 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceTopoNet: Facial Expression Recognition using Face Topology Learning
Sep 13, 2022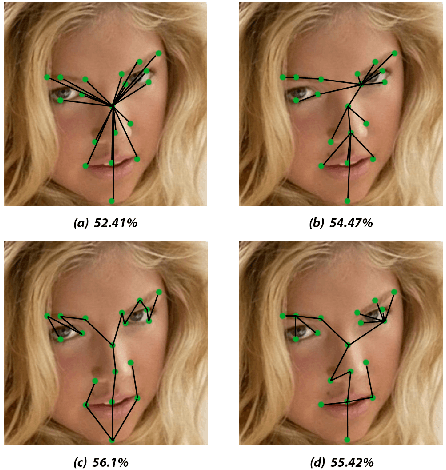

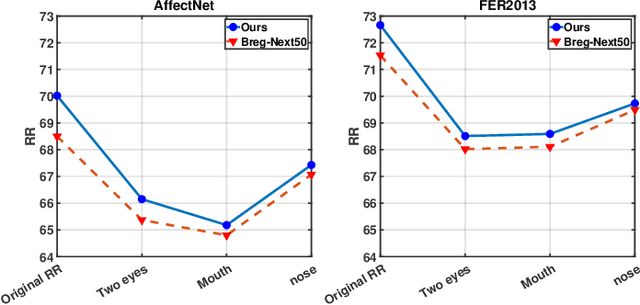
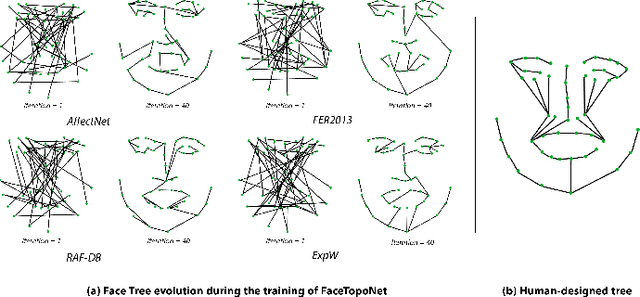
Prior work has shown that the order in which different components of the face are learned using a sequential learner can play an important role in the performance of facial expression recognition systems. We propose FaceTopoNet, an end-to-end deep model for facial expression recognition, which is capable of learning an effective tree topology of the face. Our model then traverses the learned tree to generate a sequence, which is then used to form an embedding to feed a sequential learner. The devised model adopts one stream for learning structure and one stream for learning texture. The structure stream focuses on the positions of the facial landmarks, while the main focus of the texture stream is on the patches around the landmarks to learn textural information. We then fuse the outputs of the two streams by utilizing an effective attention-based fusion strategy. We perform extensive experiments on four large-scale in-the-wild facial expression datasets - namely AffectNet, FER2013, ExpW, and RAF-DB - and one lab-controlled dataset (CK+) to evaluate our approach. FaceTopoNet achieves state-of-the-art performance on three of the five datasets and obtains competitive results on the other two datasets. We also perform rigorous ablation and sensitivity experiments to evaluate the impact of different components and parameters in our model. Lastly, we perform robustness experiments and demonstrate that FaceTopoNet is more robust against occlusions in comparison to other leading methods in the area.
Face Trees for Expression Recognition
Dec 05, 2021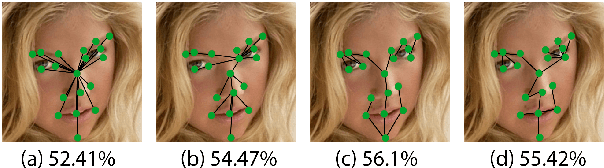
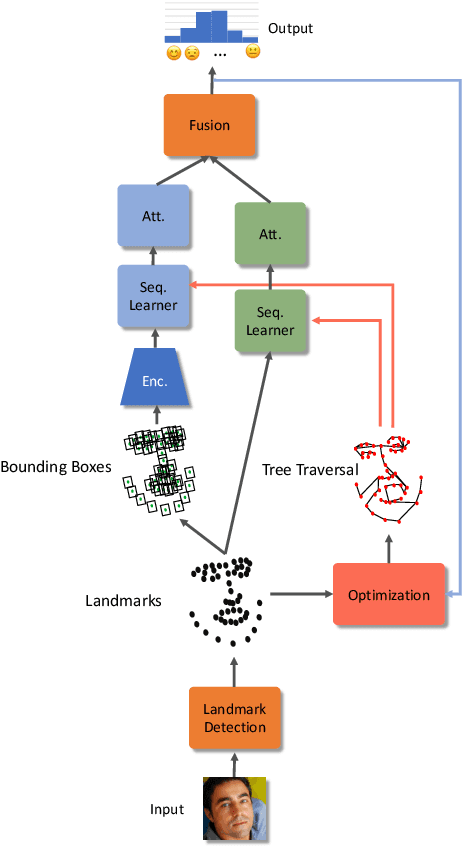
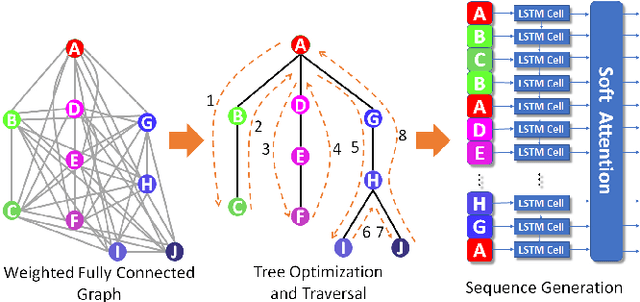
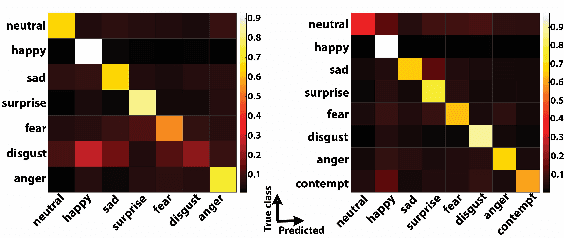
We propose an end-to-end architecture for facial expression recognition. Our model learns an optimal tree topology for facial landmarks, whose traversal generates a sequence from which we obtain an embedding to feed a sequential learner. The proposed architecture incorporates two main streams, one focusing on landmark positions to learn the structure of the face, while the other focuses on patches around the landmarks to learn texture information. Each stream is followed by an attention mechanism and the outputs are fed to a two-stream fusion component to perform the final classification. We conduct extensive experiments on two large-scale publicly available facial expression datasets, AffectNet and FER2013, to evaluate the efficacy of our approach. Our method outperforms other solutions in the area and sets new state-of-the-art expression recognition rates on these datasets.
Multi-Perspective LSTM for Joint Visual Representation Learning
May 06, 2021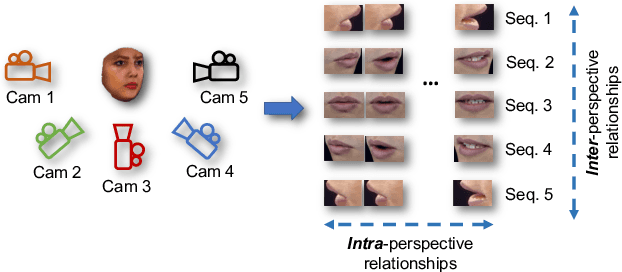
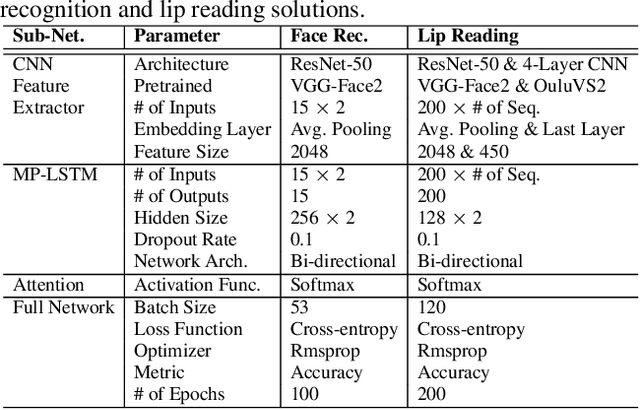
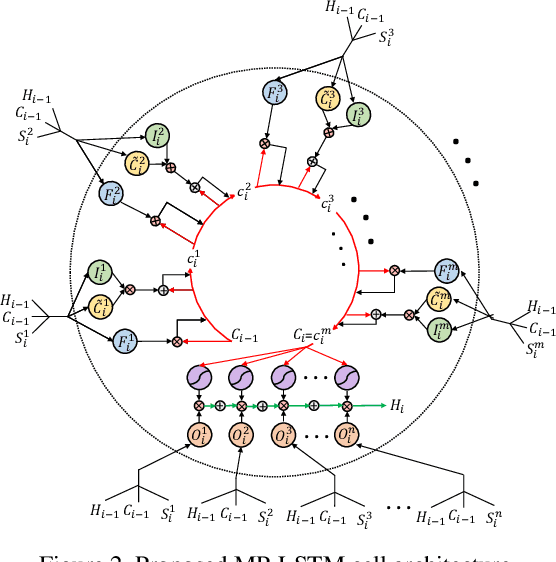
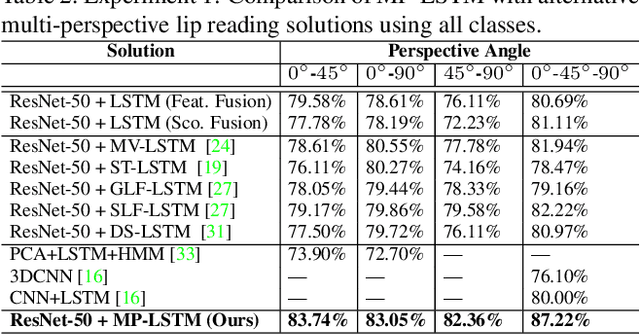
We present a novel LSTM cell architecture capable of learning both intra- and inter-perspective relationships available in visual sequences captured from multiple perspectives. Our architecture adopts a novel recurrent joint learning strategy that uses additional gates and memories at the cell level. We demonstrate that by using the proposed cell to create a network, more effective and richer visual representations are learned for recognition tasks. We validate the performance of our proposed architecture in the context of two multi-perspective visual recognition tasks namely lip reading and face recognition. Three relevant datasets are considered and the results are compared against fusion strategies, other existing multi-input LSTM architectures, and alternative recognition solutions. The experiments show the superior performance of our solution over the considered benchmarks, both in terms of recognition accuracy and complexity. We make our code publicly available at https://github.com/arsm/MPLSTM.
Teacher-Student Adversarial Depth Hallucination to Improve Face Recognition
Apr 06, 2021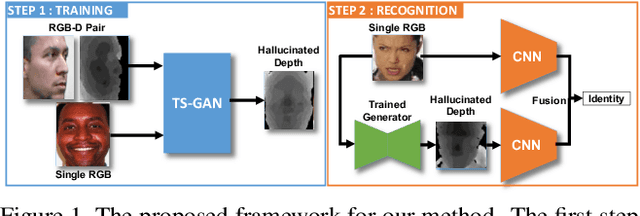
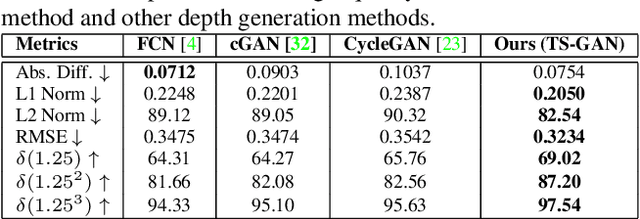
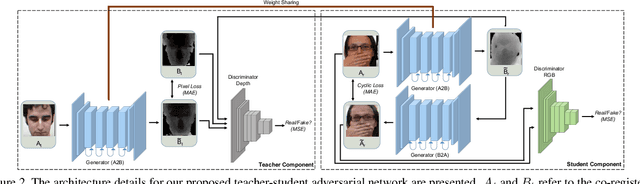
We present the Teacher-Student Generative Adversarial Network (TS-GAN) to generate depth images from a single RGB image in order to boost the recognition accuracy of face recognition (FR) systems. For our method to generalize well across unseen datasets, we design two components in the architecture, a teacher and a student. The teacher, which itself consists of a generator and a discriminator, learns a latent mapping between input RGB and paired depth images in a supervised fashion. The student, which consists of two generators (one shared with the teacher) and a discriminator, learns from new RGB data with no available paired depth information, for improved generalization. The fully trained shared generator can then be used in runtime to hallucinate depth from RGB for downstream applications such as face recognition. We perform rigorous experiments to show the superiority of TS-GAN over other methods in generating synthetic depth images. Moreover, face recognition experiments demonstrate that our hallucinated depth along with the input RGB images boosts performance across various architectures when compared to a single RGB modality by average values of +1.2%, +2.6%, and +2.6% for IIIT-D, EURECOM, and LFW datasets respectively.
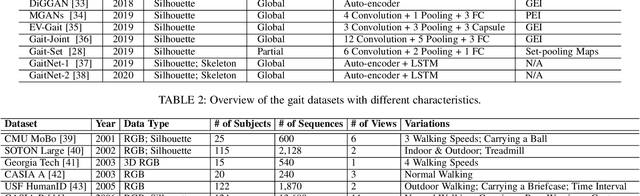
Deep Gait Recognition: A Survey
Feb 18, 2021
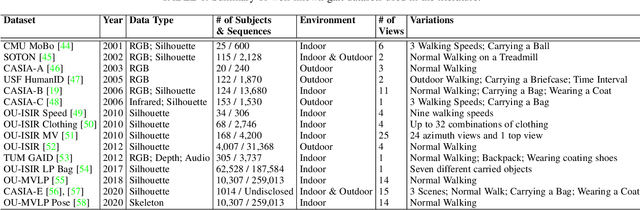

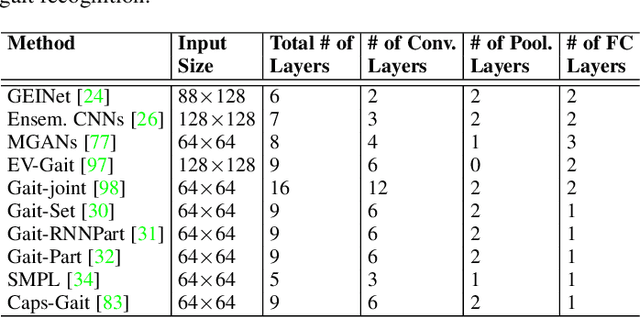
Gait recognition is an appealing biometric modality which aims to identify individuals based on the way they walk. Deep learning has reshaped the research landscape in this area since 2015 through the ability to automatically learn discriminative representations. Gait recognition methods based on deep learning now dominate the state-of-the-art in the field and have fostered real-world applications. In this paper, we present a comprehensive overview of breakthroughs and recent developments in gait recognition with deep learning, and cover broad topics including datasets, test protocols, state-of-the-art solutions, challenges, and future research directions. We first review the commonly used gait datasets along with the principles designed for evaluating them. We then propose a novel taxonomy made up of four separate dimensions namely body representation, temporal representation, feature representation, and neural architecture, to help characterize and organize the research landscape and literature in this area. Following our proposed taxonomy, a comprehensive survey of gait recognition methods using deep learning is presented with discussions on their performances, characteristics, advantages, and limitations. We conclude this survey with a discussion on current challenges and mention a number of promising directions for future research in gait recognition.
CapsField: Light Field-based Face and Expression Recognition in the Wild using Capsule Routing
Jan 10, 2021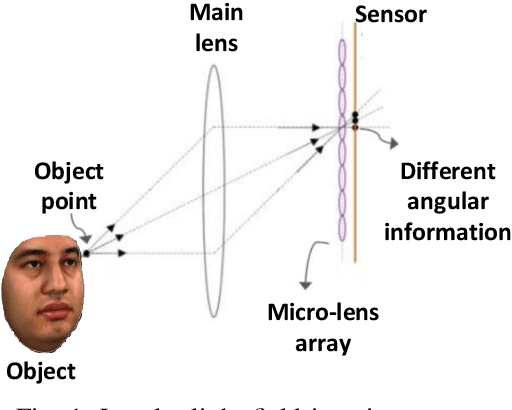
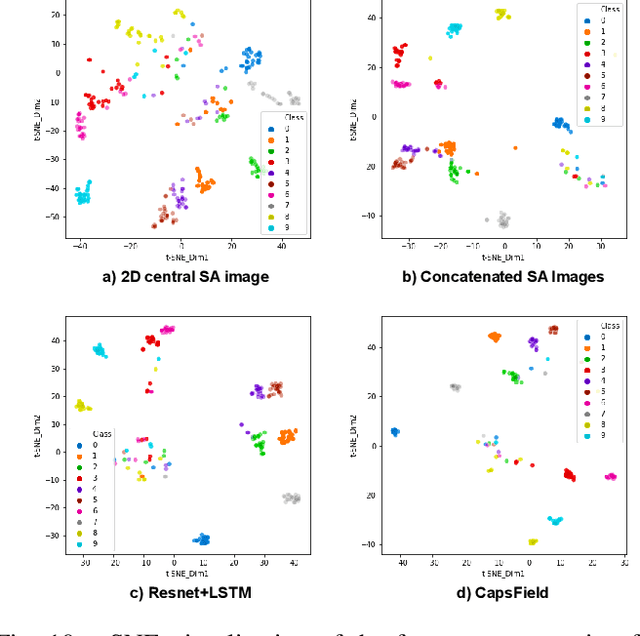
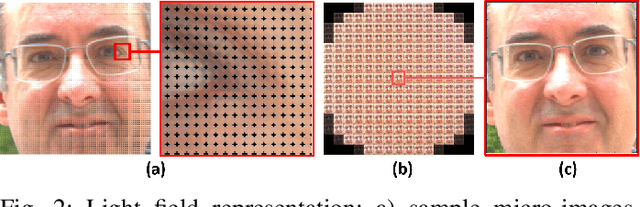
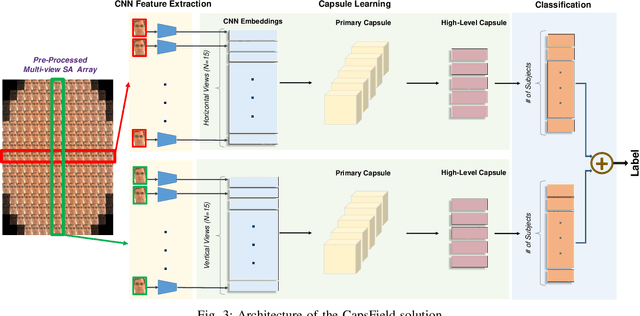
Light field (LF) cameras provide rich spatio-angular visual representations by sensing the visual scene from multiple perspectives and have recently emerged as a promising technology to boost the performance of human-machine systems such as biometrics and affective computing. Despite the significant success of LF representation for constrained facial image analysis, this technology has never been used for face and expression recognition in the wild. In this context, this paper proposes a new deep face and expression recognition solution, called CapsField, based on a convolutional neural network and an additional capsule network that utilizes dynamic routing to learn hierarchical relations between capsules. CapsField extracts the spatial features from facial images and learns the angular part-whole relations for a selected set of 2D sub-aperture images rendered from each LF image. To analyze the performance of the proposed solution in the wild, the first in the wild LF face dataset, along with a new complementary constrained face dataset captured from the same subjects recorded earlier have been captured and are made available. A subset of the in the wild dataset contains facial images with different expressions, annotated for usage in the context of face expression recognition tests. An extensive performance assessment study using the new datasets has been conducted for the proposed and relevant prior solutions, showing that the CapsField proposed solution achieves superior performance for both face and expression recognition tasks when compared to the state-of-the-art.
Depth as Attention for Face Representation Learning
Jan 03, 2021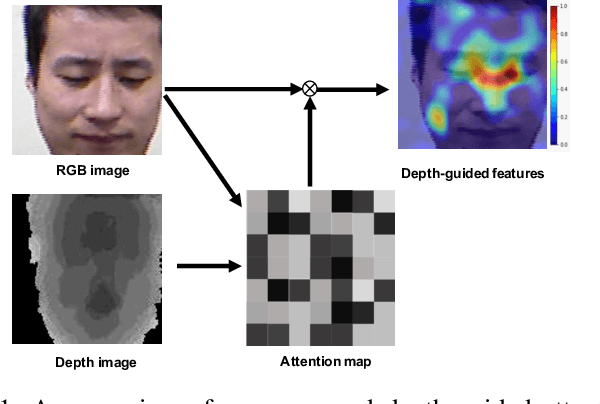
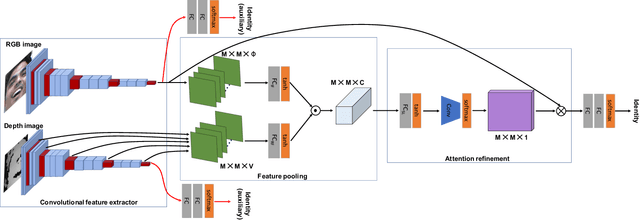
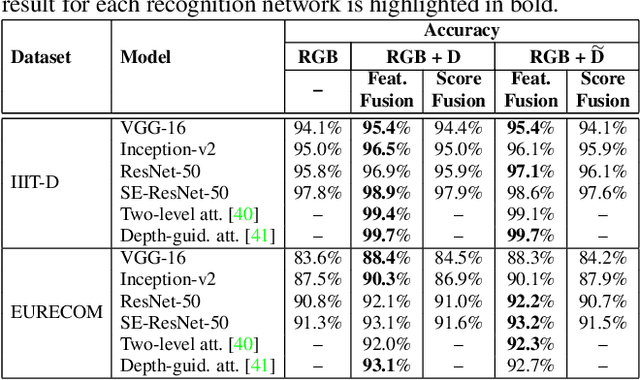
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
View-Invariant Gait Recognition with Attentive Recurrent Learning of Partial Representations
Oct 18, 2020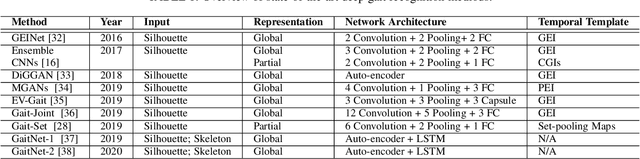
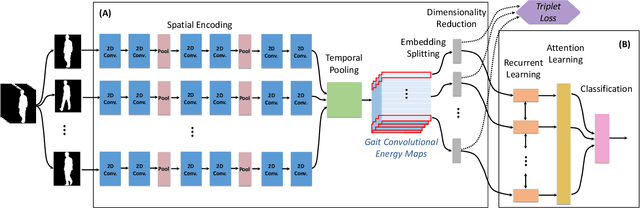

Gait recognition refers to the identification of individuals based on features acquired from their body movement during walking. Despite the recent advances in gait recognition with deep learning, variations in data acquisition and appearance, namely camera angles, subject pose, occlusions, and clothing, are challenging factors that need to be considered for achieving accurate gait recognition systems. In this paper, we propose a network that first learns to extract gait convolutional energy maps (GCEM) from frame-level convolutional features. It then adopts a bidirectional recurrent neural network to learn from split bins of the GCEM, thus exploiting the relations between learned partial spatiotemporal representations. We then use an attention mechanism to selectively focus on important recurrently learned partial representations as identity information in different scenarios may lie in different GCEM bins. Our proposed model has been extensively tested on two large-scale CASIA-B and OU-MVLP gait datasets using four different test protocols and has been compared to a number of state-of-the-art and baseline solutions. Additionally, a comprehensive experiment has been performed to study the robustness of our model in the presence of six different synthesized occlusions. The experimental results show the superiority of our proposed method, outperforming the state-of-the-art, especially in scenarios where different clothing and carrying conditions are encountered. The results also revealed that our model is more robust against different occlusions as compared to the state-of-the-art methods.
Gait Recognition using Multi-Scale Partial Representation Transformation with Capsules
Oct 18, 2020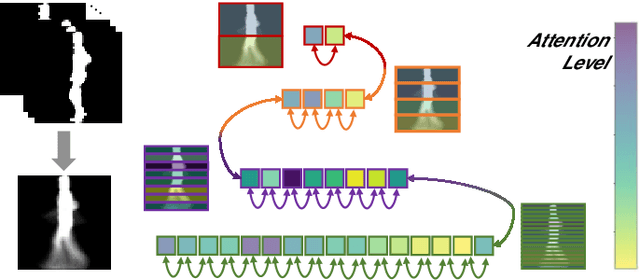
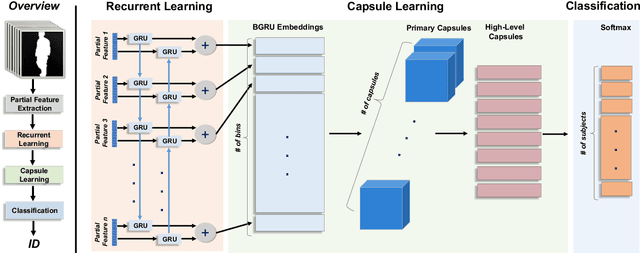

Gait recognition, referring to the identification of individuals based on the manner in which they walk, can be very challenging due to the variations in the viewpoint of the camera and the appearance of individuals. Current methods for gait recognition have been dominated by deep learning models, notably those based on partial feature representations. In this context, we propose a novel deep network, learning to transfer multi-scale partial gait representations using capsules to obtain more discriminative gait features. Our network first obtains multi-scale partial representations using a state-of-the-art deep partial feature extractor. It then recurrently learns the correlations and co-occurrences of the patterns among the partial features in forward and backward directions using Bi-directional Gated Recurrent Units (BGRU). Finally, a capsule network is adopted to learn deeper part-whole relationships and assigns more weights to the more relevant features while ignoring the spurious dimensions. That way, we obtain final features that are more robust to both viewing and appearance changes. The performance of our method has been extensively tested on two gait recognition datasets, CASIA-B and OU-MVLP, using four challenging test protocols. The results of our method have been compared to the state-of-the-art gait recognition solutions, showing the superiority of our model, notably when facing challenging viewing and carrying conditions.
Attention-aware fusion RGB-D face recognition
Feb 29, 2020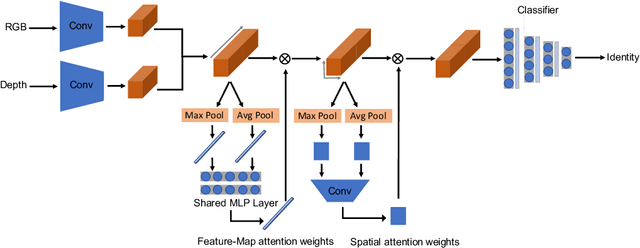



A novel attention aware method is proposed to fuse two image modalities, RGB and depth, for enhanced RGB-D facial recognition. The proposed method uses two attention layers, the first focused on the fused feature maps generated by convolution layers, and the second focused on the spatial features of those maps. The training database is preprocessed and augmented through a set of geometric transformations, and the learning process is further aided using transfer learning from a pure 2D RGB image training process. Comparative evaluations demonstrate that the proposed method outperforms other state-of-the-art approaches, including both traditional and deep neural network-based methods, on the challenging CurtinFaces and IIIT-D RGB-D benchmark databases, achieving classification accuracies over 98:2% and 99:3% respectively.