 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Trees for Expression Recognition
Paper and Code
Dec 05, 2021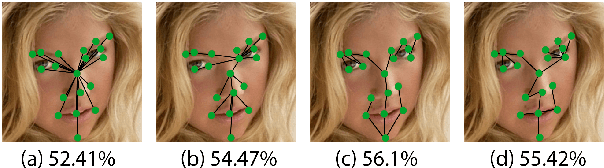
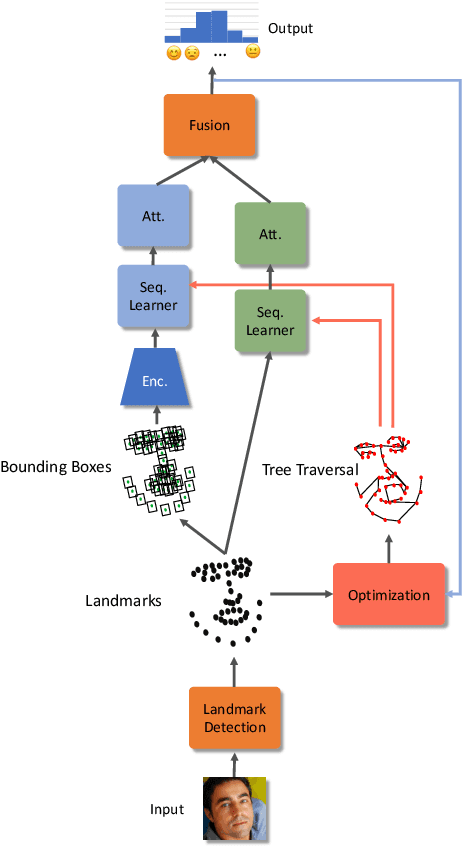
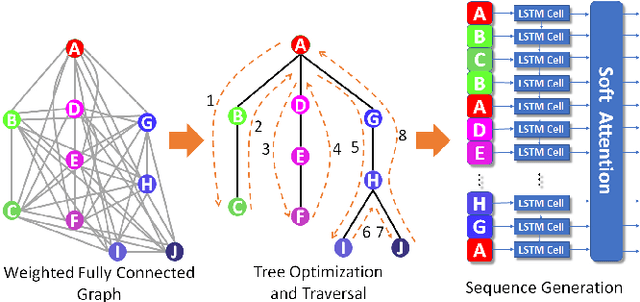
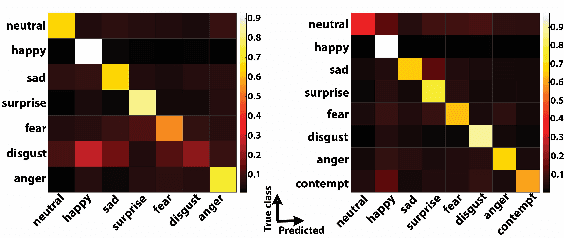
We propose an end-to-end architecture for facial expression recognition. Our model learns an optimal tree topology for facial landmarks, whose traversal generates a sequence from which we obtain an embedding to feed a sequential learner. The proposed architecture incorporates two main streams, one focusing on landmark positions to learn the structure of the face, while the other focuses on patches around the landmarks to learn texture information. Each stream is followed by an attention mechanism and the outputs are fed to a two-stream fusion component to perform the final classification. We conduct extensive experiments on two large-scale publicly available facial expression datasets, AffectNet and FER2013, to evaluate the efficacy of our approach. Our method outperforms other solutions in the area and sets new state-of-the-art expression recognition rates on these datasets.