 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarden-Path Traversal within GPT-2
Paper and Code

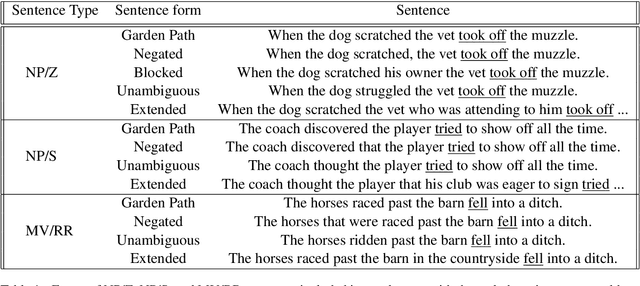
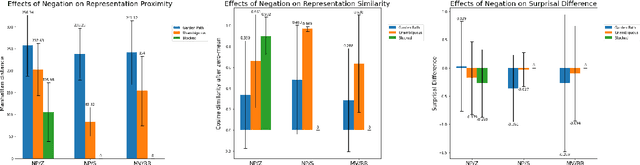
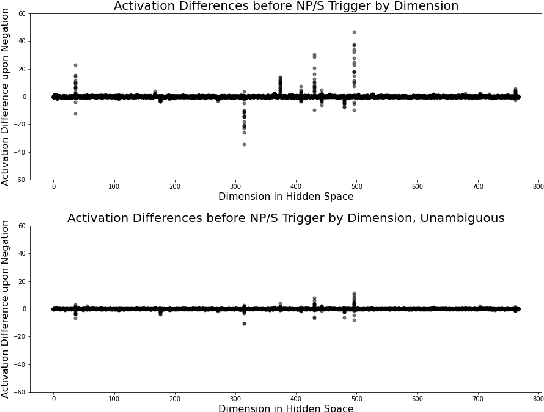
In recent years, massive language models consisting exclusively of transformer decoders, led by the GPT-x family, have become increasingly popular. While studies have examined the behavior of these models, they tend to only focus on the output of the language model, avoiding analyzing their internal states despite such analyses being popular tools used within BERTology to study transformer encoders. We present a collection of methods for analyzing GPT-2's hidden states, and use the model's navigation of garden path sentences as a case study to demonstrate the utility of studying this model's behavior beyond its output alone. To support this analysis, we introduce a novel dataset consisting of 3 different types of garden path sentences, along with scripts to manipulate them. We find that measuring Manhattan distances and cosine similarities between hidden states shows that GPT-2 navigates these sentences more intuitively than conventional methods that predict from the model's output alone.