 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Perspective LSTM for Joint Visual Representation Learning
May 06, 2021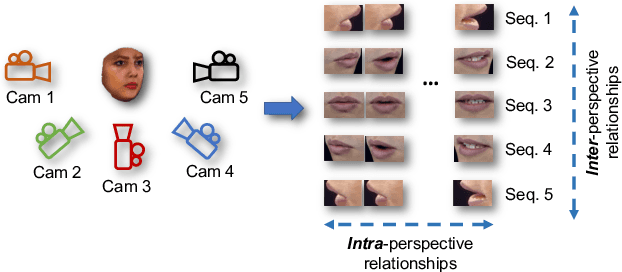
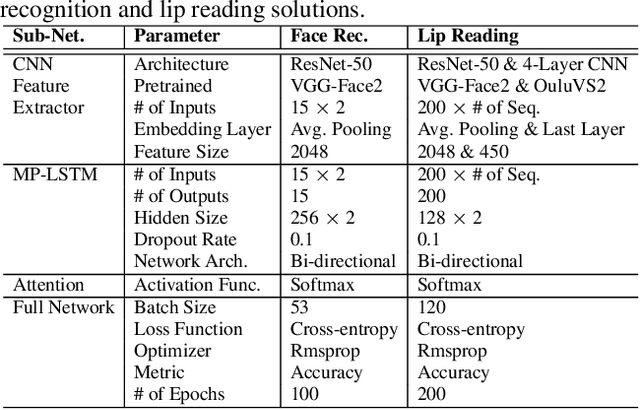
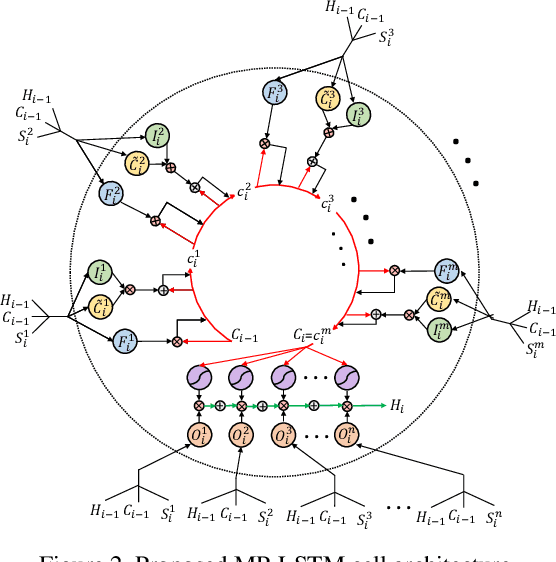
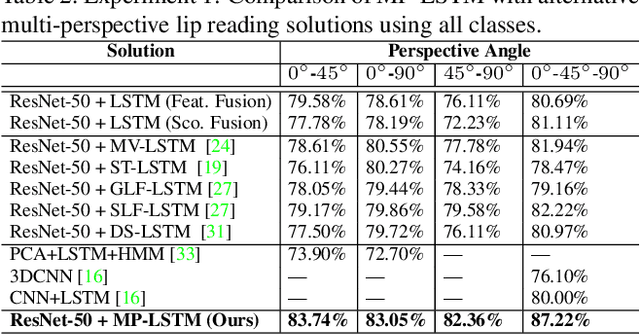
We present a novel LSTM cell architecture capable of learning both intra- and inter-perspective relationships available in visual sequences captured from multiple perspectives. Our architecture adopts a novel recurrent joint learning strategy that uses additional gates and memories at the cell level. We demonstrate that by using the proposed cell to create a network, more effective and richer visual representations are learned for recognition tasks. We validate the performance of our proposed architecture in the context of two multi-perspective visual recognition tasks namely lip reading and face recognition. Three relevant datasets are considered and the results are compared against fusion strategies, other existing multi-input LSTM architectures, and alternative recognition solutions. The experiments show the superior performance of our solution over the considered benchmarks, both in terms of recognition accuracy and complexity. We make our code publicly available at https://github.com/arsm/MPLSTM.
Remote Pathological Gait Classification System
May 04, 2021

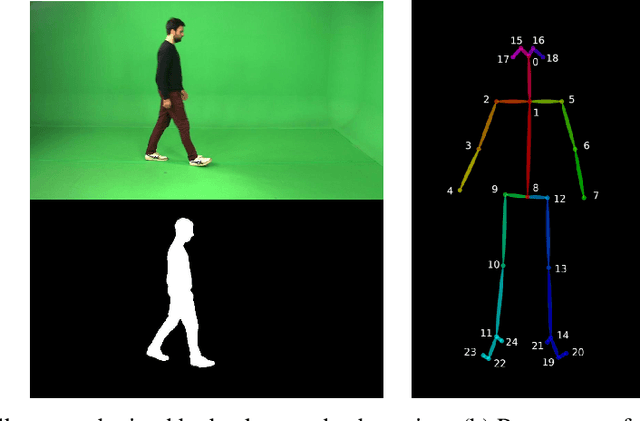
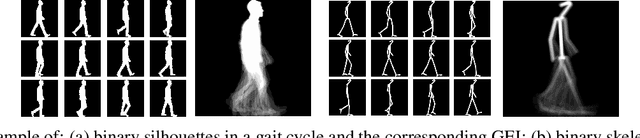
Several pathologies can alter the way people walk, i.e. their gait. Gait analysis can therefore be used to detect impairments and help diagnose illnesses and assess patient recovery. Using vision-based systems, diagnoses could be done at home or in a clinic, with the needed computation being done remotely. State-of-the-art vision-based gait analysis systems use deep learning, requiring large datasets for training. However, to our best knowledge, the biggest publicly available pathological gait dataset contains only 10 subjects, simulating 4 gait pathologies. This paper presents a new dataset called GAIT-IT, captured from 21 subjects simulating 4 gait pathologies, with 2 severity levels, besides normal gait, being considerably larger than publicly available gait pathology datasets, allowing to train a deep learning model for gait pathology classification. Moreover, it was recorded in a professional studio, making it possible to obtain nearly perfect silhouettes, free of segmentation errors. Recognizing the importance of remote healthcare, this paper proposes a prototype of a web application allowing to upload a walking person's video, possibly acquired using a smartphone camera, and execute a web service that classifies the person's gait as normal or across different pathologies. The web application has a user friendly interface and could be used by healthcare professionals or other end users. An automatic gait analysis system is also developed and integrated with the web application for pathology classification. Compared to state-of-the-art solutions, it achieves a drastic reduction in the number of model parameters, which means significantly lower memory requirements, as well as lower training and execution times. Classification accuracy is on par with the state-of-the-art.
CapsField: Light Field-based Face and Expression Recognition in the Wild using Capsule Routing
Jan 10, 2021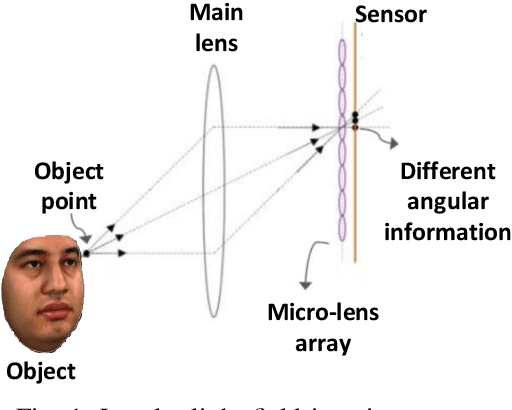
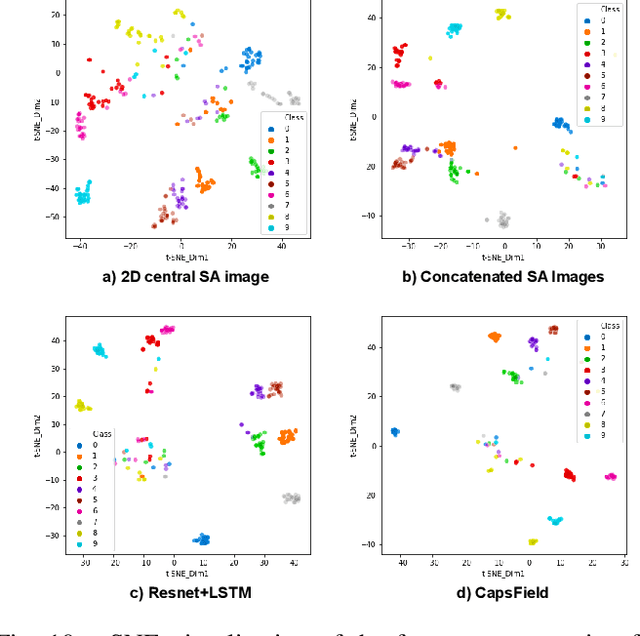
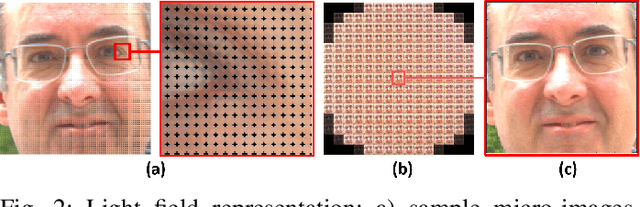
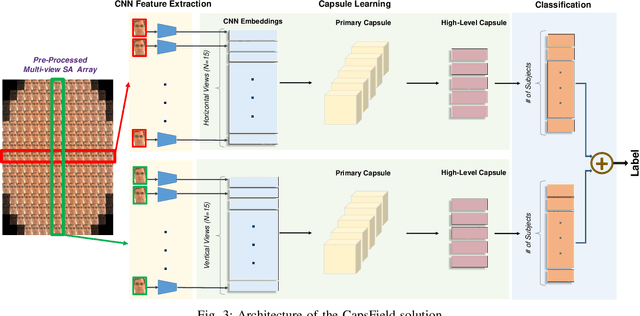
Light field (LF) cameras provide rich spatio-angular visual representations by sensing the visual scene from multiple perspectives and have recently emerged as a promising technology to boost the performance of human-machine systems such as biometrics and affective computing. Despite the significant success of LF representation for constrained facial image analysis, this technology has never been used for face and expression recognition in the wild. In this context, this paper proposes a new deep face and expression recognition solution, called CapsField, based on a convolutional neural network and an additional capsule network that utilizes dynamic routing to learn hierarchical relations between capsules. CapsField extracts the spatial features from facial images and learns the angular part-whole relations for a selected set of 2D sub-aperture images rendered from each LF image. To analyze the performance of the proposed solution in the wild, the first in the wild LF face dataset, along with a new complementary constrained face dataset captured from the same subjects recorded earlier have been captured and are made available. A subset of the in the wild dataset contains facial images with different expressions, annotated for usage in the context of face expression recognition tests. An extensive performance assessment study using the new datasets has been conducted for the proposed and relevant prior solutions, showing that the CapsField proposed solution achieves superior performance for both face and expression recognition tasks when compared to the state-of-the-art.
Novel Long Short-Term Memory Cell Architectures: Application to Light Field Face Recognition
May 11, 2019



With the emergence of lenslet light field cameras able to capture rich spatio-angular information from multiple directions, new frontiers in visual recognition performance have been opened. Since multiple 2D viewpoint images can be rendered from a light field, those multiple images, or descriptions extracted from them, can be organized as a pseudo-video sequence so that a LSTM network learns a model describing that sequence. This paper proposes three novel LSTM cell architectures able to create richer and more effective description models for visual recognition tasks, by jointly learning from two sequences simultaneously acquired. The novel key idea is to jointly process two sequences of rendered 2D images or their descriptions, e.g. representing the scene horizontal and vertical parallaxes, and thus with some specific dependency between them, that would not be exploited otherwise. To show the efficiency of the novel LSTM cell architectures, these architectures have been integrated into an end-to-end deep learning face recognition framework, which creates this join spatio-angular light field description. The LSTM network, using the proposed LSTM cell architectures, receives as input a sequence of VGG-Face descriptions computed for parallax related, horizontal and vertical 2D face viewpoint images, derived from the input light field image. A comprehensive evaluation in terms of recognition accuracy, computational complexity, memory efficiency, and parallelization ability has been performed with the IST EURECOM LFFD database using three new and challenging evaluation protocols. The obtained results show the superior performance of the proposed face recognition solutions adopting the novel LSTM cell architectures over ten state-of-the-art benchmarking recognition solutions.
Face Recognition: A Novel Multi-Level Taxonomy based Survey
Jan 03, 2019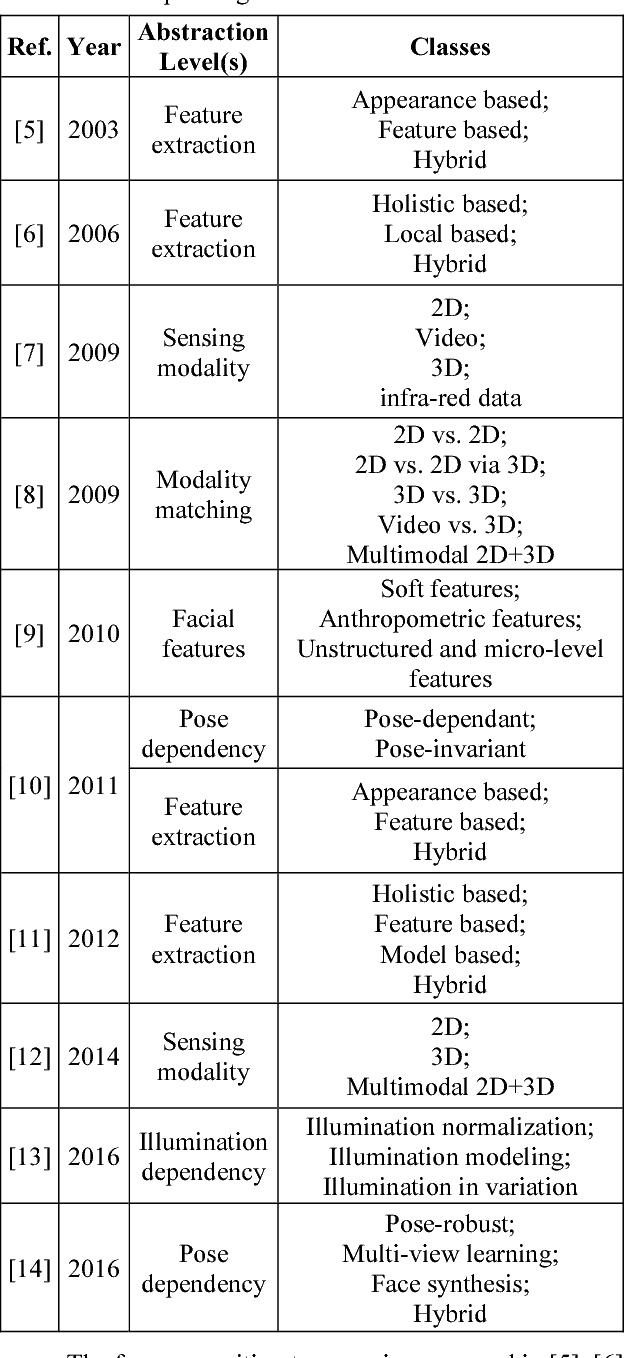
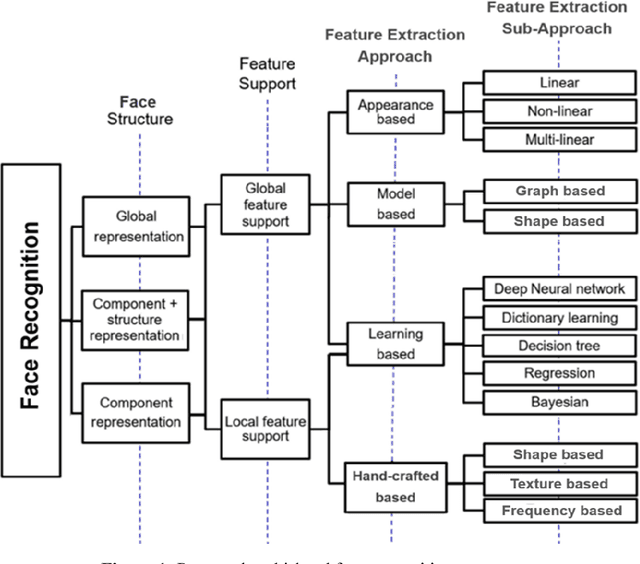

In a world where security issues have been gaining growing importance, face recognition systems have attracted increasing attention in multiple application areas, ranging from forensics and surveillance to commerce and entertainment. To help understanding the landscape and abstraction levels relevant for face recognition systems, face recognition taxonomies allow a deeper dissection and comparison of the existing solutions. This paper proposes a new, more encompassing and richer multi-level face recognition taxonomy, facilitating the organization and categorization of available and emerging face recognition solutions; this taxonomy may also guide researchers in the development of more efficient face recognition solutions. The proposed multi-level taxonomy considers levels related to the face structure, feature support and feature extraction approach. Following the proposed taxonomy, a comprehensive survey of representative face recognition solutions is presented. The paper concludes with a discussion on current algorithmic and application related challenges which may define future research directions for face recognition.
A Double-Deep Spatio-Angular Learning Framework for Light Field based Face Recognition
Oct 09, 2018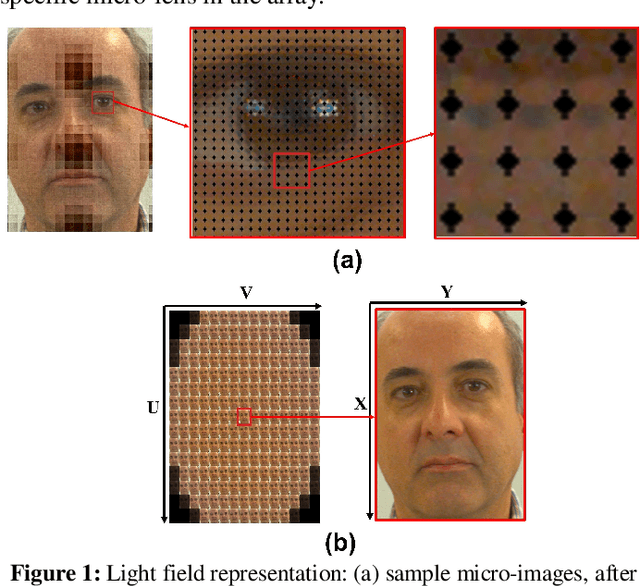

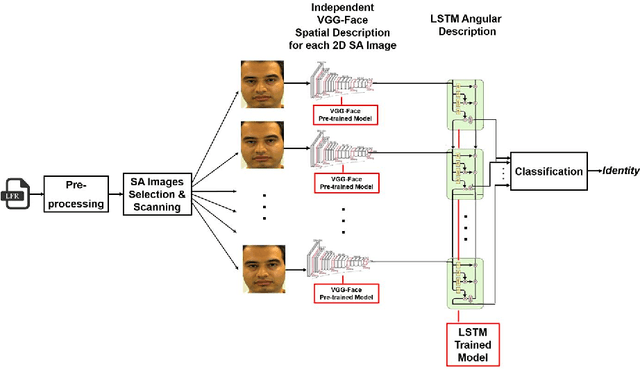

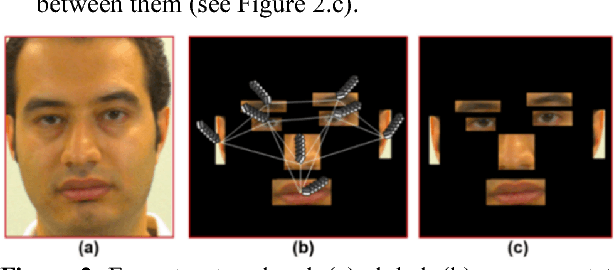
Face recognition has attracted increasing attention due to its wide range of applications, but it is still challenging when facing large variations in the biometric data characteristics. Lenslet light field cameras have recently come into prominence to capture rich spatio-angular information, thus offering new possibilities for advanced biometric recognition systems. This paper proposes a double-deep spatio-angular learning framework for light field based face recognition, which is able to learn both texture and angular dynamics in sequence using convolutional representations; this is a novel recognition framework that has never been proposed before for either face recognition or any other visual recognition task. The proposed double-deep learning framework includes a long short-term memory (LSTM) recurrent network whose inputs are VGG-Face descriptions that are computed using a VGG-Very-Deep-16 convolutional neural network (CNN). The VGG-16 network uses different face viewpoints rendered from a full light field image, which are organised as a pseudo-video sequence. A comprehensive set of experiments has been conducted with the IST-EURECOM light field face database, for varied and challenging recognition tasks. Results show that the proposed framework achieves superior face recognition performance when compared to the state-of-the-art.