 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning in Hyperbolic vs. Euclidean Multimodal Contrastive Learning: Adapting Alignment Calibration to MERU
Mar 19, 2025



Machine unlearning methods have become increasingly important for selective concept removal in large pre-trained models. While recent work has explored unlearning in Euclidean contrastive vision-language models, the effectiveness of concept removal in hyperbolic spaces remains unexplored. This paper investigates machine unlearning in hyperbolic contrastive learning by adapting Alignment Calibration to MERU, a model that embeds images and text in hyperbolic space to better capture semantic hierarchies. Through systematic experiments and ablation studies, we demonstrate that hyperbolic geometry offers distinct advantages for concept removal, achieving near perfect forgetting with reasonable performance on retained concepts, particularly when scaling to multiple concept removal. Our approach introduces hyperbolic-specific components including entailment calibration and norm regularization that leverage the unique properties of hyperbolic space. Comparative analysis with Euclidean models reveals fundamental differences in unlearning dynamics, with hyperbolic unlearning reorganizing the semantic hierarchy while Euclidean approaches merely disconnect cross-modal associations. These findings not only advance machine unlearning techniques but also provide insights into the geometric properties that influence concept representation and removal in multimodal models. Source code available at https://github.com/alex-pv01/HAC
Verifying Machine Unlearning with Explainable AI
Nov 20, 2024
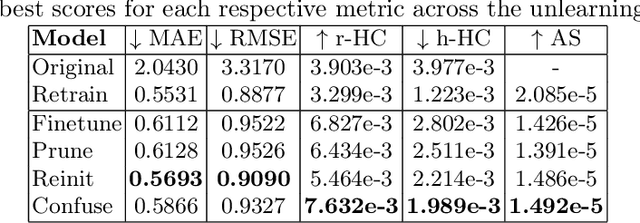
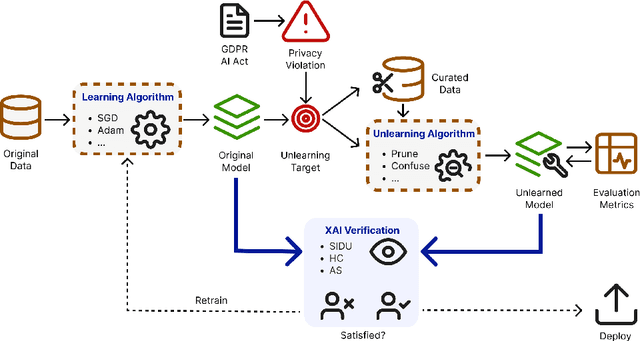

We investigate the effectiveness of Explainable AI (XAI) in verifying Machine Unlearning (MU) within the context of harbor front monitoring, focusing on data privacy and regulatory compliance. With the increasing need to adhere to privacy legislation such as the General Data Protection Regulation (GDPR), traditional methods of retraining ML models for data deletions prove impractical due to their complexity and resource demands. MU offers a solution by enabling models to selectively forget specific learned patterns without full retraining. We explore various removal techniques, including data relabeling, and model perturbation. Then, we leverage attribution-based XAI to discuss the effects of unlearning on model performance. Our proof-of-concept introduces feature importance as an innovative verification step for MU, expanding beyond traditional metrics and demonstrating techniques' ability to reduce reliance on undesired patterns. Additionally, we propose two novel XAI-based metrics, Heatmap Coverage (HC) and Attention Shift (AS), to evaluate the effectiveness of these methods. This approach not only highlights how XAI can complement MU by providing effective verification, but also sets the stage for future research to enhance their joint integration.