 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Loss Functions for Neuro-Symbolic Structured Prediction
May 12, 2024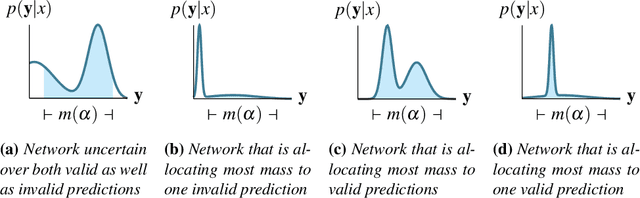
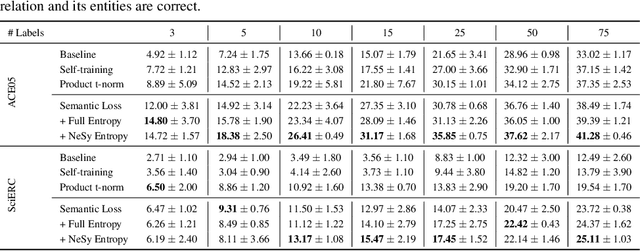
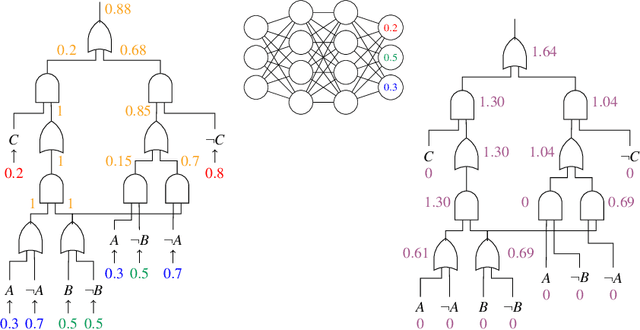
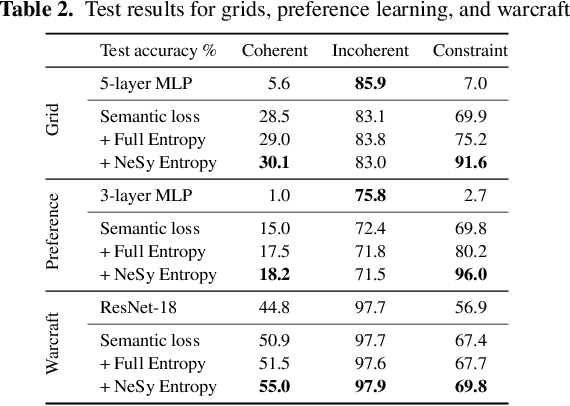
Structured output prediction problems are ubiquitous in machine learning. The prominent approach leverages neural networks as powerful feature extractors, otherwise assuming the independence of the outputs. These outputs, however, jointly encode an object, e.g. a path in a graph, and are therefore related through the structure underlying the output space. We discuss the semantic loss, which injects knowledge about such structure, defined symbolically, into training by minimizing the network's violation of such dependencies, steering the network towards predicting distributions satisfying the underlying structure. At the same time, it is agnostic to the arrangement of the symbols, and depends only on the semantics expressed thereby, while also enabling efficient end-to-end training and inference. We also discuss key improvements and applications of the semantic loss. One limitations of the semantic loss is that it does not exploit the association of every data point with certain features certifying its membership in a target class. We should therefore prefer minimum-entropy distributions over valid structures, which we obtain by additionally minimizing the neuro-symbolic entropy. We empirically demonstrate the benefits of this more refined formulation. Moreover, the semantic loss is designed to be modular and can be combined with both discriminative and generative neural models. This is illustrated by integrating it into generative adversarial networks, yielding constrained adversarial networks, a novel class of deep generative models able to efficiently synthesize complex objects obeying the structure of the underlying domain.
Efficient Generation of Structured Objects with Constrained Adversarial Networks
Jul 26, 2020


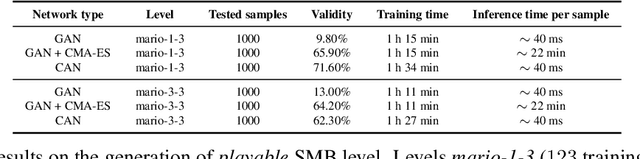
Generative Adversarial Networks (GANs) struggle to generate structured objects like molecules and game maps. The issue is that structured objects must satisfy hard requirements (e.g., molecules must be chemically valid) that are difficult to acquire from examples alone. As a remedy, we propose Constrained Adversarial Networks (CANs), an extension of GANs in which the constraints are embedded into the model during training. This is achieved by penalizing the generator proportionally to the mass it allocates to invalid structures. In contrast to other generative models, CANs support efficient inference of valid structures (with high probability) and allows to turn on and off the learned constraints at inference time. CANs handle arbitrary logical constraints and leverage knowledge compilation techniques to efficiently evaluate the disagreement between the model and the constraints. Our setup is further extended to hybrid logical-neural constraints for capturing very complex constraints, like graph reachability. An extensive empirical analysis shows that CANs efficiently generate valid structures that are both high-quality and novel.
Concept Tagging for Natural Language Understanding: Two Decadelong Algorithm Development
Jul 27, 2018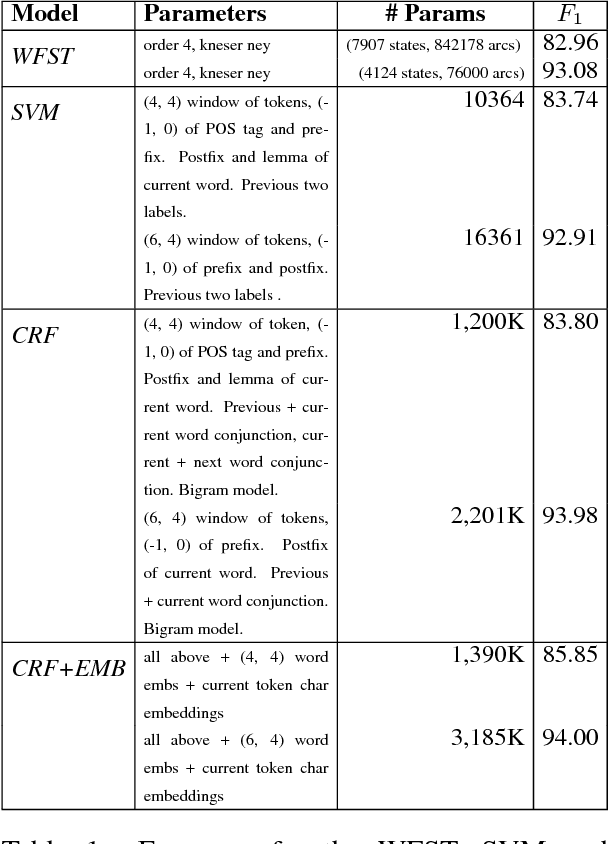
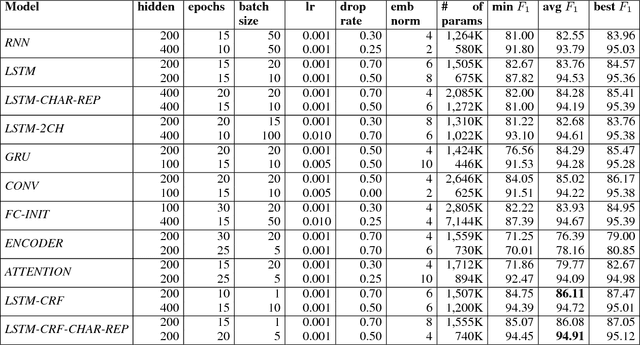
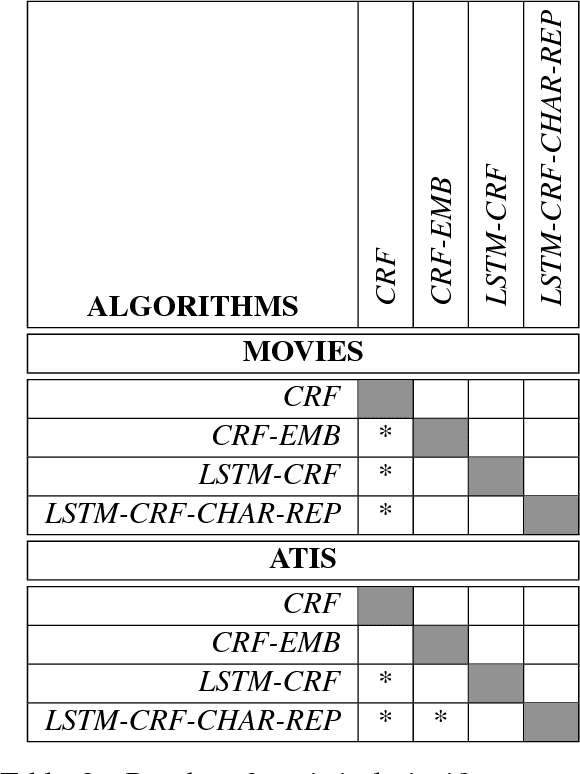
Concept tagging is a type of structured learning needed for natural language understanding (NLU) systems. In this task, meaning labels from a domain ontology are assigned to word sequences. In this paper, we review the algorithms developed over the last twenty five years. We perform a comparative evaluation of generative, discriminative and deep learning methods on two public datasets. We report on the statistical variability performance measurements. The third contribution is the release of a repository of the algorithms, datasets and recipes for NLU evaluation.