 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Privacy: Temporally Consistent Video Anonymization via Token Pruning for Privacy Preserving Action Recognition
Mar 27, 2026Recent advances in large-scale video models have significantly improved video understanding across domains such as surveillance, healthcare, and entertainment. However, these models also amplify privacy risks by encoding sensitive attributes, including facial identity, race, and gender. While image anonymization has been extensively studied, video anonymization remains relatively underexplored, even though modern video models can leverage spatiotemporal motion patterns as biometric identifiers. To address this challenge, we propose a novel attention-driven spatiotemporal video anonymization framework based on systematic disentanglement of utility and privacy features. Our key insight is that attention mechanisms in Vision Transformers (ViTs) can be explicitly structured to separate action-relevant information from privacy-sensitive content. Building on this insight, we introduce two task-specific classification tokens, an action CLS token and a privacy CLS token, that learn complementary representations within a shared Transformer backbone. We contrast their attention distributions to compute a utility-privacy score for each spatiotemporal tubelet, and keep the top-k tubelets with the highest scores. This selectively prunes tubelets dominated by privacy cues while preserving those most critical for action recognition. Extensive experiments demonstrate that our approach maintains action recognition performance comparable to models trained on raw videos, while substantially reducing privacy leakage. These results indicate that attention-driven spatiotemporal pruning offers an effective and principled solution for privacy-preserving video analytics.
Only Whats Necessary: Pareto Optimal Data Minimization for Privacy Preserving Video Anomaly Detection
Mar 27, 2026Video anomaly detection (VAD) systems are increasingly deployed in safety critical environments and require a large amount of data for accurate detection. However, such data may contain personally identifiable information (PII), including facial cues and sensitive demographic attributes, creating compliance challenges under the EU General Data Protection Regulation (GDPR). In particular, GDPR requires that personal data be limited to what is strictly necessary for a specified processing purpose. To address this, we introduce Only What's Necessary, a privacy-by-design framework for VAD that explicitly controls the amount and type of visual information exposed to the detection pipeline. The framework combines breadth based and depth based data minimization mechanisms to suppress PII while preserving cues relevant to anomaly detection. We evaluate a range of minimization configurations by feeding the minimized videos to both a VAD model and a privacy inference model. We employ two ranking based methods, along with Pareto analysis, to characterize the resulting trade off between privacy and utility. From the non-dominated frontier, we identify sweet spot operating points that minimize personal data exposure with limited degradation in detection performance. Extensive experiments on publicly available datasets demonstrate the effectiveness of the proposed framework.
A Hyperbolic Perspective on Hierarchical Structure in Object-Centric Scene Representations
Mar 14, 2026Slot attention has emerged as a powerful framework for unsupervised object-centric learning, decomposing visual scenes into a small set of compact vector representations called \emph{slots}, each capturing a distinct region or object. However, these slots are learned in Euclidean space, which provides no geometric inductive bias for the hierarchical relationships that naturally structure visual scenes. In this work, we propose a simple post-hoc pipeline to project Euclidean slot embeddings onto the Lorentz hyperboloid of hyperbolic space, without modifying the underlying training pipeline. We construct five-level visual hierarchies directly from slot attention masks and analyse whether hyperbolic geometry reveals latent hierarchical structure that remains invisible in Euclidean space. Integrating our pipeline with SPOT (images), VideoSAUR (video), and SlotContrast (video), We find that hyperbolic projection exposes a consistent scene-level to object-level organisation, where coarse slots occupy greater manifold depth than fine slots, which is absent in Euclidean space. We further identify a "curvature--task tradeoff": low curvature ($c{=}0.2$) matches or outperforms Euclidean on parent slot retrieval, while moderate curvature ($c{=}0.5$) achieves better inter-level separation. Together, these findings suggest that slot representations already encode latent hierarchy that hyperbolic geometry reveals, motivating end-to-end hyperbolic training as a natural next step. Code and models are available at \href{https://github.com/NeeluMadan/HHS}{github.com/NeeluMadan/HHS}.
SOVABench: A Vehicle Surveillance Action Retrieval Benchmark for Multimodal Large Language Models
Jan 08, 2026Automatic identification of events and recurrent behavior analysis are critical for video surveillance. However, most existing content-based video retrieval benchmarks focus on scene-level similarity and do not evaluate the action discrimination required in surveillance. To address this gap, we introduce SOVABench (Surveillance Opposite Vehicle Actions Benchmark), a real-world retrieval benchmark built from surveillance footage and centered on vehicle-related actions. SOVABench defines two evaluation protocols (inter-pair and intra-pair) to assess cross-action discrimination and temporal direction understanding. Although action distinctions are generally intuitive for human observers, our experiments show that they remain challenging for state-of-the-art vision and multimodal models. Leveraging the visual reasoning and instruction-following capabilities of Multimodal Large Language Models (MLLMs), we present a training-free framework for producing interpretable embeddings from MLLM-generated descriptions for both images and videos. The framework achieves strong performance on SOVABench as well as on several spatial and counting benchmarks where contrastive Vision-Language Models often fail. The code, annotations, and instructions to construct the benchmark are publicly available.
PrismVAU: Prompt-Refined Inference System for Multimodal Video Anomaly Understanding
Jan 07, 2026Video Anomaly Understanding (VAU) extends traditional Video Anomaly Detection (VAD) by not only localizing anomalies but also describing and reasoning about their context. Existing VAU approaches often rely on fine-tuned multimodal large language models (MLLMs) or external modules such as video captioners, which introduce costly annotations, complex training pipelines, and high inference overhead. In this work, we introduce PrismVAU, a lightweight yet effective system for real-time VAU that leverages a single off-the-shelf MLLM for anomaly scoring, explanation, and prompt optimization. PrismVAU operates in two complementary stages: (1) a coarse anomaly scoring module that computes frame-level anomaly scores via similarity to textual anchors, and (2) an MLLM-based refinement module that contextualizes anomalies through system and user prompts. Both textual anchors and prompts are optimized with a weakly supervised Automatic Prompt Engineering (APE) framework. Extensive experiments on standard VAD benchmarks demonstrate that PrismVAU delivers competitive detection performance and interpretable anomaly explanations -- without relying on instruction tuning, frame-level annotations, and external modules or dense processing -- making it an efficient and practical solution for real-world applications.
Balancing Privacy and Action Performance: A Penalty-Driven Approach to Image Anonymization
Apr 19, 2025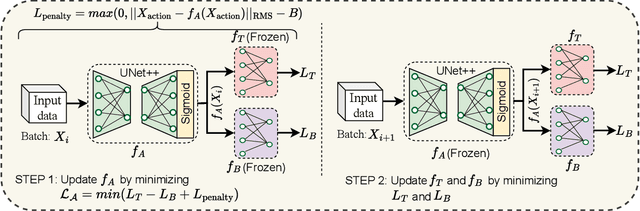
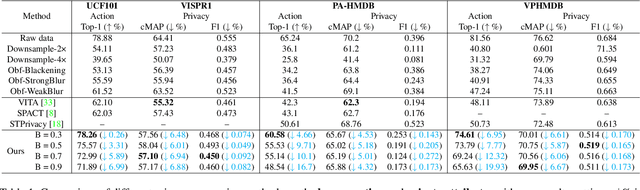
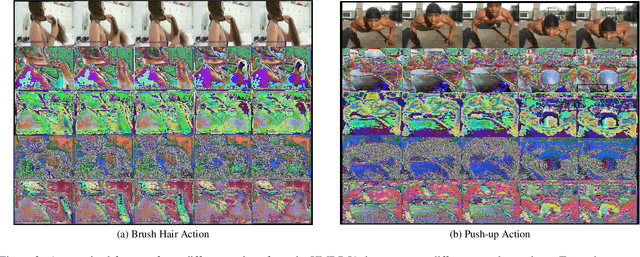

The rapid development of video surveillance systems for object detection, tracking, activity recognition, and anomaly detection has revolutionized our day-to-day lives while setting alarms for privacy concerns. It isn't easy to strike a balance between visual privacy and action recognition performance in most computer vision models. Is it possible to safeguard privacy without sacrificing performance? It poses a formidable challenge, as even minor privacy enhancements can lead to substantial performance degradation. To address this challenge, we propose a privacy-preserving image anonymization technique that optimizes the anonymizer using penalties from the utility branch, ensuring improved action recognition performance while minimally affecting privacy leakage. This approach addresses the trade-off between minimizing privacy leakage and maintaining high action performance. The proposed approach is primarily designed to align with the regulatory standards of the EU AI Act and GDPR, ensuring the protection of personally identifiable information while maintaining action performance. To the best of our knowledge, we are the first to introduce a feature-based penalty scheme that exclusively controls the action features, allowing freedom to anonymize private attributes. Extensive experiments were conducted to validate the effectiveness of the proposed method. The results demonstrate that applying a penalty to anonymizer from utility branch enhances action performance while maintaining nearly consistent privacy leakage across different penalty settings.
Video Anomaly Detection with Contours - A Study
Mar 25, 2025In Pose-based Video Anomaly Detection prior art is rooted on the assumption that abnormal events can be mostly regarded as a result of uncommon human behavior. Opposed to utilizing skeleton representations of humans, however, we investigate the potential of learning recurrent motion patterns of normal human behavior using 2D contours. Keeping all advantages of pose-based methods, such as increased object anonymization, the shift from human skeletons to contours is hypothesized to leave the opportunity to cover more object categories open for future research. We propose formulating the problem as a regression and a classification task, and additionally explore two distinct data representation techniques for contours. To further reduce the computational complexity of Pose-based Video Anomaly Detection solutions, all methods in this study are based on shallow Neural Networks from the field of Deep Learning, and evaluated on the three most prominent benchmark datasets within Video Anomaly Detection and their human-related counterparts, totaling six datasets. Our results indicate that this novel perspective on Pose-based Video Anomaly Detection marks a promising direction for future research.
Machine Unlearning in Hyperbolic vs. Euclidean Multimodal Contrastive Learning: Adapting Alignment Calibration to MERU
Mar 19, 2025



Machine unlearning methods have become increasingly important for selective concept removal in large pre-trained models. While recent work has explored unlearning in Euclidean contrastive vision-language models, the effectiveness of concept removal in hyperbolic spaces remains unexplored. This paper investigates machine unlearning in hyperbolic contrastive learning by adapting Alignment Calibration to MERU, a model that embeds images and text in hyperbolic space to better capture semantic hierarchies. Through systematic experiments and ablation studies, we demonstrate that hyperbolic geometry offers distinct advantages for concept removal, achieving near perfect forgetting with reasonable performance on retained concepts, particularly when scaling to multiple concept removal. Our approach introduces hyperbolic-specific components including entailment calibration and norm regularization that leverage the unique properties of hyperbolic space. Comparative analysis with Euclidean models reveals fundamental differences in unlearning dynamics, with hyperbolic unlearning reorganizing the semantic hierarchy while Euclidean approaches merely disconnect cross-modal associations. These findings not only advance machine unlearning techniques but also provide insights into the geometric properties that influence concept representation and removal in multimodal models. Source code available at https://github.com/alex-pv01/HAC
YOLO11-JDE: Fast and Accurate Multi-Object Tracking with Self-Supervised Re-ID
Jan 23, 2025We introduce YOLO11-JDE, a fast and accurate multi-object tracking (MOT) solution that combines real-time object detection with self-supervised Re-Identification (Re-ID). By incorporating a dedicated Re-ID branch into YOLO11s, our model performs Joint Detection and Embedding (JDE), generating appearance features for each detection. The Re-ID branch is trained in a fully self-supervised setting while simultaneously training for detection, eliminating the need for costly identity-labeled datasets. The triplet loss, with hard positive and semi-hard negative mining strategies, is used for learning discriminative embeddings. Data association is enhanced with a custom tracking implementation that successfully integrates motion, appearance, and location cues. YOLO11-JDE achieves competitive results on MOT17 and MOT20 benchmarks, surpassing existing JDE methods in terms of FPS and using up to ten times fewer parameters. Thus, making our method a highly attractive solution for real-world applications.
Verifying Machine Unlearning with Explainable AI
Nov 20, 2024
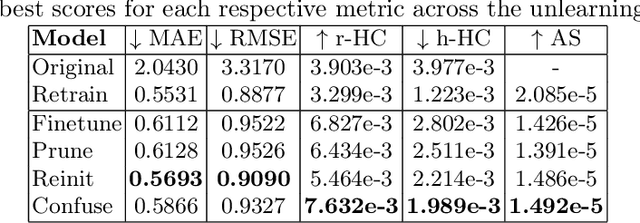
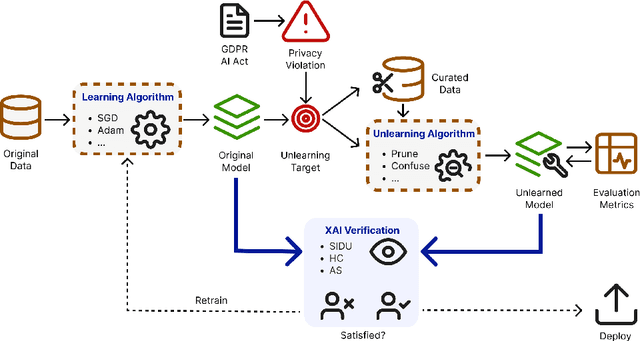

We investigate the effectiveness of Explainable AI (XAI) in verifying Machine Unlearning (MU) within the context of harbor front monitoring, focusing on data privacy and regulatory compliance. With the increasing need to adhere to privacy legislation such as the General Data Protection Regulation (GDPR), traditional methods of retraining ML models for data deletions prove impractical due to their complexity and resource demands. MU offers a solution by enabling models to selectively forget specific learned patterns without full retraining. We explore various removal techniques, including data relabeling, and model perturbation. Then, we leverage attribution-based XAI to discuss the effects of unlearning on model performance. Our proof-of-concept introduces feature importance as an innovative verification step for MU, expanding beyond traditional metrics and demonstrating techniques' ability to reduce reliance on undesired patterns. Additionally, we propose two novel XAI-based metrics, Heatmap Coverage (HC) and Attention Shift (AS), to evaluate the effectiveness of these methods. This approach not only highlights how XAI can complement MU by providing effective verification, but also sets the stage for future research to enhance their joint integration.