. These explanations come from the inner design of our architecture, our work is part of a new family of greybox models, combining performances of opaque foundation models and the interpretability of transparent models. Our empirical findings show that in instances where the MoG assumption holds, CLIP-QDA achieves similar accuracy with state-of-the-art methods CBMs. Our explanations compete with existing XAI methods while being faster to compute.
Learning to Generate Training Datasets for Robust Semantic Segmentation
Aug 18, 2023



Semantic segmentation techniques have shown significant progress in recent years, but their robustness to real-world perturbations and data samples not seen during training remains a challenge, particularly in safety-critical applications. In this paper, we propose a novel approach to improve the robustness of semantic segmentation techniques by leveraging the synergy between label-to-image generators and image-to-label segmentation models. Specifically, we design and train Robusta, a novel robust conditional generative adversarial network to generate realistic and plausible perturbed or outlier images that can be used to train reliable segmentation models. We conduct in-depth studies of the proposed generative model, assess the performance and robustness of the downstream segmentation network, and demonstrate that our approach can significantly enhance the robustness of semantic segmentation techniques in the face of real-world perturbations, distribution shifts, and out-of-distribution samples. Our results suggest that this approach could be valuable in safety-critical applications, where the reliability of semantic segmentation techniques is of utmost importance and comes with a limited computational budget in inference. We will release our code shortly.
MUAD: Multiple Uncertainties for Autonomous Driving benchmark for multiple uncertainty types and tasks
Mar 02, 2022
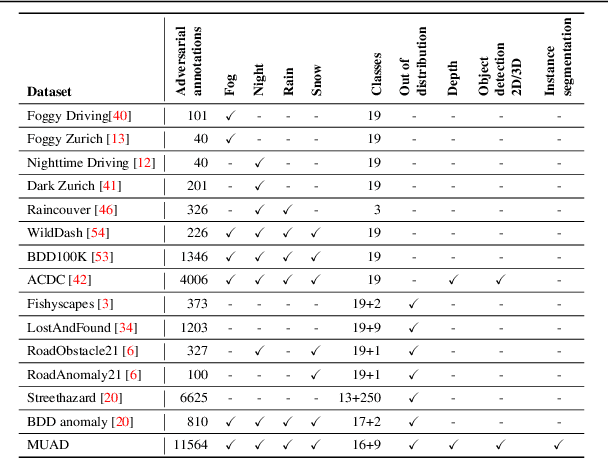
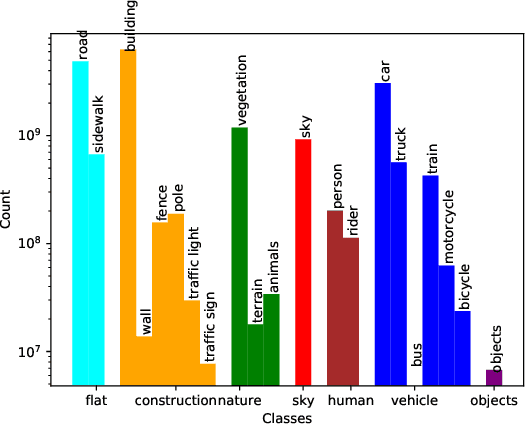
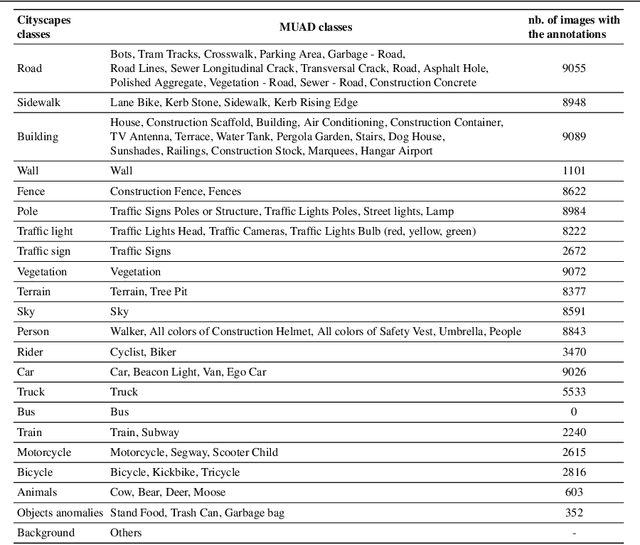
Predictive uncertainty estimation is essential for deploying Deep Neural Networks in real-world autonomous systems. However, disentangling the different types and sources of uncertainty is non trivial in most datasets, especially since there is no ground truth for uncertainty. In addition, different degrees of weather conditions can disrupt neural networks, resulting in inconsistent training data quality. Thus, we introduce the MUAD dataset (Multiple Uncertainties for Autonomous Driving), consisting of 8,500 realistic synthetic images with diverse adverse weather conditions (night, fog, rain, snow), out-of-distribution objects and annotations for semantic segmentation, depth estimation, object and instance detection. MUAD allows to better assess the impact of different sources of uncertainty on model performance. We propose a study that shows the importance of having reliable Deep Neural Networks (DNNs) in multiple experiments, and will release our dataset to allow researchers to benchmark their algorithm methodically in ad-verse conditions. More information and the download link for MUAD are available at https://muad-dataset.github.io/ .
A study of deep perceptual metrics for image quality assessment
Feb 17, 2022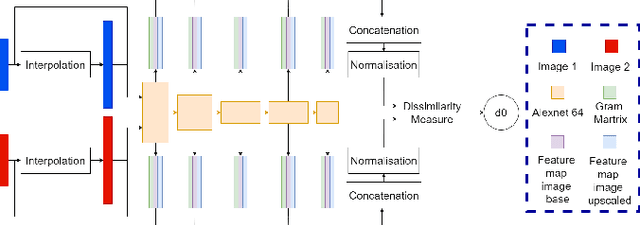
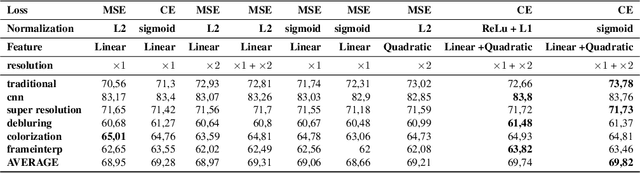
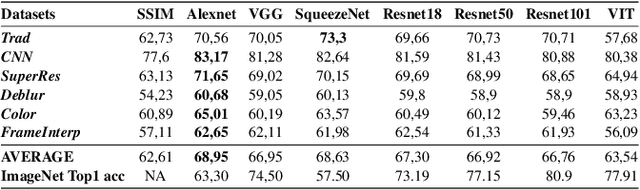
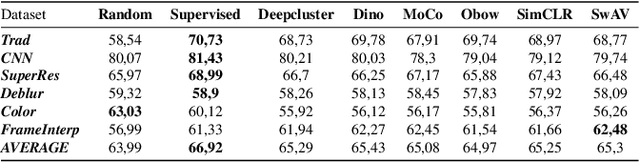
Several metrics exist to quantify the similarity between images, but they are inefficient when it comes to measure the similarity of highly distorted images. In this work, we propose to empirically investigate perceptual metrics based on deep neural networks for tackling the Image Quality Assessment (IQA) task. We study deep perceptual metrics according to different hyperparameters like the network's architecture or training procedure. Finally, we propose our multi-resolution perceptual metric (MR-Perceptual), that allows us to aggregate perceptual information at different resolutions and outperforms standard perceptual metrics on IQA tasks with varying image deformations. Our code is available at https://github.com/ENSTA-U2IS/MR_perceptual