 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Texture Generation for 3D Head Modeling with Artist-driven Control
May 07, 2025Creating realistic 3D head assets for virtual characters that match a precise artistic vision remains labor-intensive. We present a novel framework that streamlines this process by providing artists with intuitive control over generated 3D heads. Our approach uses a geometry-aware texture synthesis pipeline that learns correlations between head geometry and skin texture maps across different demographics. The framework offers three levels of artistic control: manipulation of overall head geometry, adjustment of skin tone while preserving facial characteristics, and fine-grained editing of details such as wrinkles or facial hair. Our pipeline allows artists to make edits to a single texture map using familiar tools, with our system automatically propagating these changes coherently across the remaining texture maps needed for realistic rendering. Experiments demonstrate that our method produces diverse results with clean geometries. We showcase practical applications focusing on intuitive control for artists, including skin tone adjustments and simplified editing workflows for adding age-related details or removing unwanted features from scanned models. This integrated approach aims to streamline the artistic workflow in virtual character creation.
ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech
Sep 23, 2022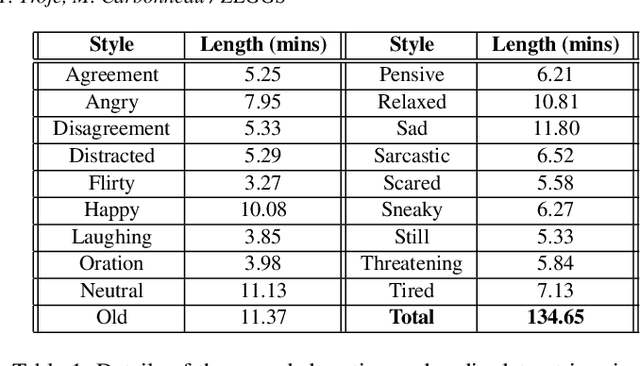
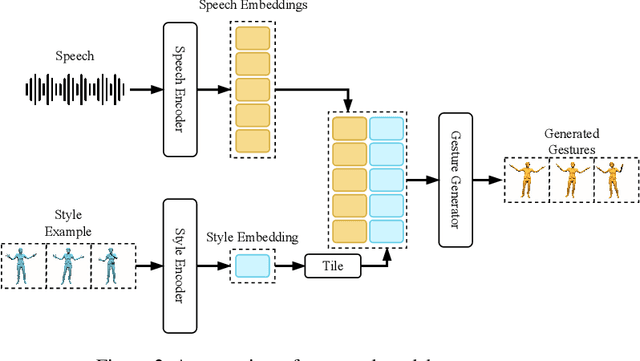

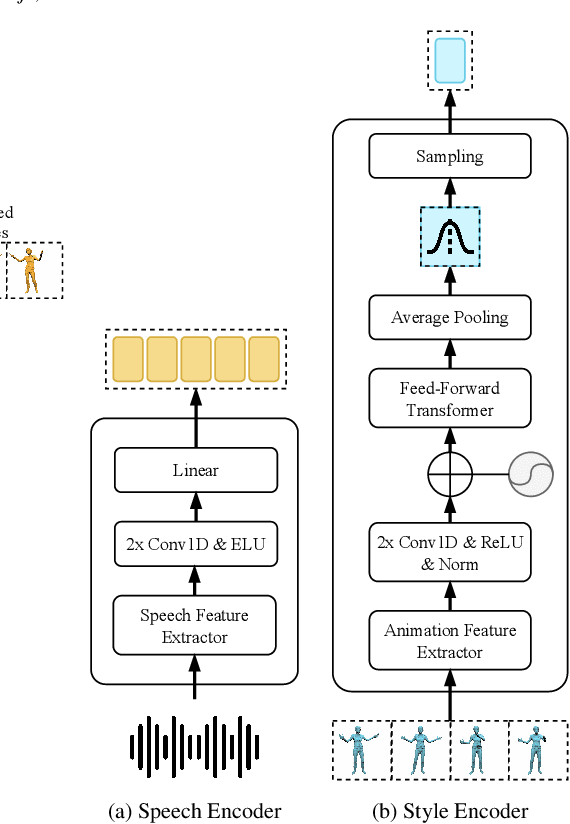
We present ZeroEGGS, a neural network framework for speech-driven gesture generation with zero-shot style control by example. This means style can be controlled via only a short example motion clip, even for motion styles unseen during training. Our model uses a Variational framework to learn a style embedding, making it easy to modify style through latent space manipulation or blending and scaling of style embeddings. The probabilistic nature of our framework further enables the generation of a variety of outputs given the same input, addressing the stochastic nature of gesture motion. In a series of experiments, we first demonstrate the flexibility and generalizability of our model to new speakers and styles. In a user study, we then show that our model outperforms previous state-of-the-art techniques in naturalness of motion, appropriateness for speech, and style portrayal. Finally, we release a high-quality dataset of full-body gesture motion including fingers, with speech, spanning across 19 different styles.
Gait Recognition using Multi-Scale Partial Representation Transformation with Capsules
Oct 18, 2020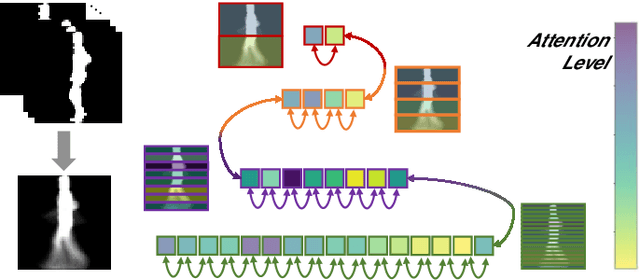
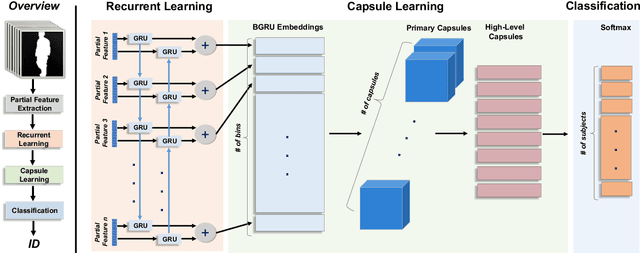

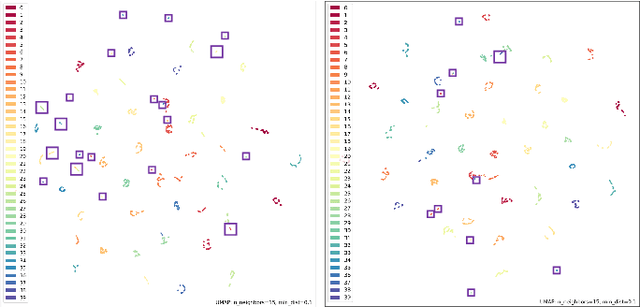
Gait recognition, referring to the identification of individuals based on the manner in which they walk, can be very challenging due to the variations in the viewpoint of the camera and the appearance of individuals. Current methods for gait recognition have been dominated by deep learning models, notably those based on partial feature representations. In this context, we propose a novel deep network, learning to transfer multi-scale partial gait representations using capsules to obtain more discriminative gait features. Our network first obtains multi-scale partial representations using a state-of-the-art deep partial feature extractor. It then recurrently learns the correlations and co-occurrences of the patterns among the partial features in forward and backward directions using Bi-directional Gated Recurrent Units (BGRU). Finally, a capsule network is adopted to learn deeper part-whole relationships and assigns more weights to the more relevant features while ignoring the spurious dimensions. That way, we obtain final features that are more robust to both viewing and appearance changes. The performance of our method has been extensively tested on two gait recognition datasets, CASIA-B and OU-MVLP, using four challenging test protocols. The results of our method have been compared to the state-of-the-art gait recognition solutions, showing the superiority of our model, notably when facing challenging viewing and carrying conditions.
MoVi: A Large Multipurpose Motion and Video Dataset
Mar 04, 2020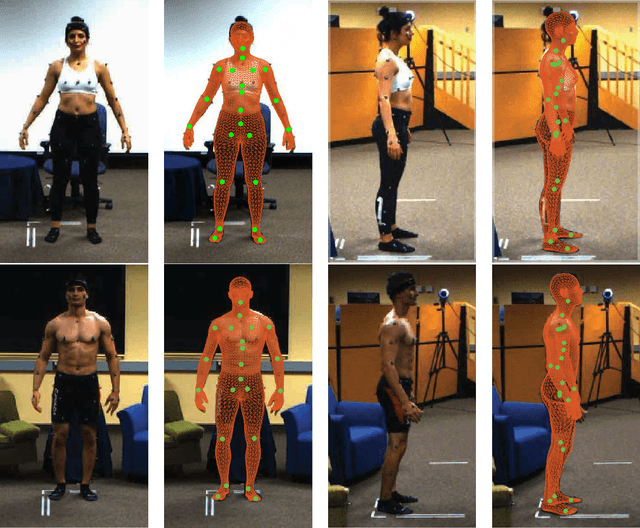
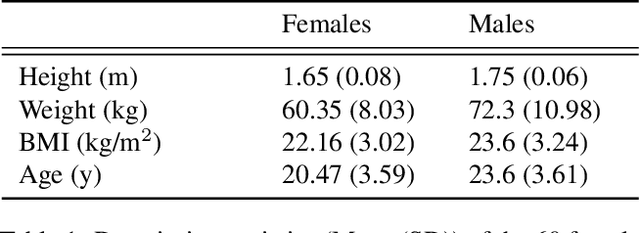
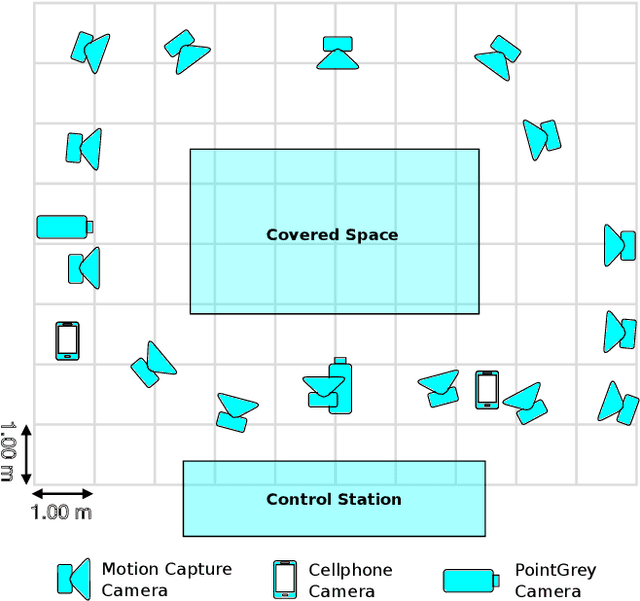
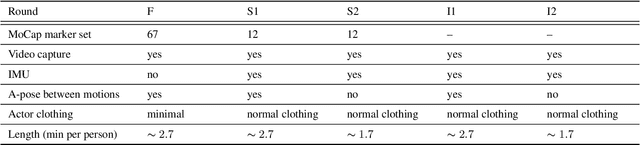
Human movements are both an area of intense study and the basis of many applications such as character animation. For many applications, it is crucial to identify movements from videos or analyze datasets of movements. Here we introduce a new human Motion and Video dataset MoVi, which we make available publicly. It contains 60 female and 30 male actors performing a collection of 20 predefined everyday actions and sports movements, and one self-chosen movement. In five capture rounds, the same actors and movements were recorded using different hardware systems, including an optical motion capture system, video cameras, and inertial measurement units (IMU). For some of the capture rounds, the actors were recorded when wearing natural clothing, for the other rounds they wore minimal clothing. In total, our dataset contains 9 hours of motion capture data, 17 hours of video data from 4 different points of view (including one hand-held camera), and 6.6 hours of IMU data. In this paper, we describe how the dataset was collected and post-processed; We present state-of-the-art estimates of skeletal motions and full-body shape deformations associated with skeletal motion. We discuss examples for potential studies this dataset could enable.
Auto-labelling of Markers in Optical Motion Capture by Permutation Learning
Jul 31, 2019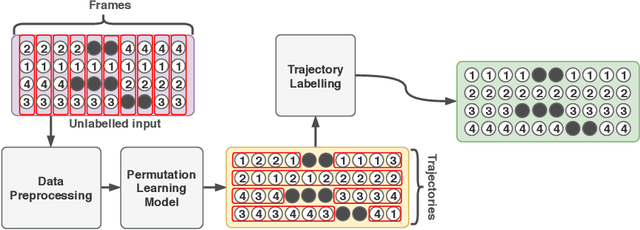

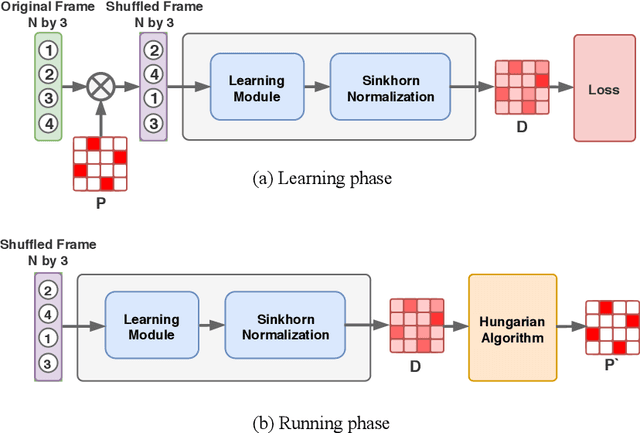
Optical marker-based motion capture is a vital tool in applications such as motion and behavioural analysis, animation, and biomechanics. Labelling, that is, assigning optical markers to the pre-defined positions on the body is a time consuming and labour intensive postprocessing part of current motion capture pipelines. The problem can be considered as a ranking process in which markers shuffled by an unknown permutation matrix are sorted to recover the correct order. In this paper, we present a framework for automatic marker labelling which first estimates a permutation matrix for each individual frame using a differentiable permutation learning model and then utilizes temporal consistency to identify and correct remaining labelling errors. Experiments conducted on the test data show the effectiveness of our framework.
AMASS: Archive of Motion Capture as Surface Shapes
Apr 05, 2019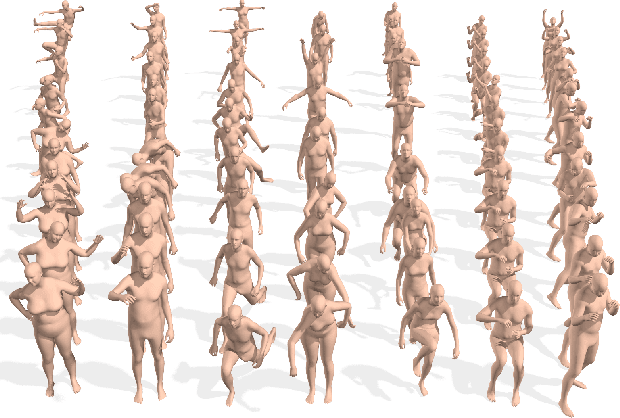
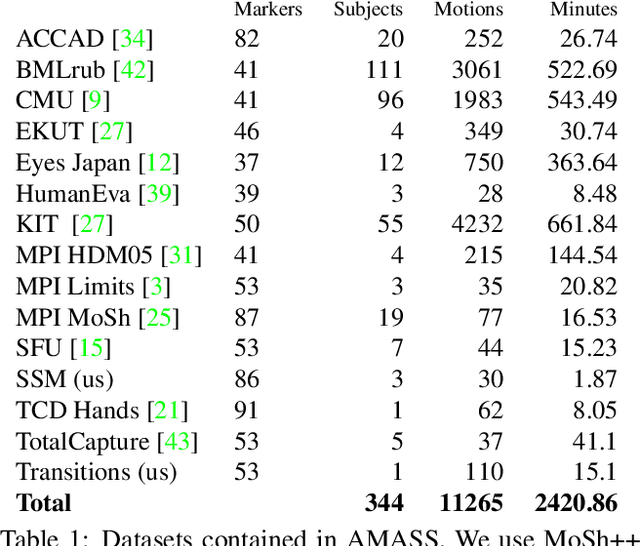
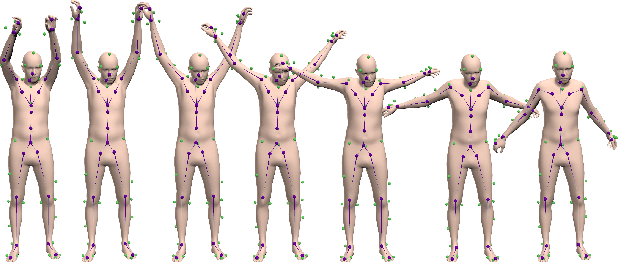

Large datasets are the cornerstone of recent advances in computer vision using deep learning. In contrast, existing human motion capture (mocap) datasets are small and the motions limited, hampering progress on learning models of human motion. While there are many different datasets available, they each use a different parameterization of the body, making it difficult to integrate them into a single meta dataset. To address this, we introduce AMASS, a large and varied database of human motion that unifies 15 different optical marker-based mocap datasets by representing them within a common framework and parameterization. We achieve this using a new method, MoSh++, that converts mocap data into realistic 3D human meshes represented by a rigged body model; here we use SMPL [doi:10.1145/2816795.2818013], which is widely used and provides a standard skeletal representation as well as a fully rigged surface mesh. The method works for arbitrary marker sets, while recovering soft-tissue dynamics and realistic hand motion. We evaluate MoSh++ and tune its hyperparameters using a new dataset of 4D body scans that are jointly recorded with marker-based mocap. The consistent representation of AMASS makes it readily useful for animation, visualization, and generating training data for deep learning. Our dataset is significantly richer than previous human motion collections, having more than 40 hours of motion data, spanning over 300 subjects, more than 11,000 motions, and will be publicly available to the research community.