 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-aware fusion RGB-D face recognition
Paper and Code
Feb 29, 2020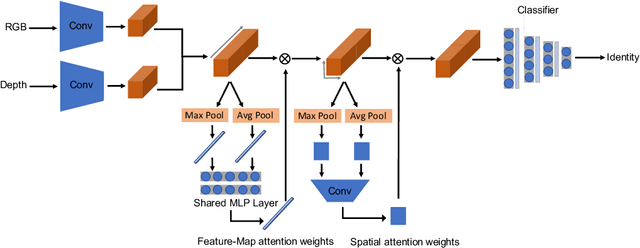



A novel attention aware method is proposed to fuse two image modalities, RGB and depth, for enhanced RGB-D facial recognition. The proposed method uses two attention layers, the first focused on the fused feature maps generated by convolution layers, and the second focused on the spatial features of those maps. The training database is preprocessed and augmented through a set of geometric transformations, and the learning process is further aided using transfer learning from a pure 2D RGB image training process. Comparative evaluations demonstrate that the proposed method outperforms other state-of-the-art approaches, including both traditional and deep neural network-based methods, on the challenging CurtinFaces and IIIT-D RGB-D benchmark databases, achieving classification accuracies over 98:2% and 99:3% respectively.