 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth as Attention for Face Representation Learning
Paper and Code
Jan 03, 2021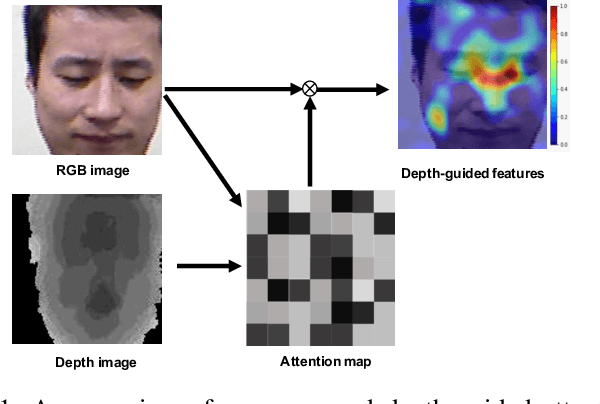
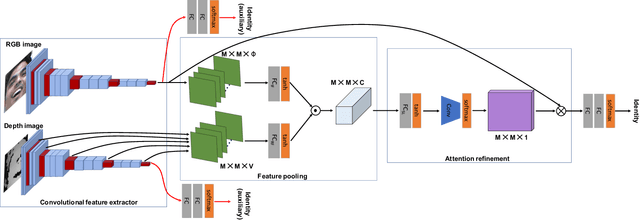
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information