 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Student Adversarial Depth Hallucination to Improve Face Recognition
Apr 06, 2021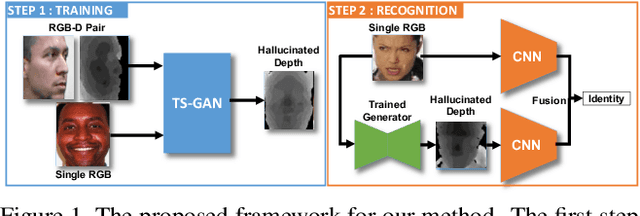
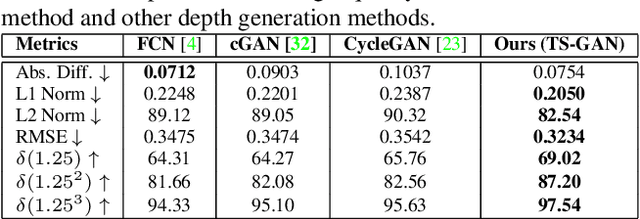
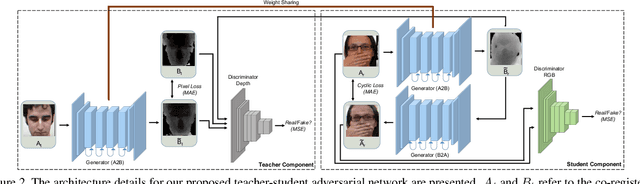
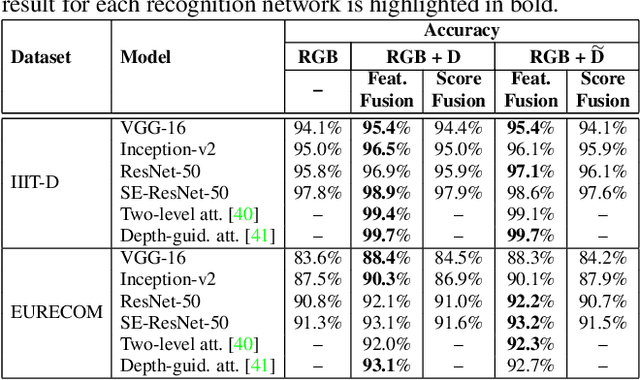
We present the Teacher-Student Generative Adversarial Network (TS-GAN) to generate depth images from a single RGB image in order to boost the recognition accuracy of face recognition (FR) systems. For our method to generalize well across unseen datasets, we design two components in the architecture, a teacher and a student. The teacher, which itself consists of a generator and a discriminator, learns a latent mapping between input RGB and paired depth images in a supervised fashion. The student, which consists of two generators (one shared with the teacher) and a discriminator, learns from new RGB data with no available paired depth information, for improved generalization. The fully trained shared generator can then be used in runtime to hallucinate depth from RGB for downstream applications such as face recognition. We perform rigorous experiments to show the superiority of TS-GAN over other methods in generating synthetic depth images. Moreover, face recognition experiments demonstrate that our hallucinated depth along with the input RGB images boosts performance across various architectures when compared to a single RGB modality by average values of +1.2%, +2.6%, and +2.6% for IIIT-D, EURECOM, and LFW datasets respectively.
Depth as Attention for Face Representation Learning
Jan 03, 2021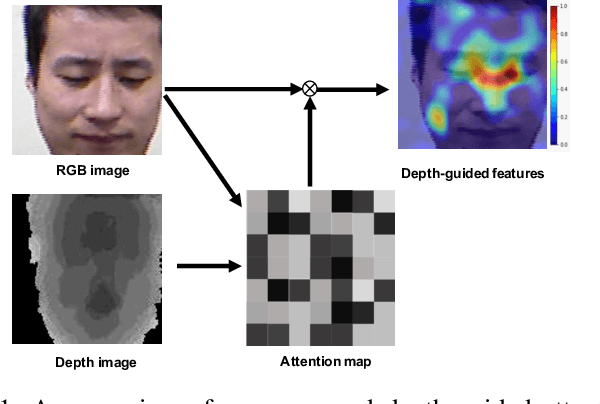
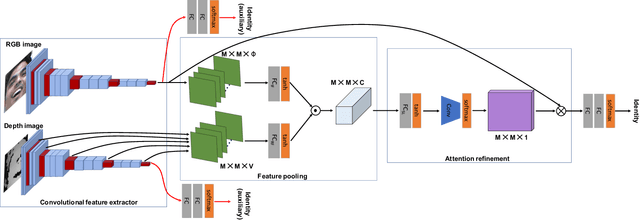
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
Attention-aware fusion RGB-D face recognition
Feb 29, 2020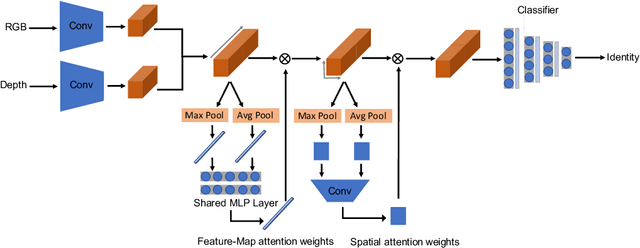



A novel attention aware method is proposed to fuse two image modalities, RGB and depth, for enhanced RGB-D facial recognition. The proposed method uses two attention layers, the first focused on the fused feature maps generated by convolution layers, and the second focused on the spatial features of those maps. The training database is preprocessed and augmented through a set of geometric transformations, and the learning process is further aided using transfer learning from a pure 2D RGB image training process. Comparative evaluations demonstrate that the proposed method outperforms other state-of-the-art approaches, including both traditional and deep neural network-based methods, on the challenging CurtinFaces and IIIT-D RGB-D benchmark databases, achieving classification accuracies over 98:2% and 99:3% respectively.